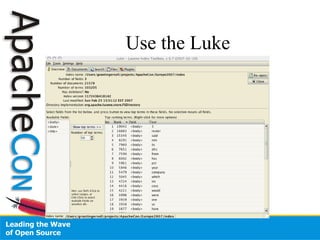
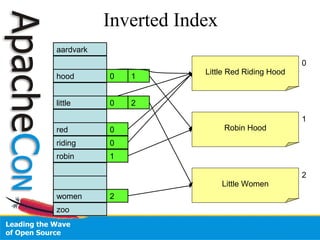
This document provides an agenda and overview for a one-day Lucene boot camp tutorial. The schedule includes sessions on introducing Lucene, indexing, analysis, searching, and performance. It also covers topics like indexing in Lucene, analyzing text, querying, sorting results, and optimizing search performance. The document seeks to help attendees understand Lucene's core capabilities through real examples, code, and data. It encourages attendees to ask questions.