Downloaded 84 times













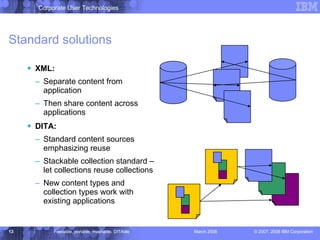

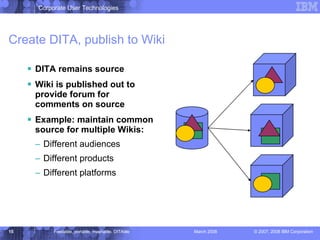
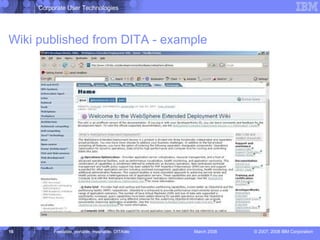
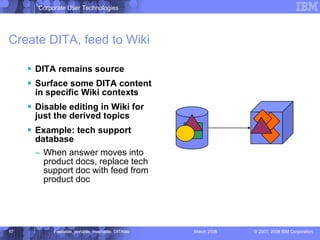





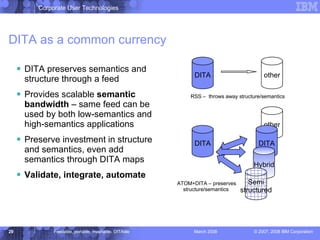
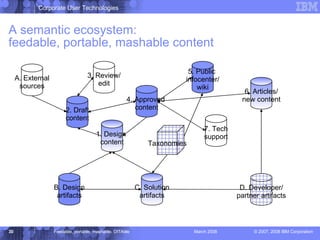
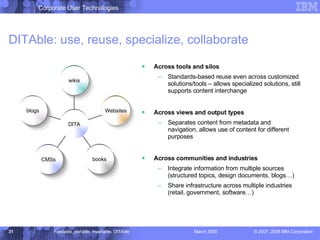






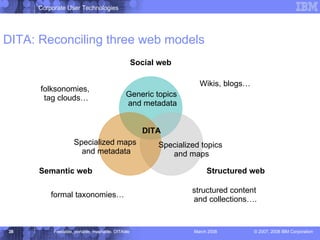

The document discusses the Darwin Information Typing Architecture (DITA) as an open standard for designing, authoring, and publishing modular information. It addresses the integration of DITA with Web 2.0 tools like wikis and mashups, highlighting the benefits of using structured content for better content management and collaboration. Additionally, it explores how DITA can enhance content reuse, reduce costs, and improve information accessibility across various platforms and applications.





































































































