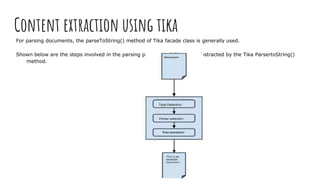
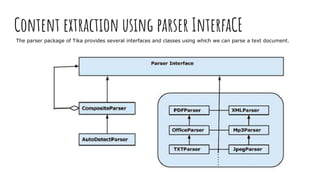
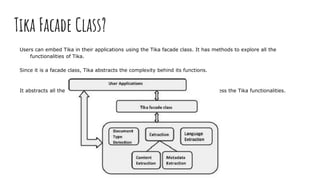
Apache Tika is a library for document type detection and content extraction from various file formats, utilizing a unified parser interface that encapsulates 83 specialized parser libraries. It enables applications like search engines and content management systems to efficiently extract data from diverse formats, offer metadata extraction, and support language detection. Users can integrate Tika functionalities into their applications via the Tika facade class, simplifying the process of content and metadata retrieval.








![Metadata class
Following are the methods of this class
1. add (Property property, String value)
2. add (String name, String value)
3. String get (Property property)
4. String get (String name)
5. Date getDate (Property property)
6. String[] getValues (Property property)
7. String[] getValues (String name)
8. String[] names()
9. set (Property property, Date date)
10. set(Property property, String[] values)](https://image.slidesharecdn.com/apachetika-170315051908/85/Apache-tika-10-320.jpg)