Downloaded 88 times
![Apache Tika: 1 point Oh! Chris A. Mattmann NASA JPL/Univ. Southern California/ASF [email_address] November 9, 2011](https://image.slidesharecdn.com/mattmanntikaonepointoh-111111020556-phpapp01/75/Apache-Tika-1-point-Oh-1-2048.jpg)







































![Alright, I ’ll shut up now Any questions? THANK YOU! [email_address] [email_address] @chrismattmann on Twitter](https://image.slidesharecdn.com/mattmanntikaonepointoh-111111020556-phpapp01/75/Apache-Tika-1-point-Oh-55-2048.jpg)

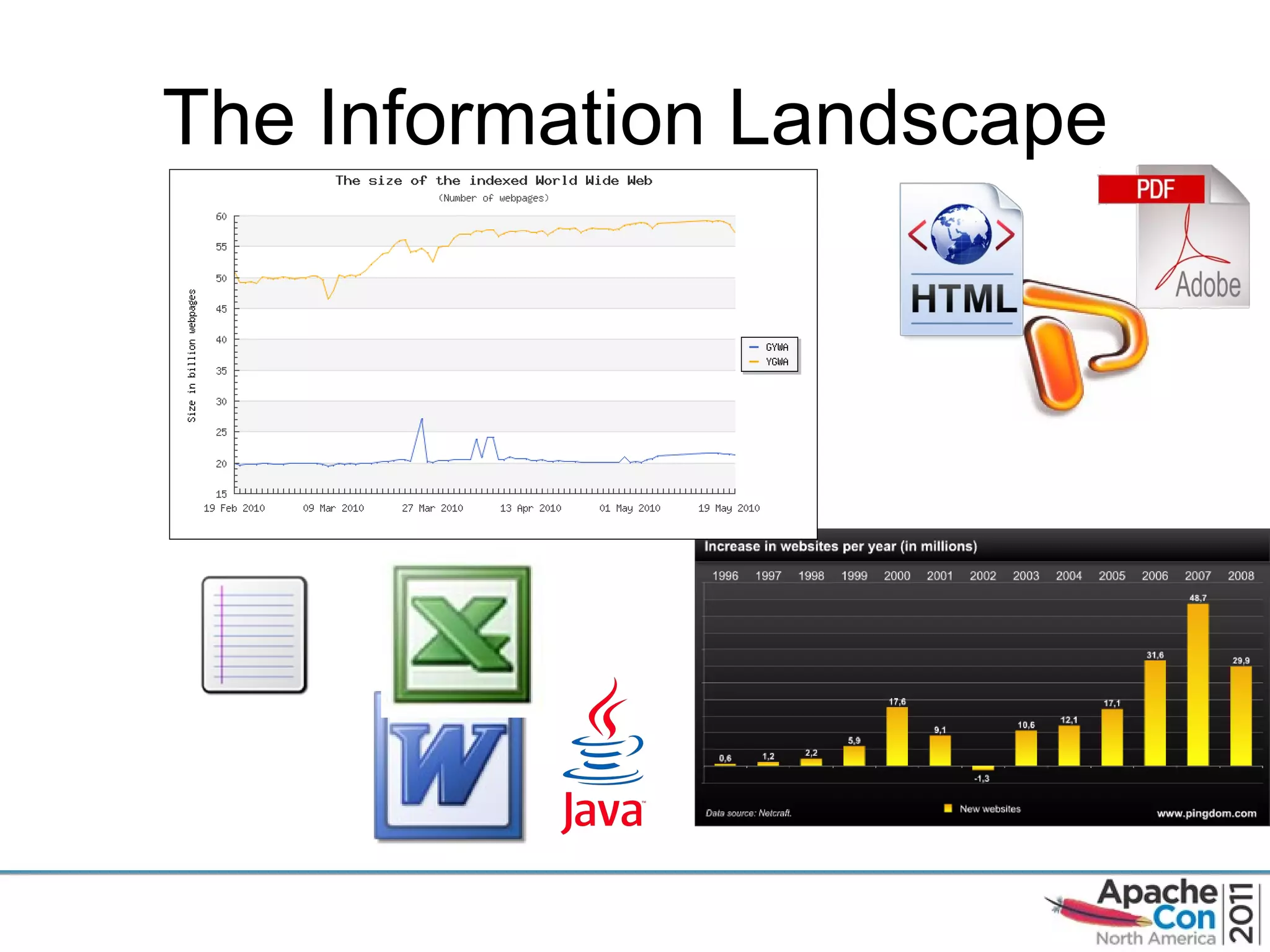
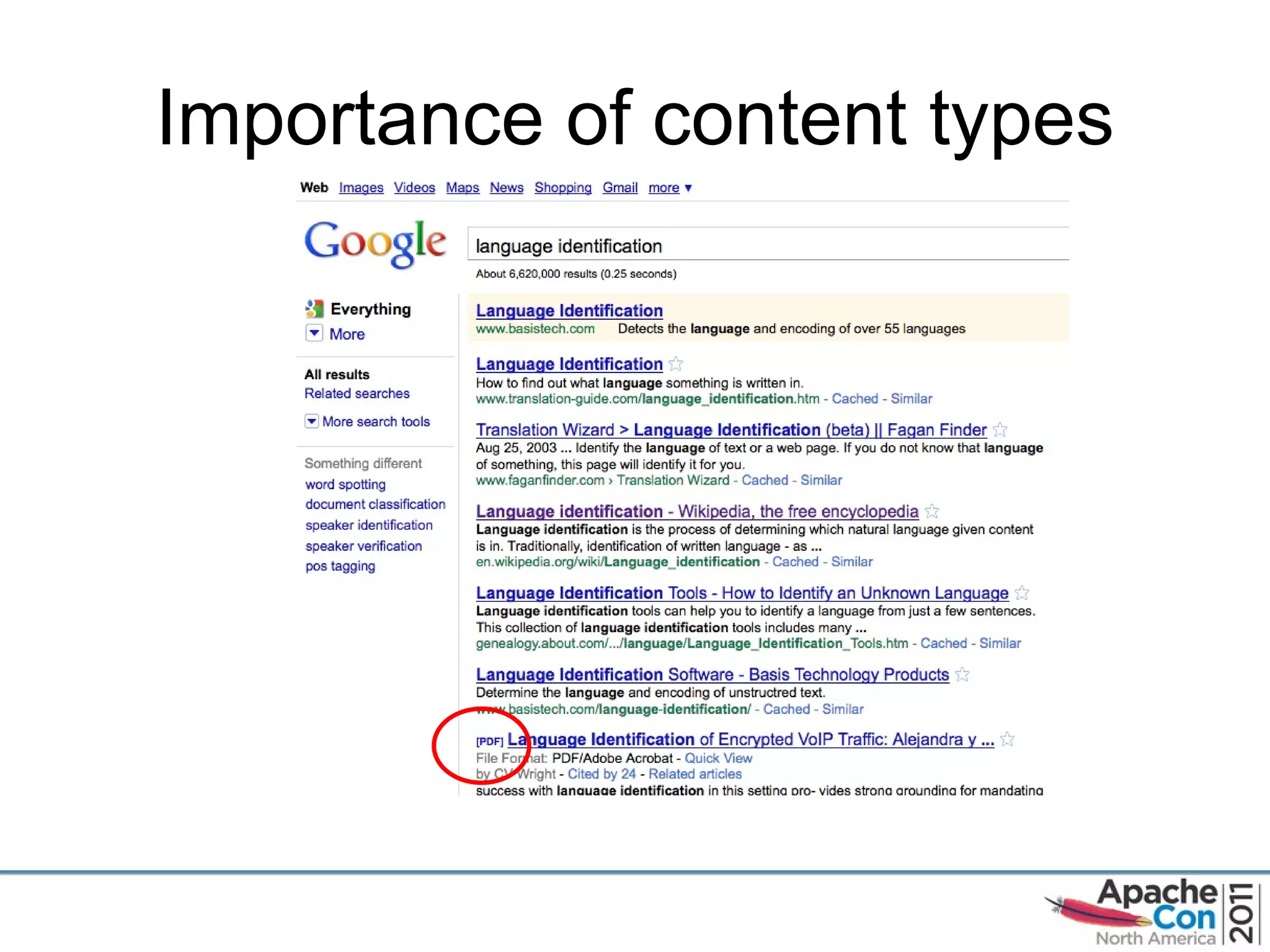
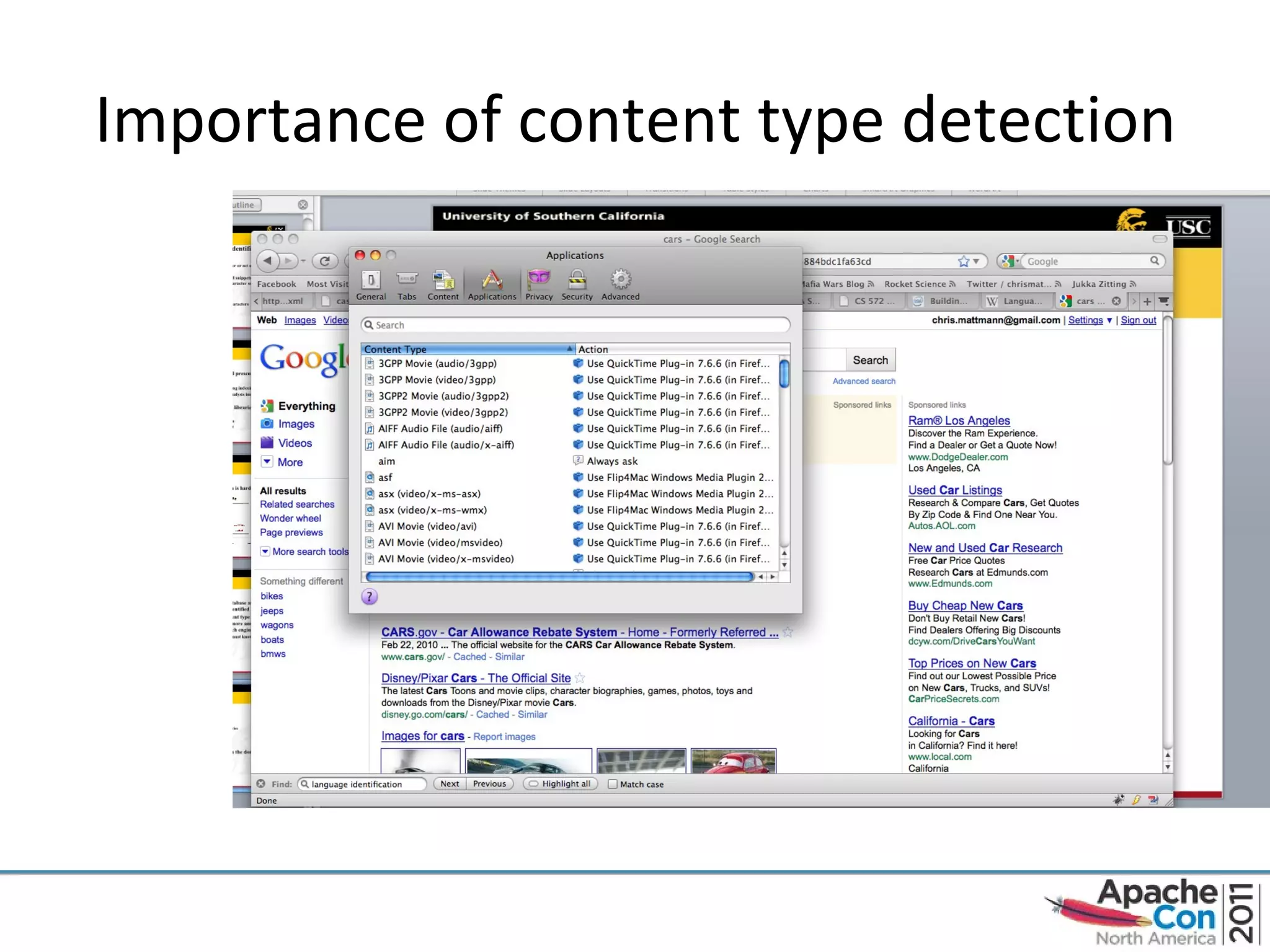
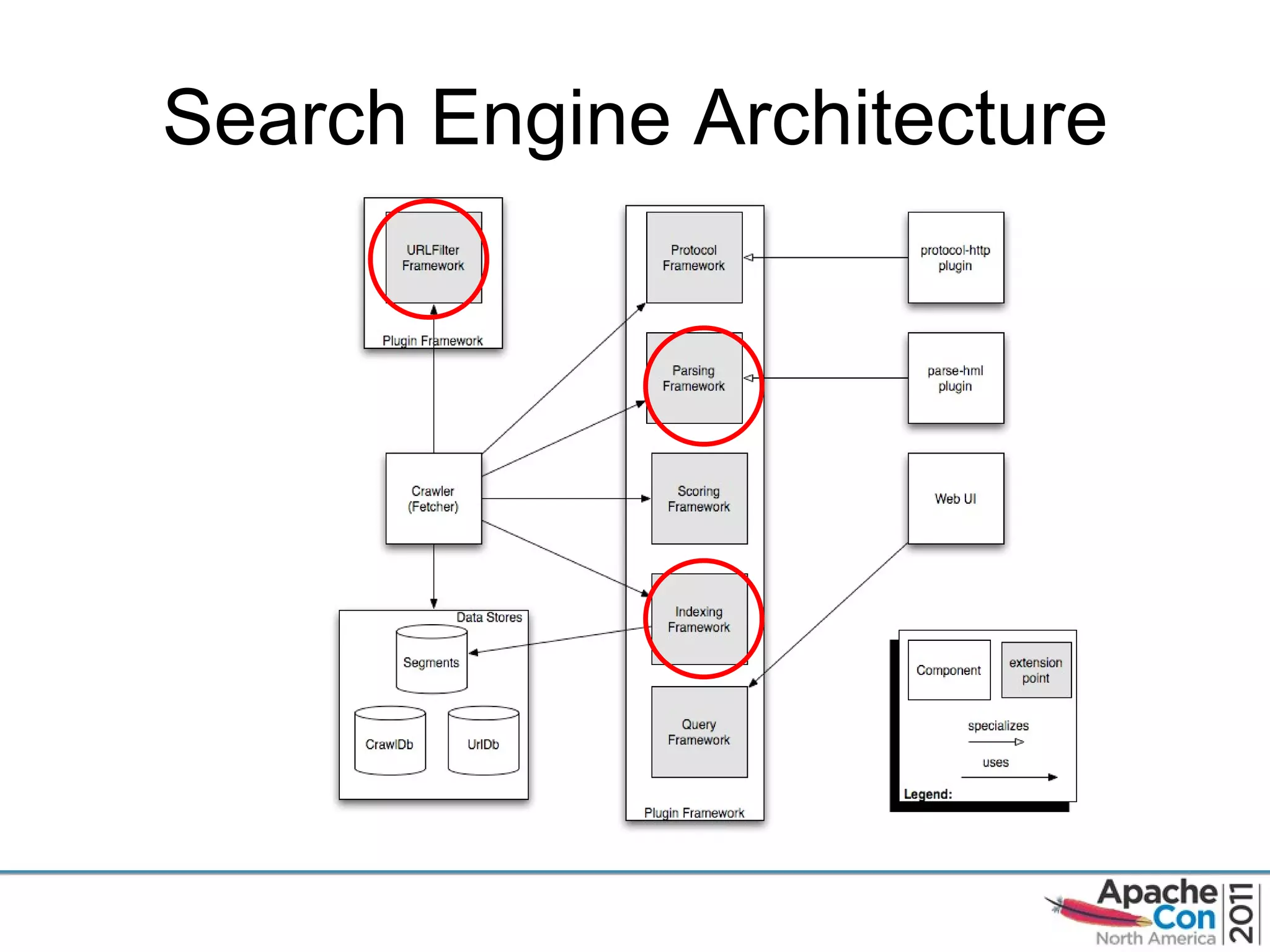
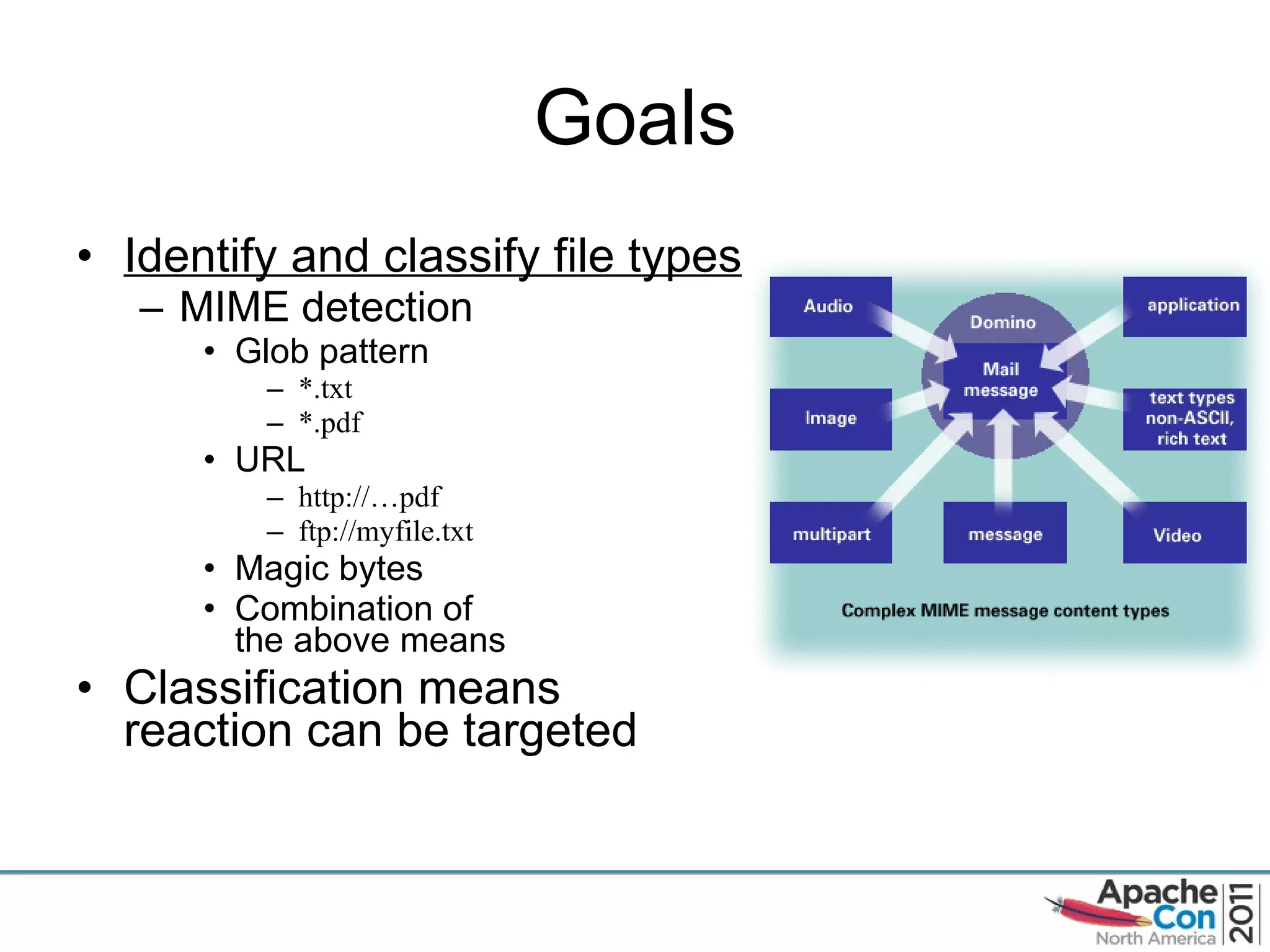
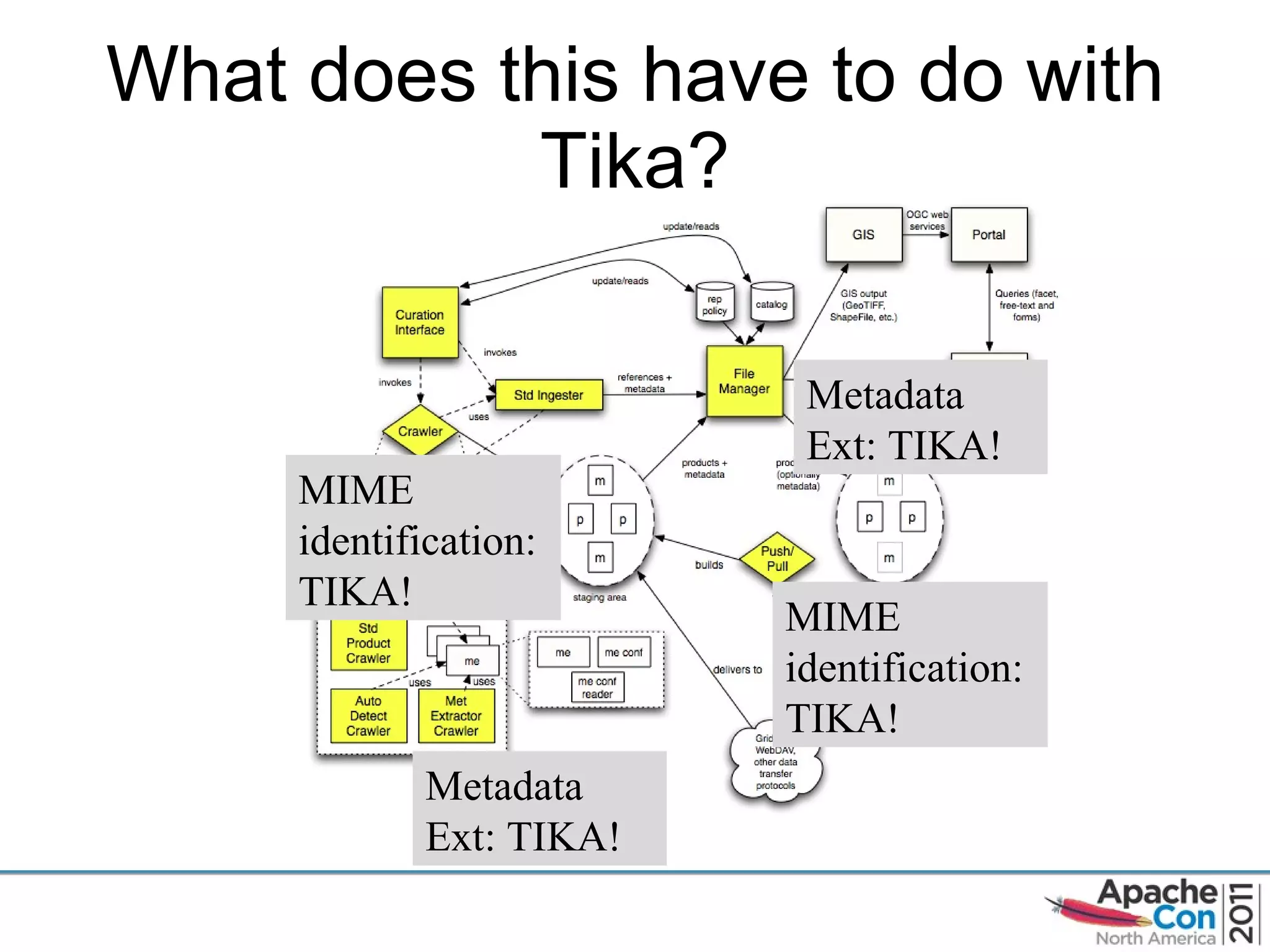
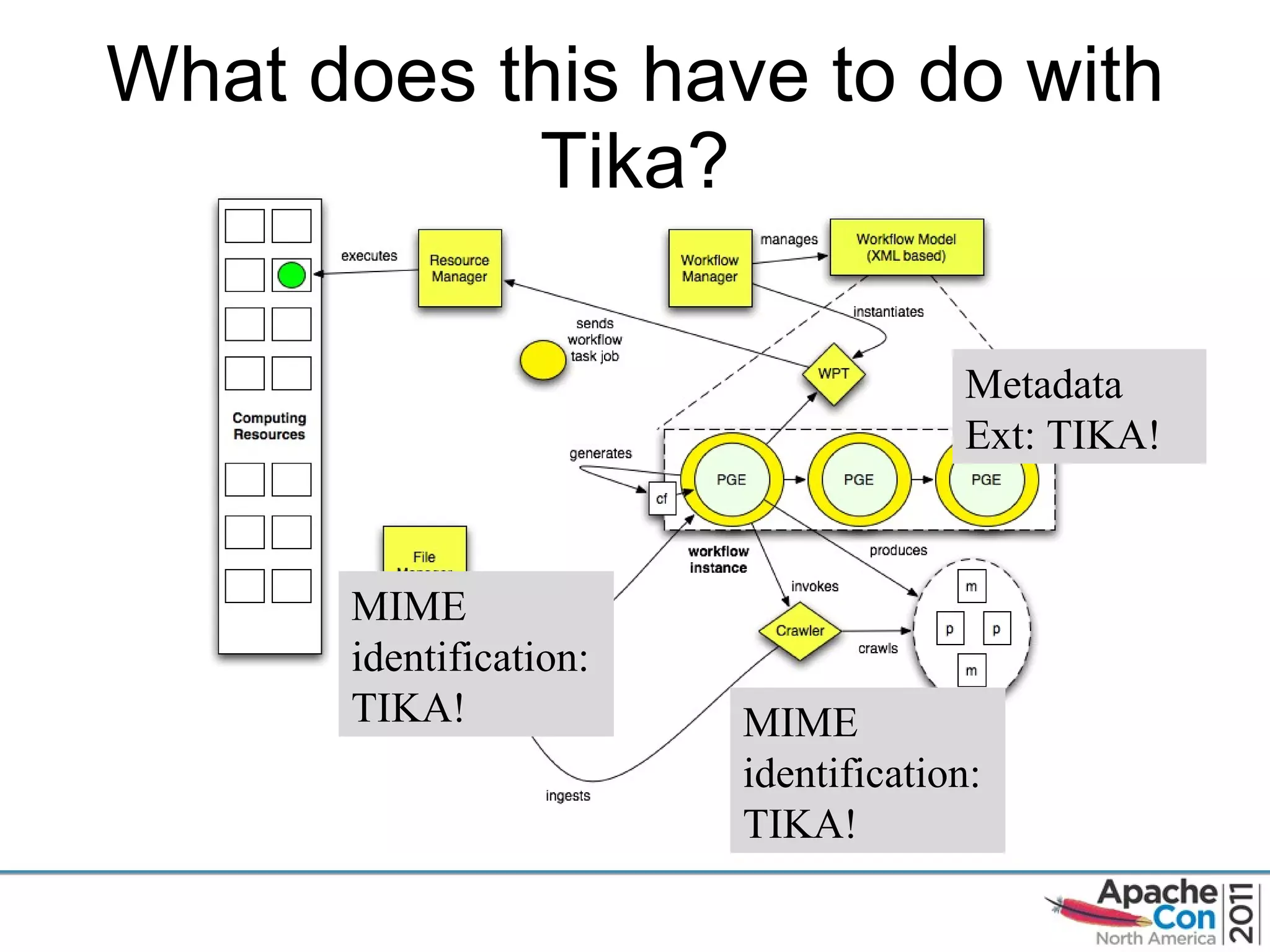
The document discusses Apache Tika, an open source content analysis and detection toolkit. It provides an overview of Tika's history and capabilities, including MIME type detection, language identification, and metadata extraction. It also describes how NASA uses Tika within its Earth science data systems to process large volumes of scientific data files in formats like HDF and netCDF.
































































































