Downloaded 11 times





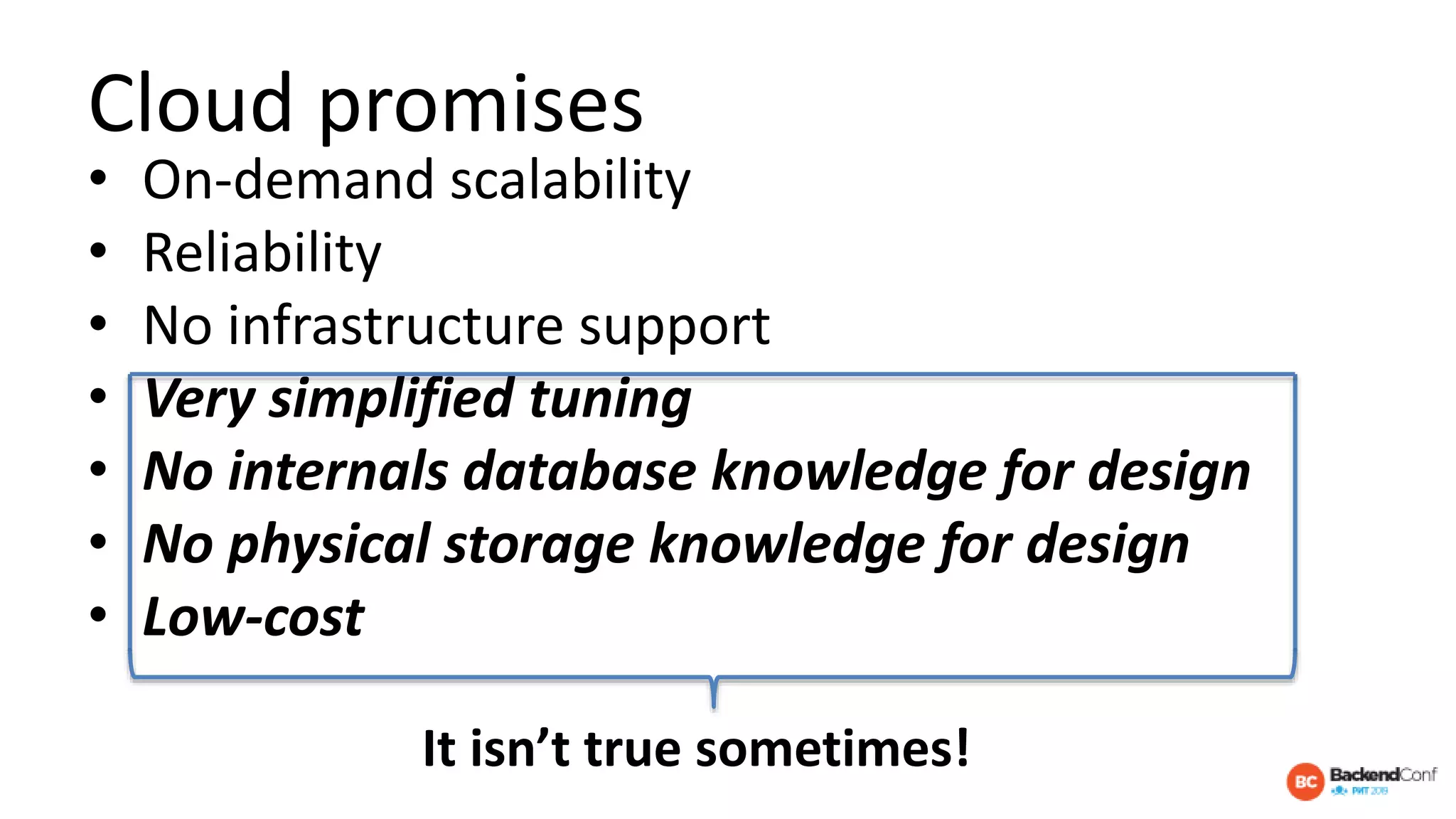






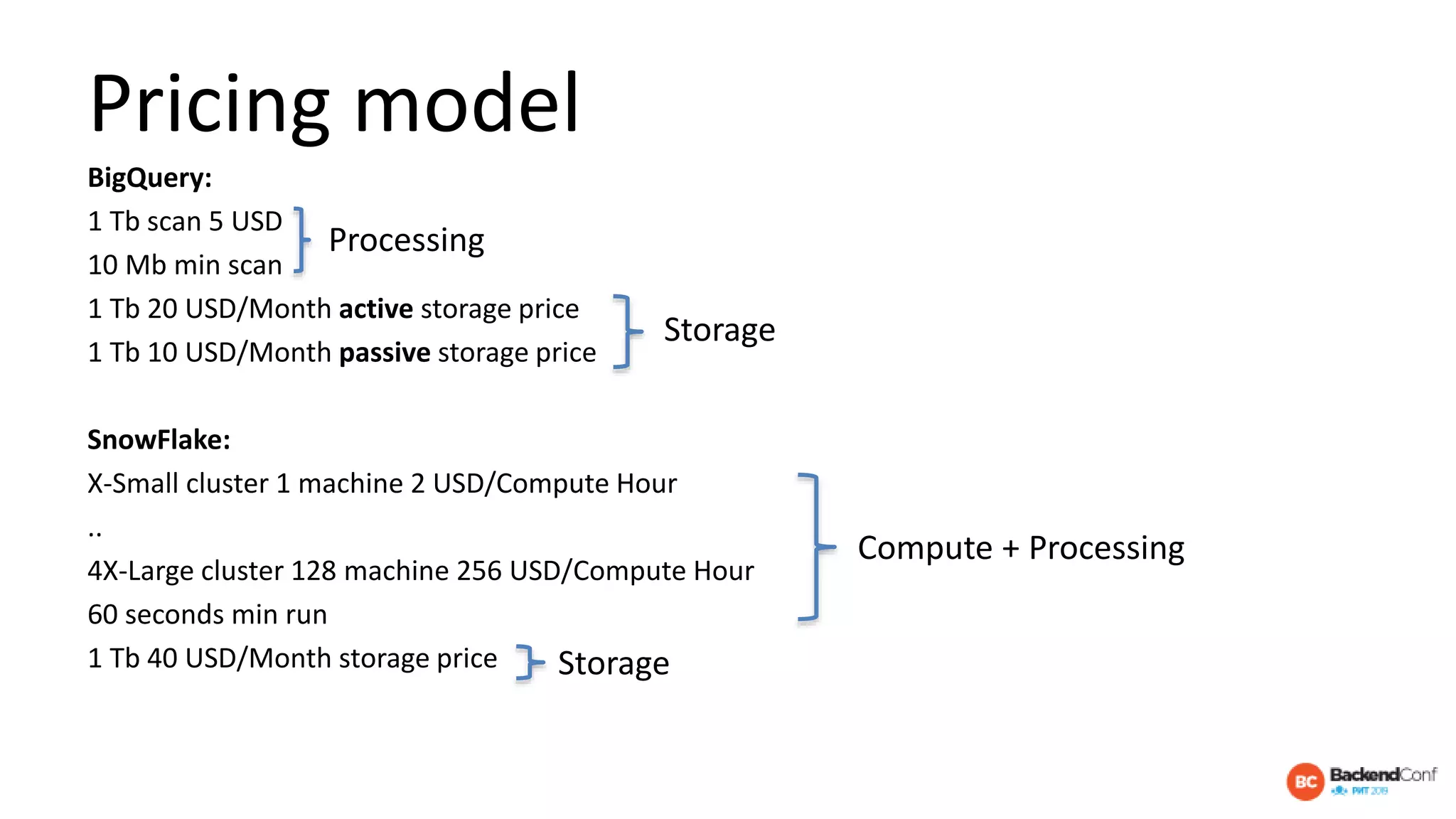
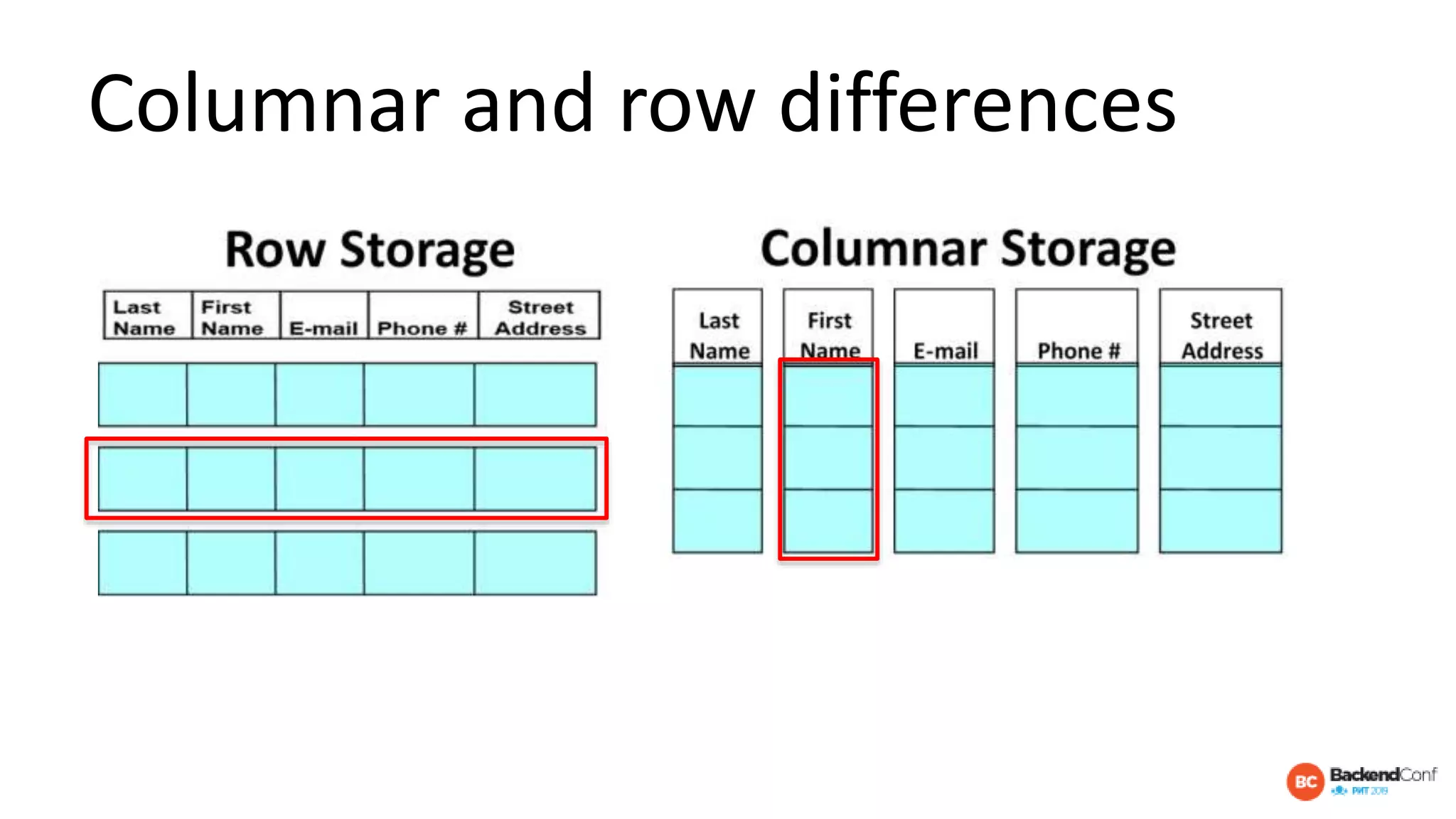




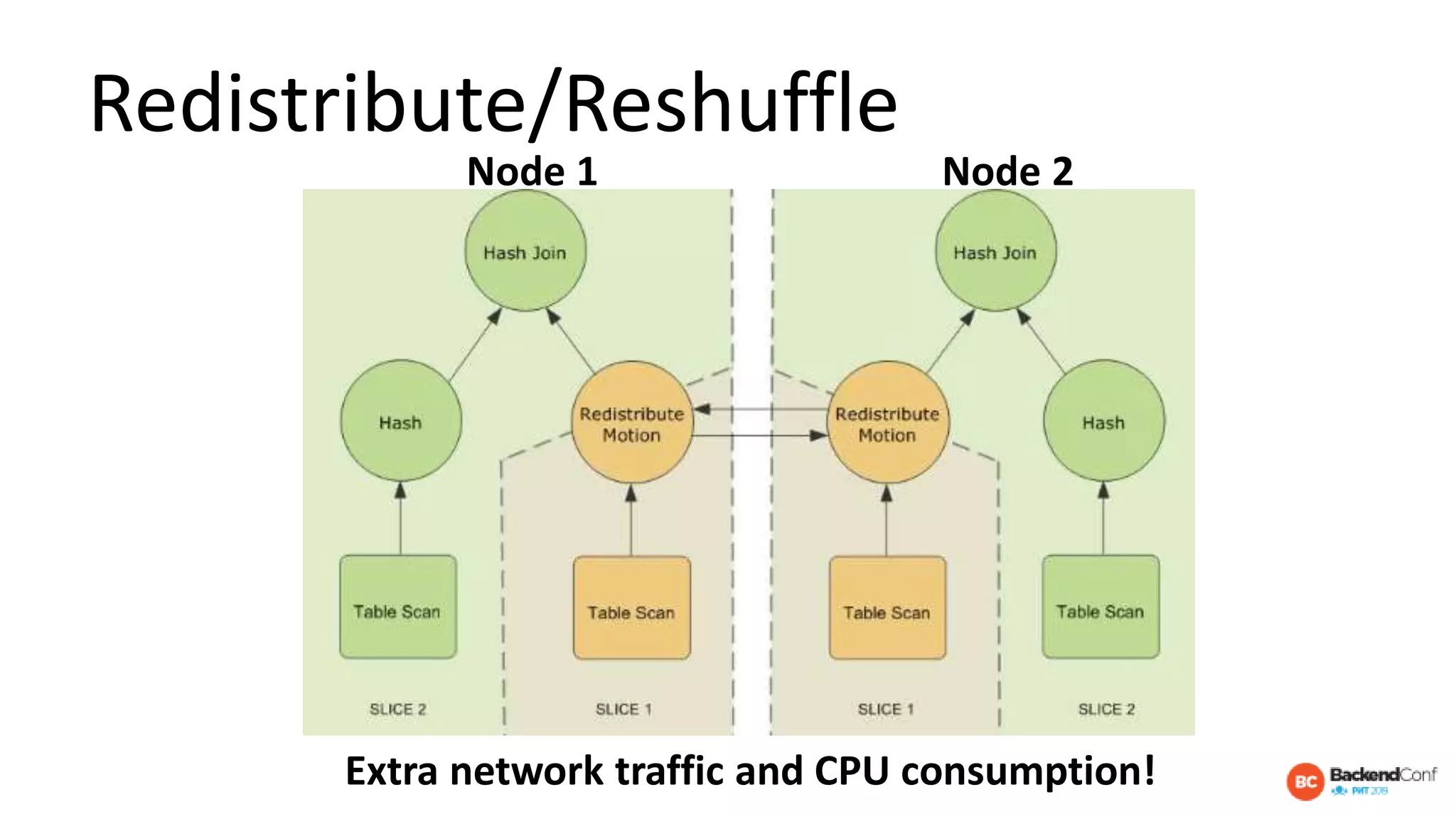


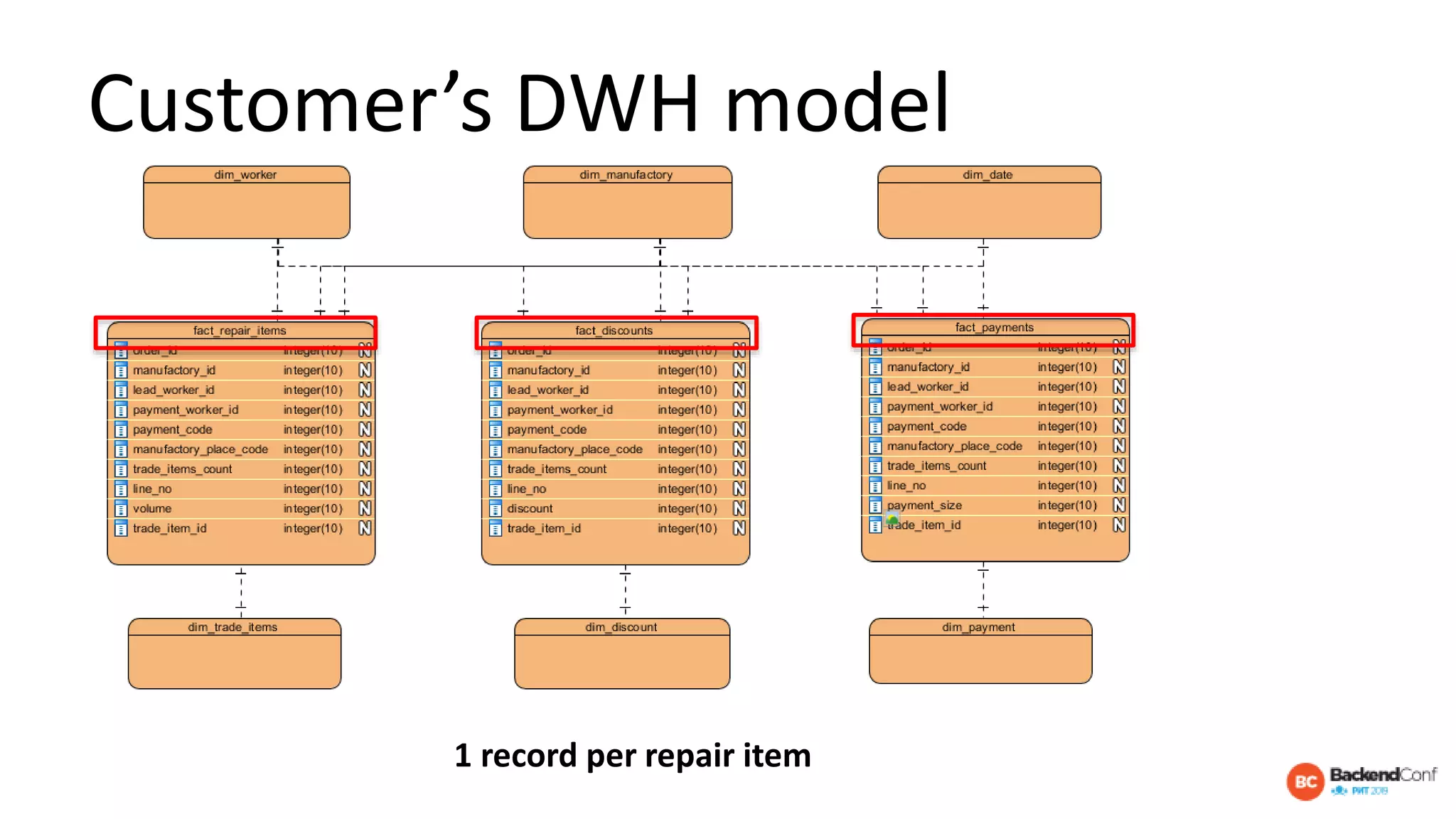

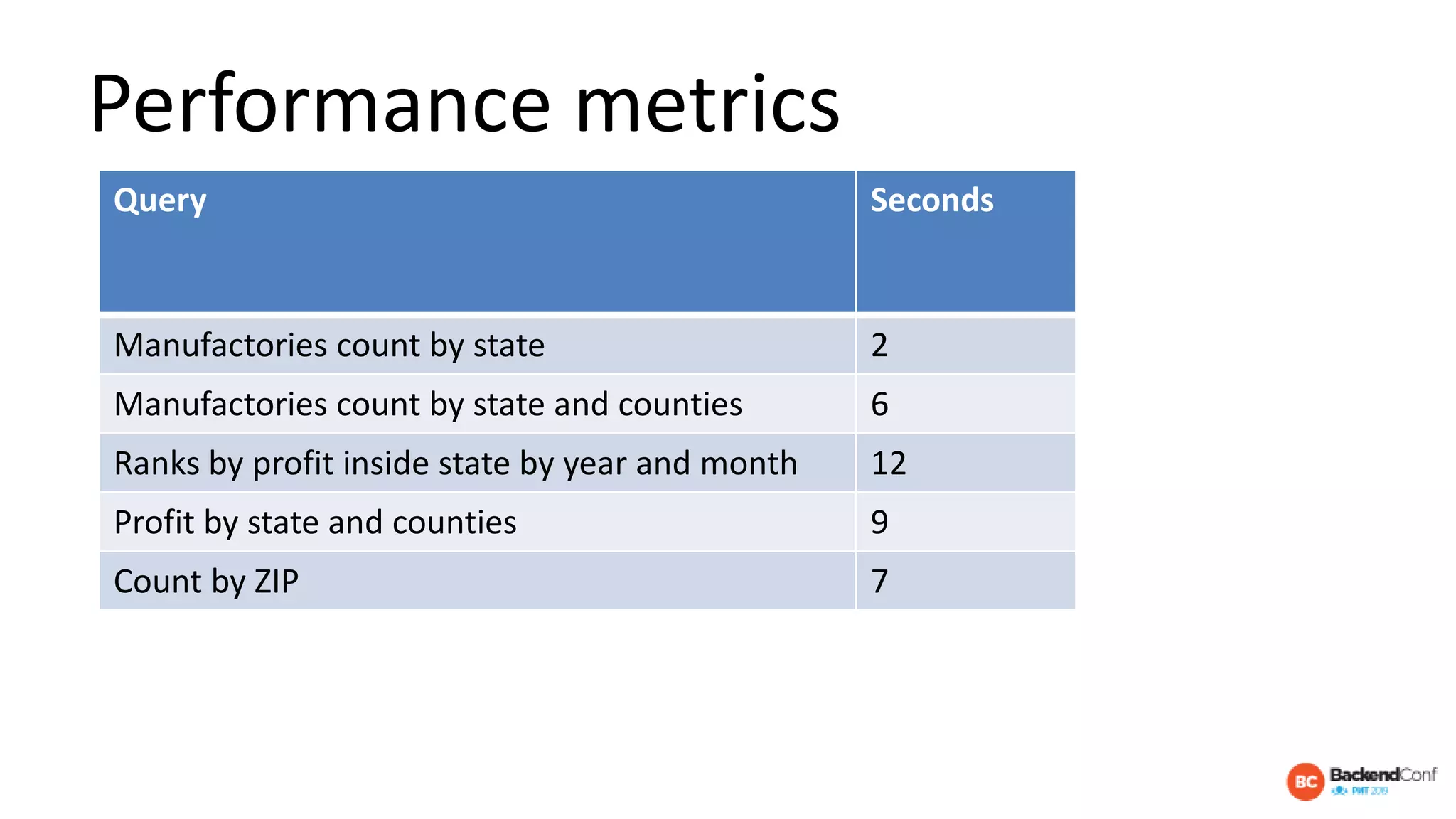

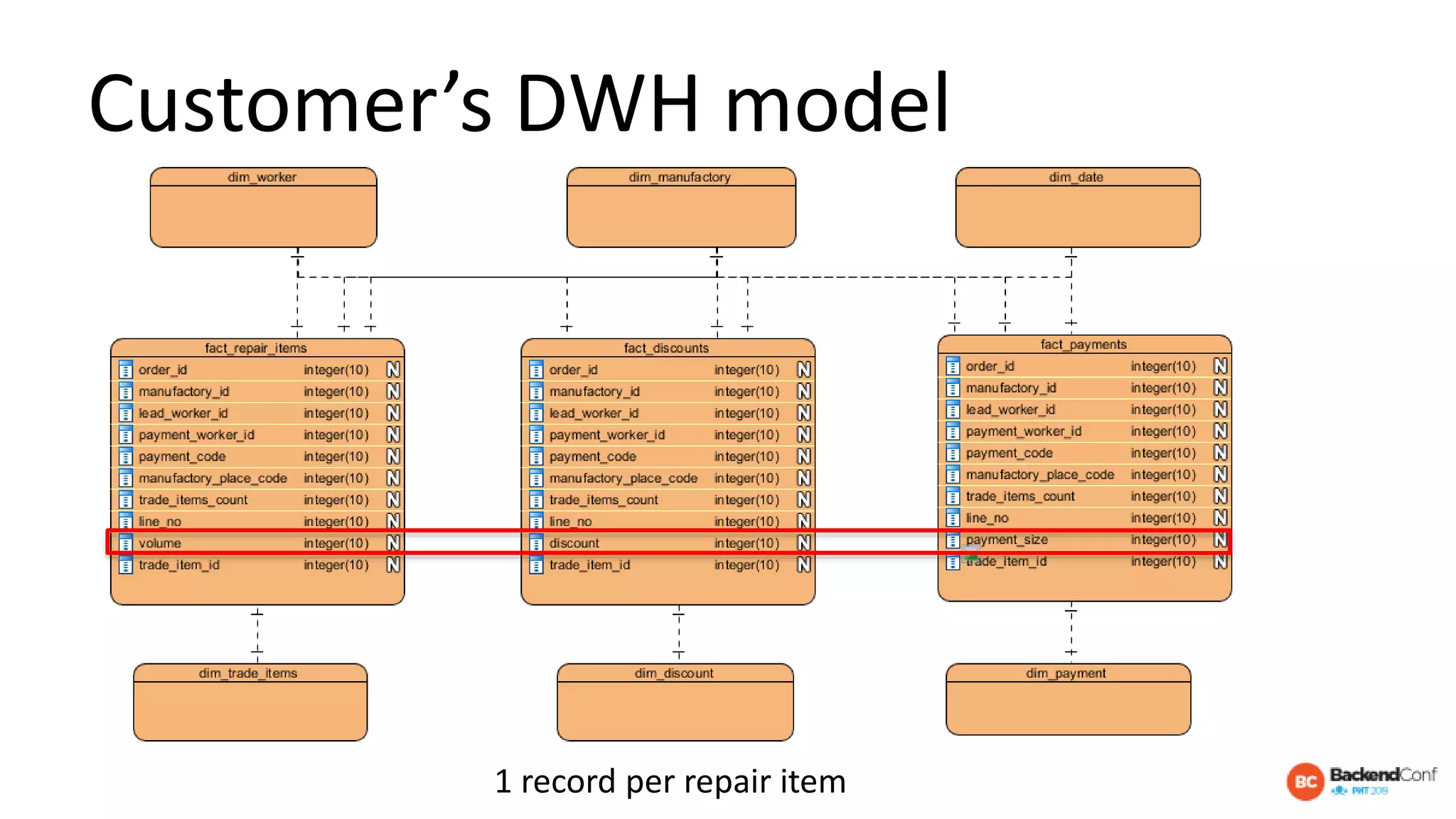
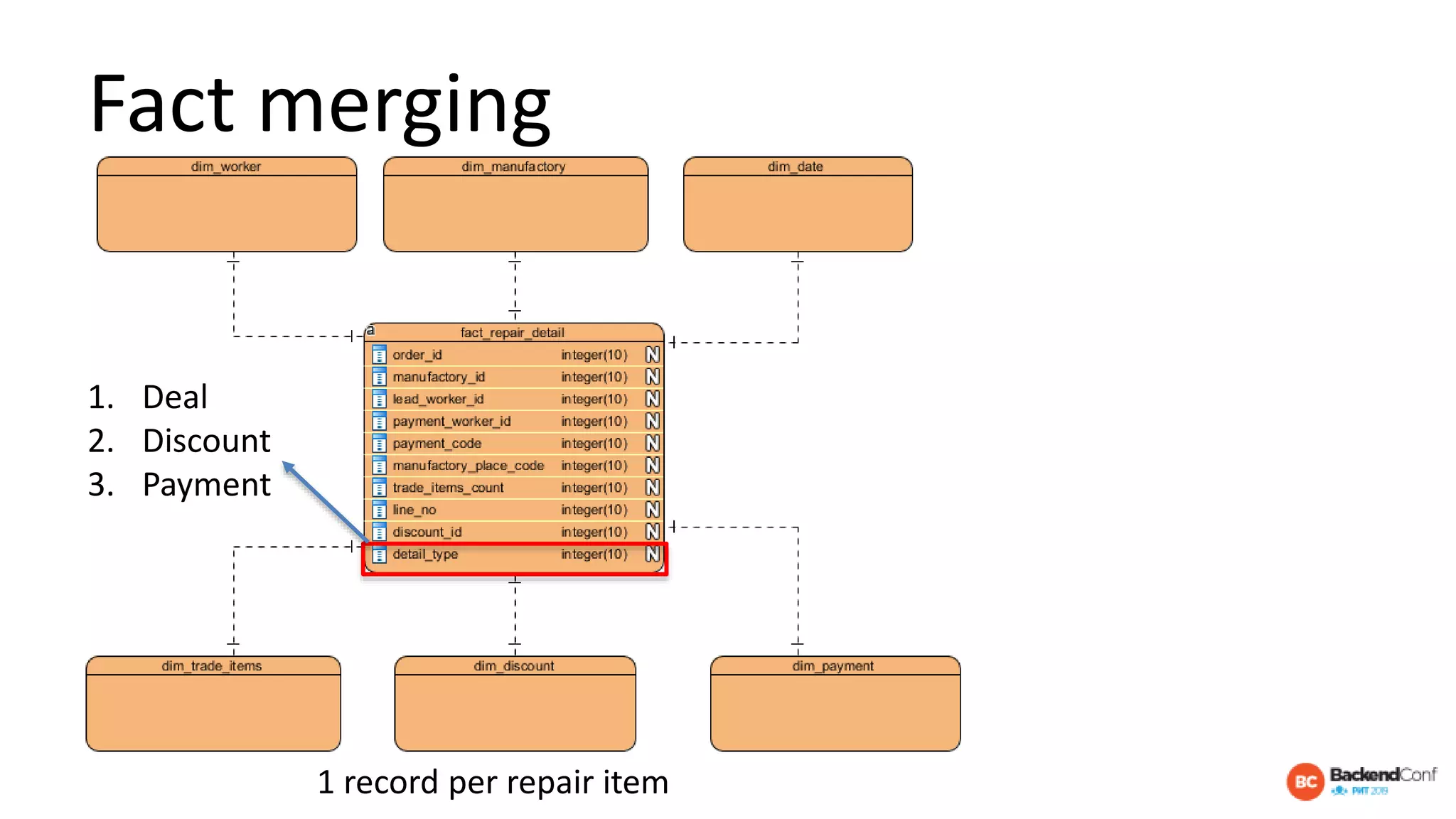

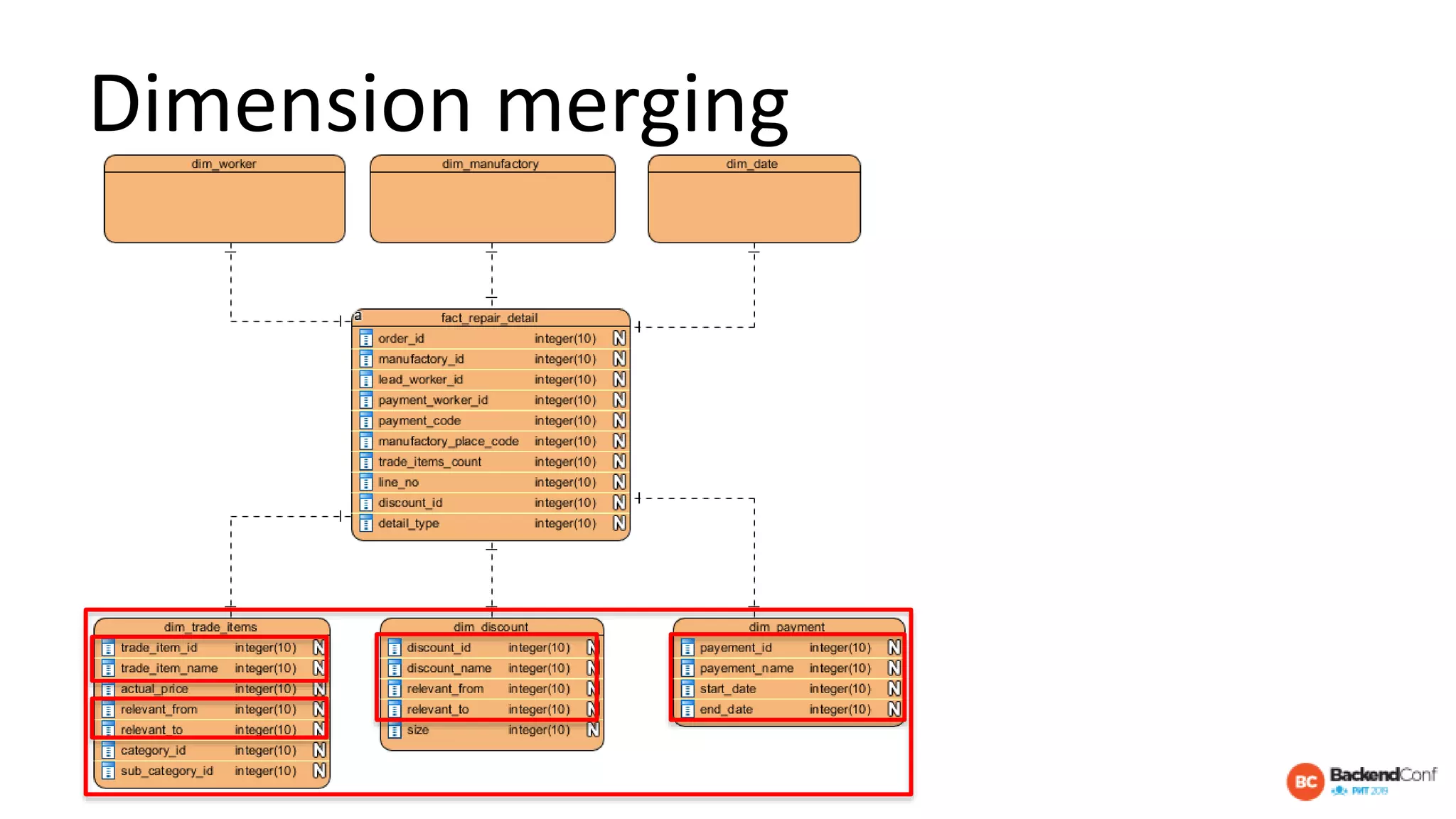
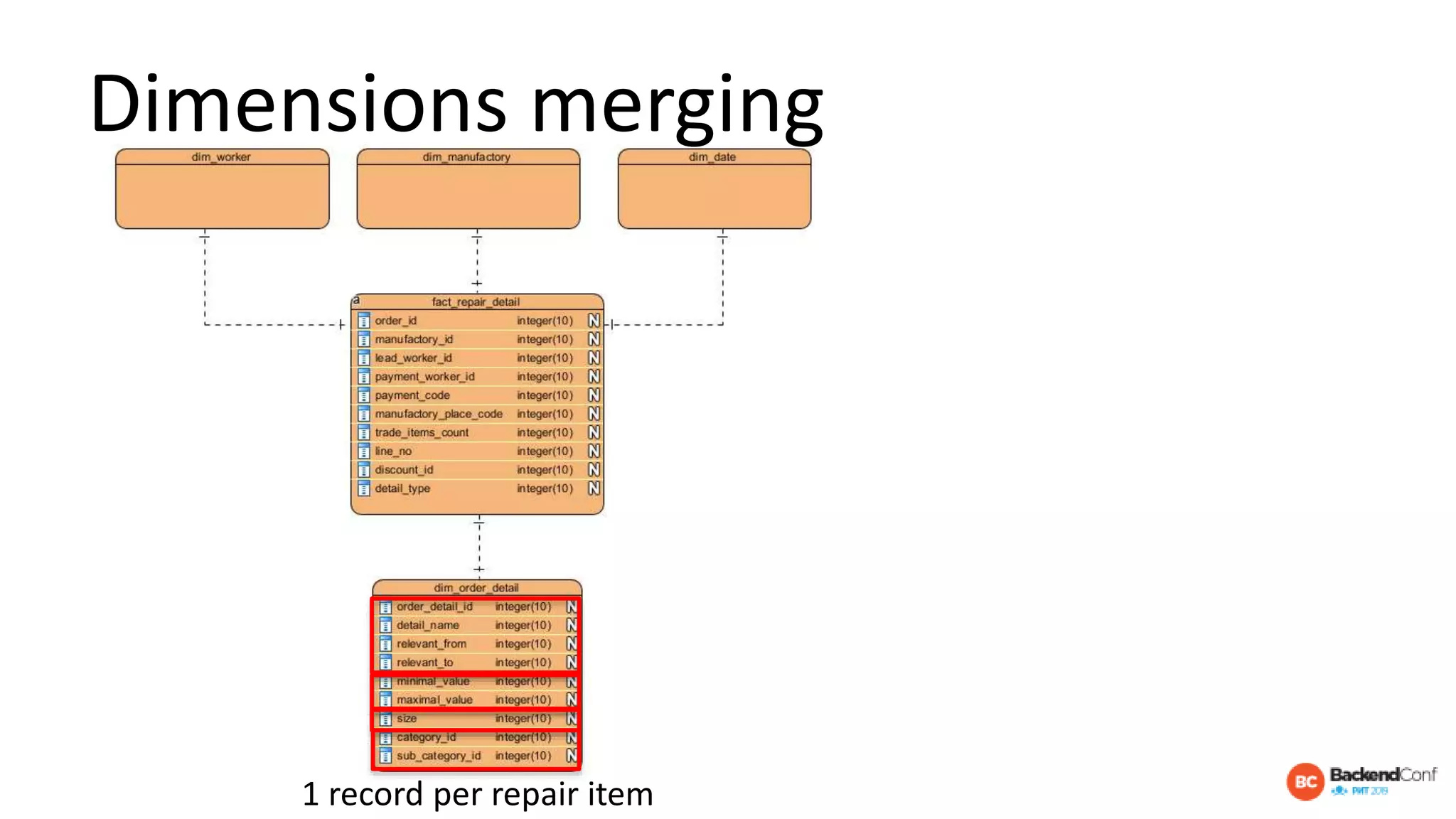

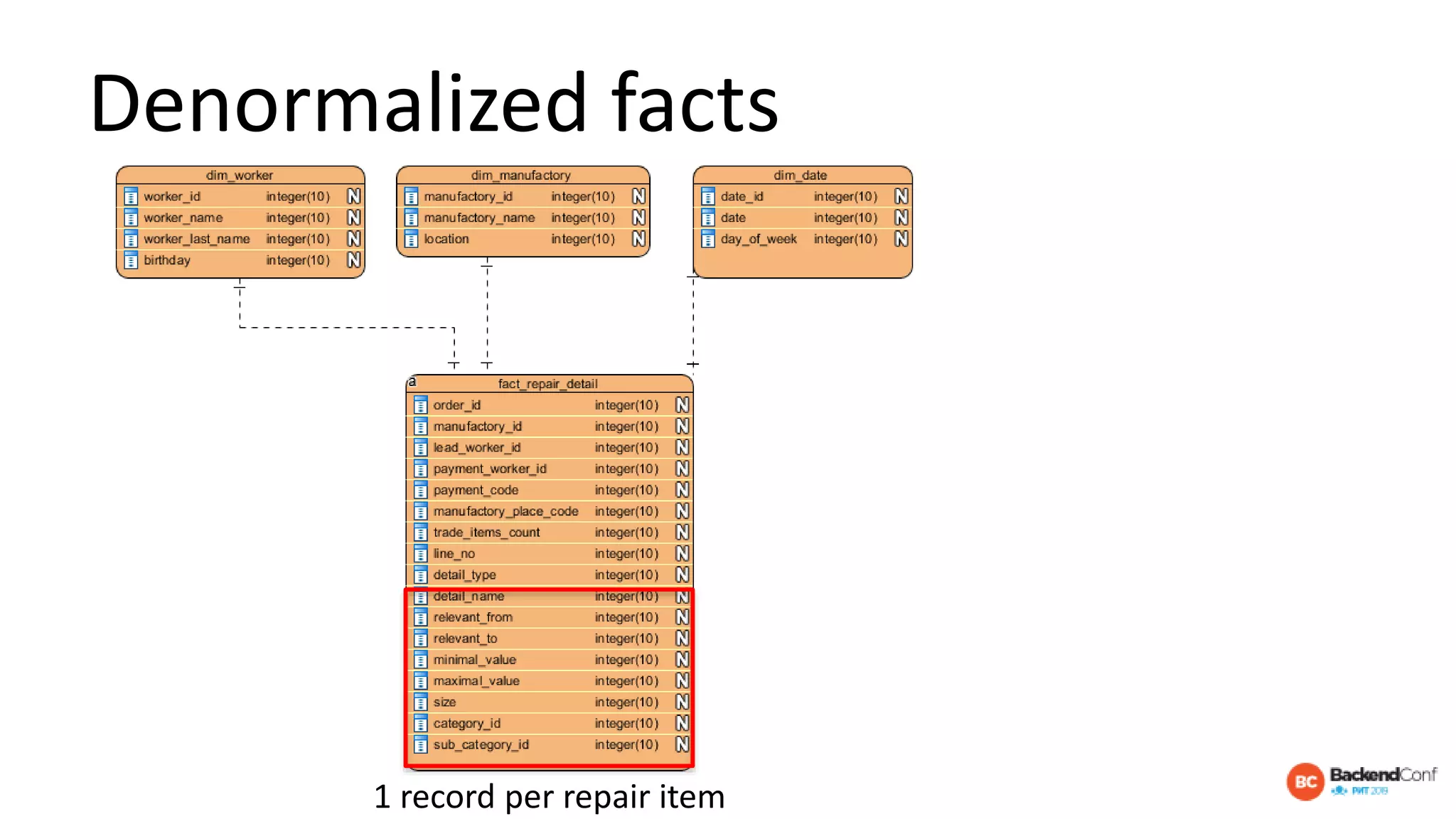
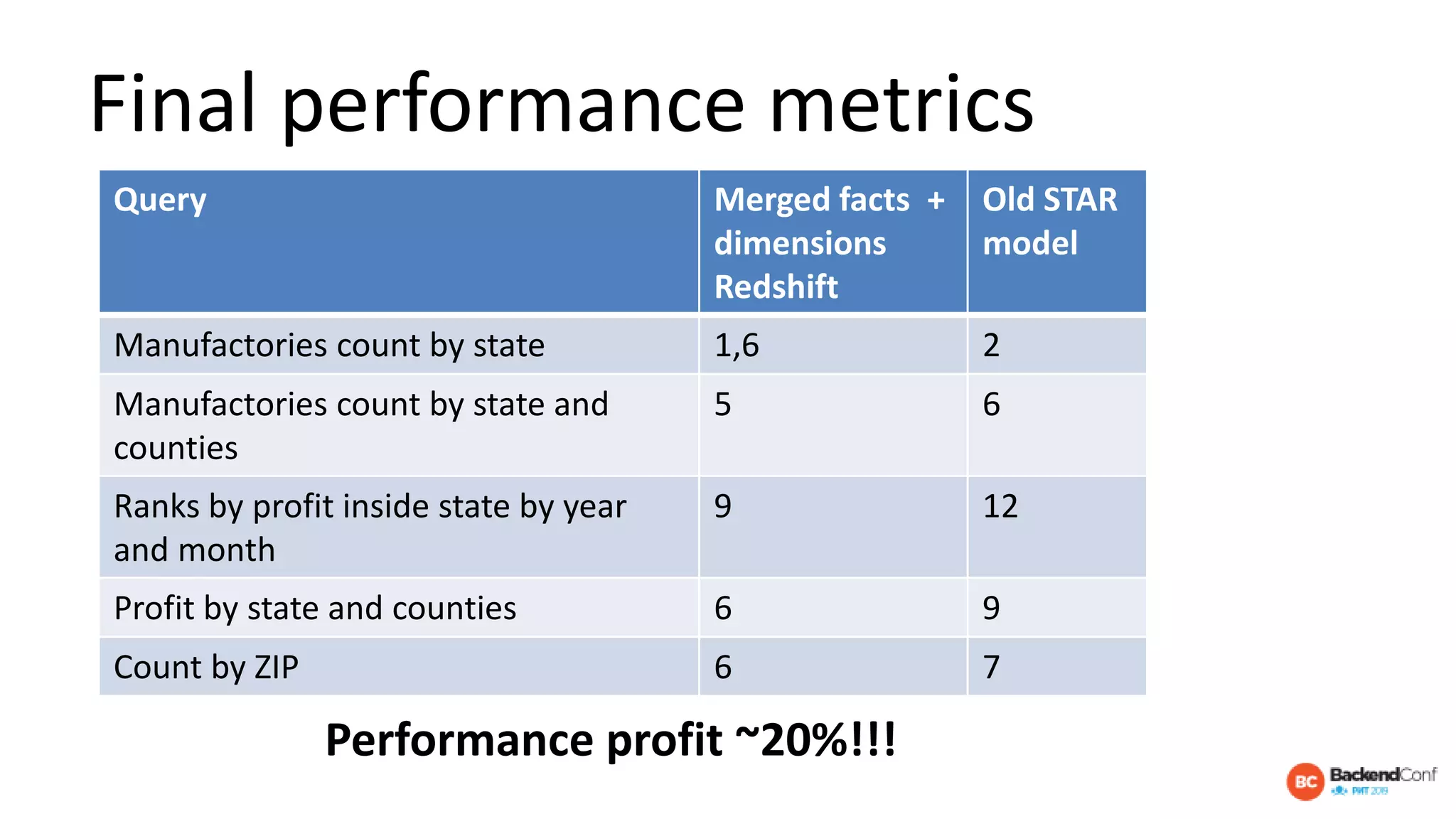









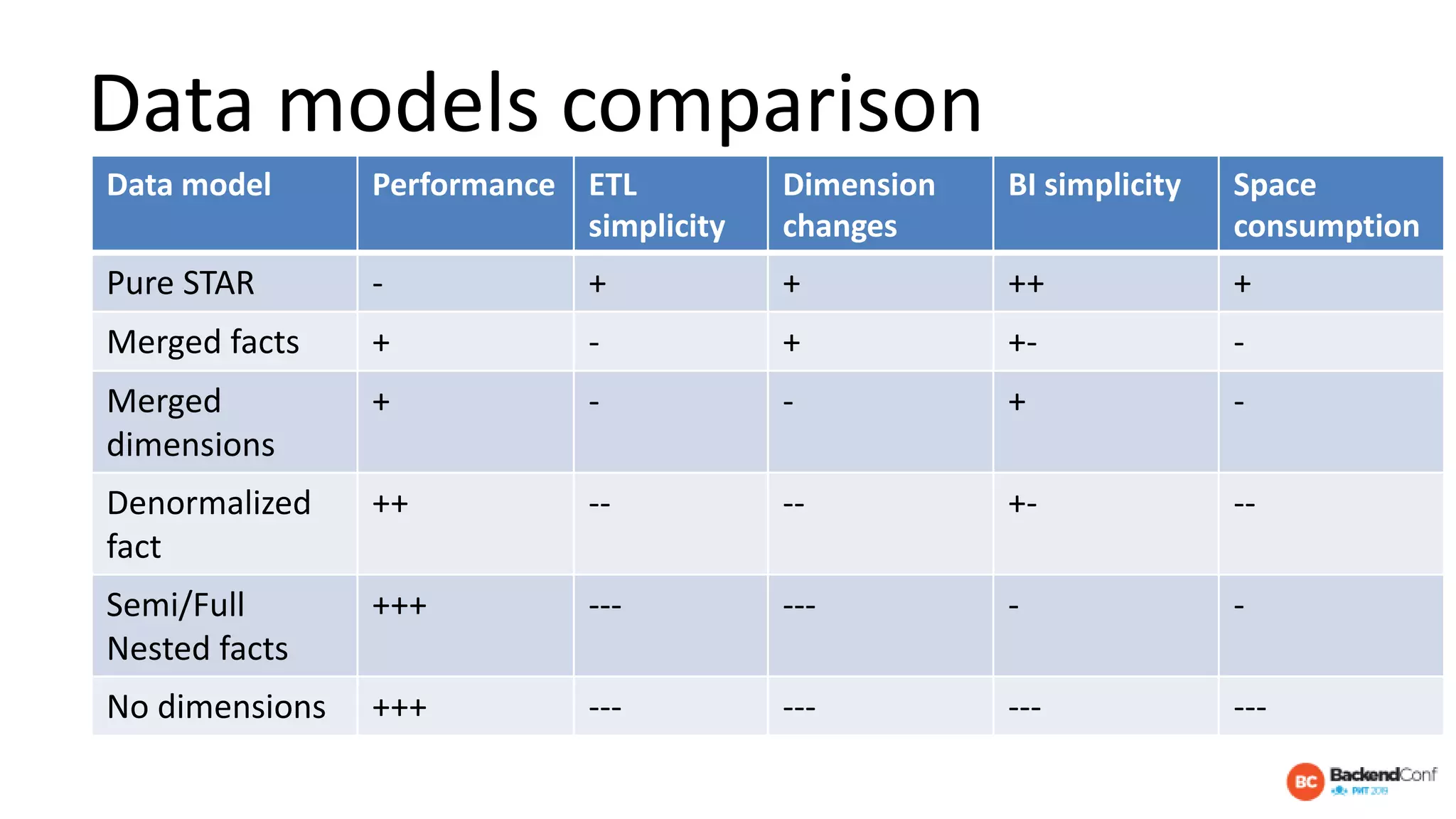


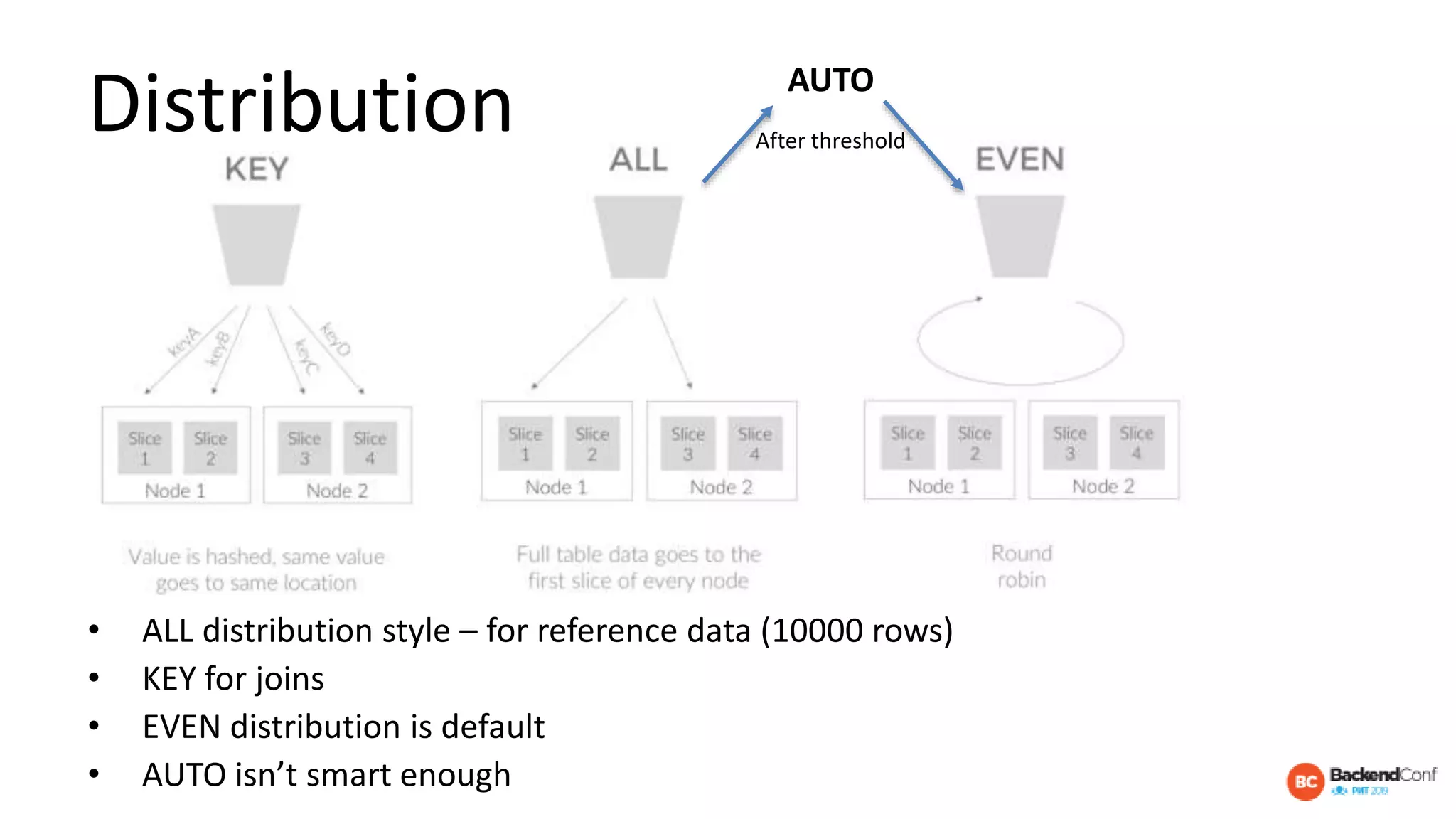





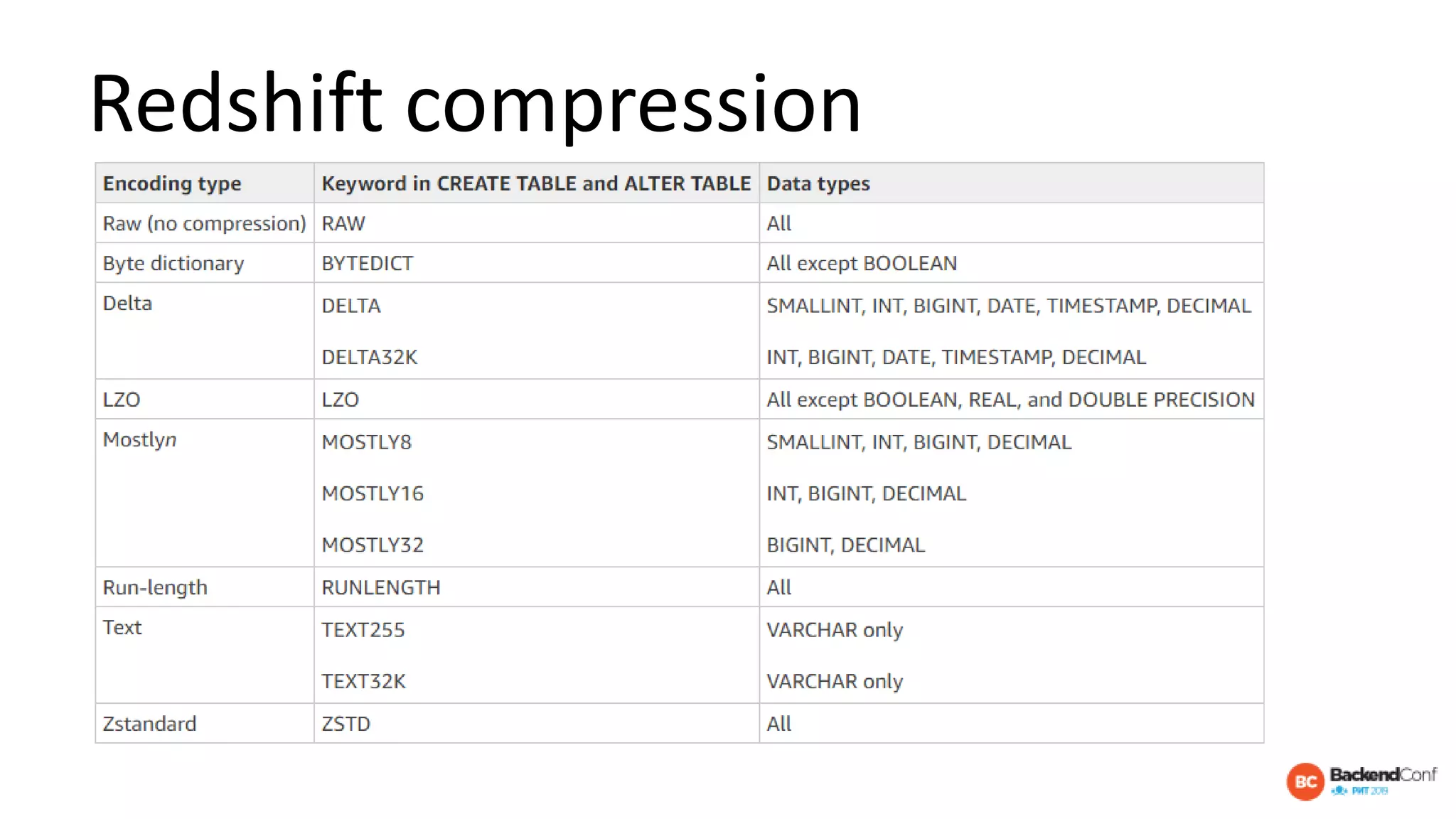














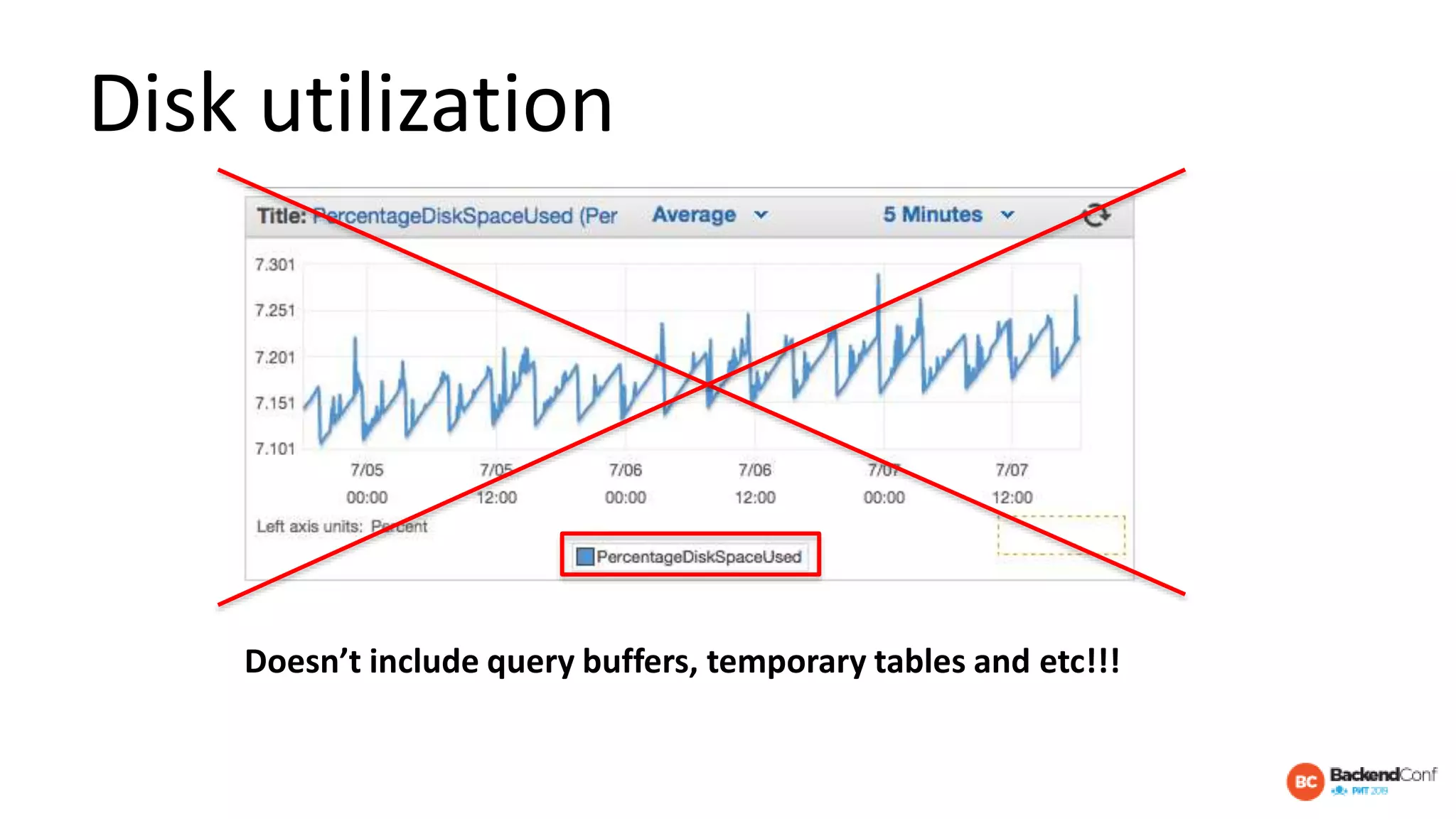





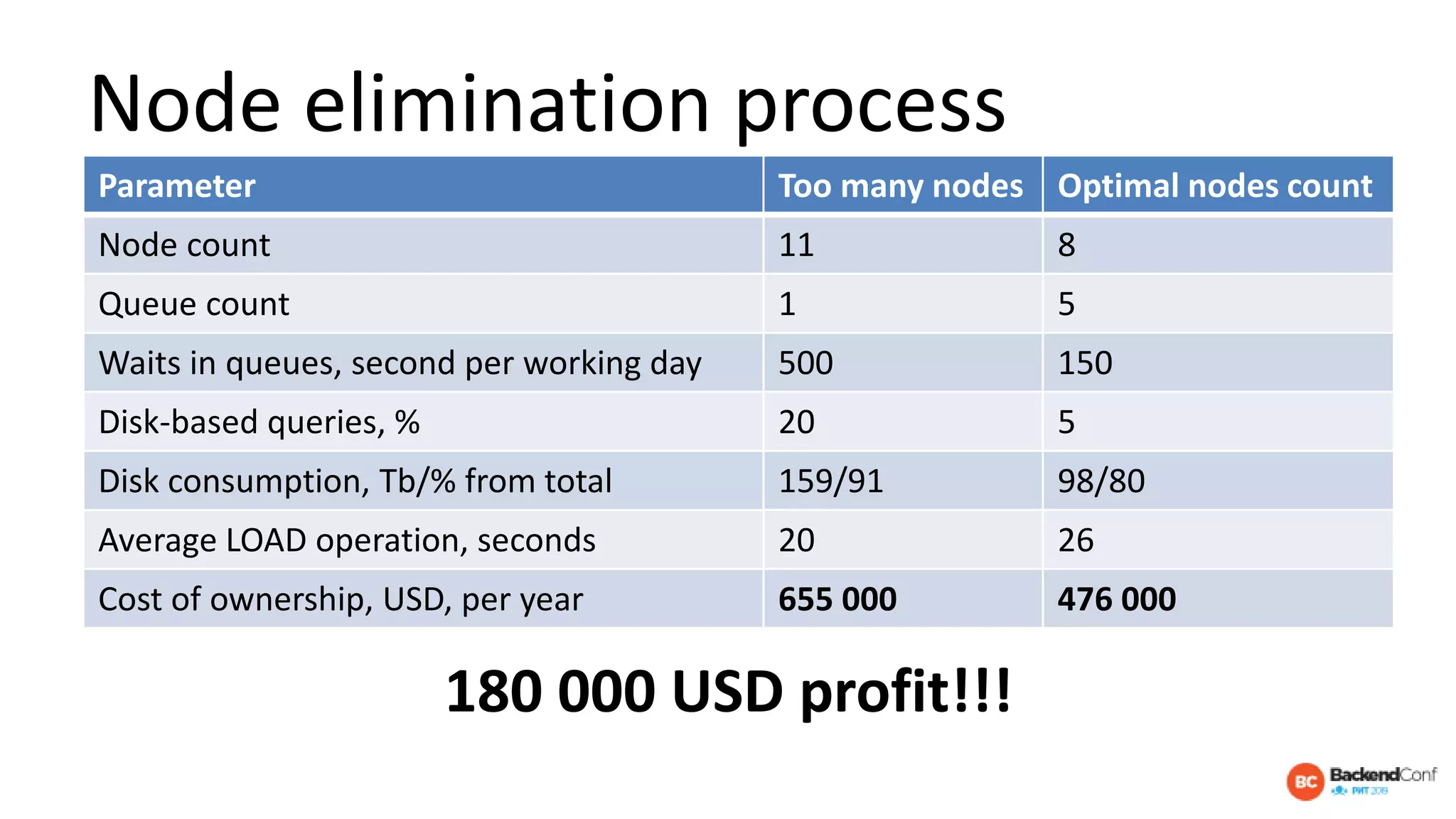









The document outlines strategies for optimizing cloud databases, particularly focusing on performance tuning and effective data modeling for various platforms like Redshift, BigQuery, and Snowflake. Key topics include common failures during data migration, pricing models, optimal data structures, and the importance of constraints. The content emphasizes that while cloud solutions offer scalability and cost-effectiveness, they require careful management and understanding of infrastructure to avoid excessive costs and inefficiencies.




















































































