Downloaded 10 times




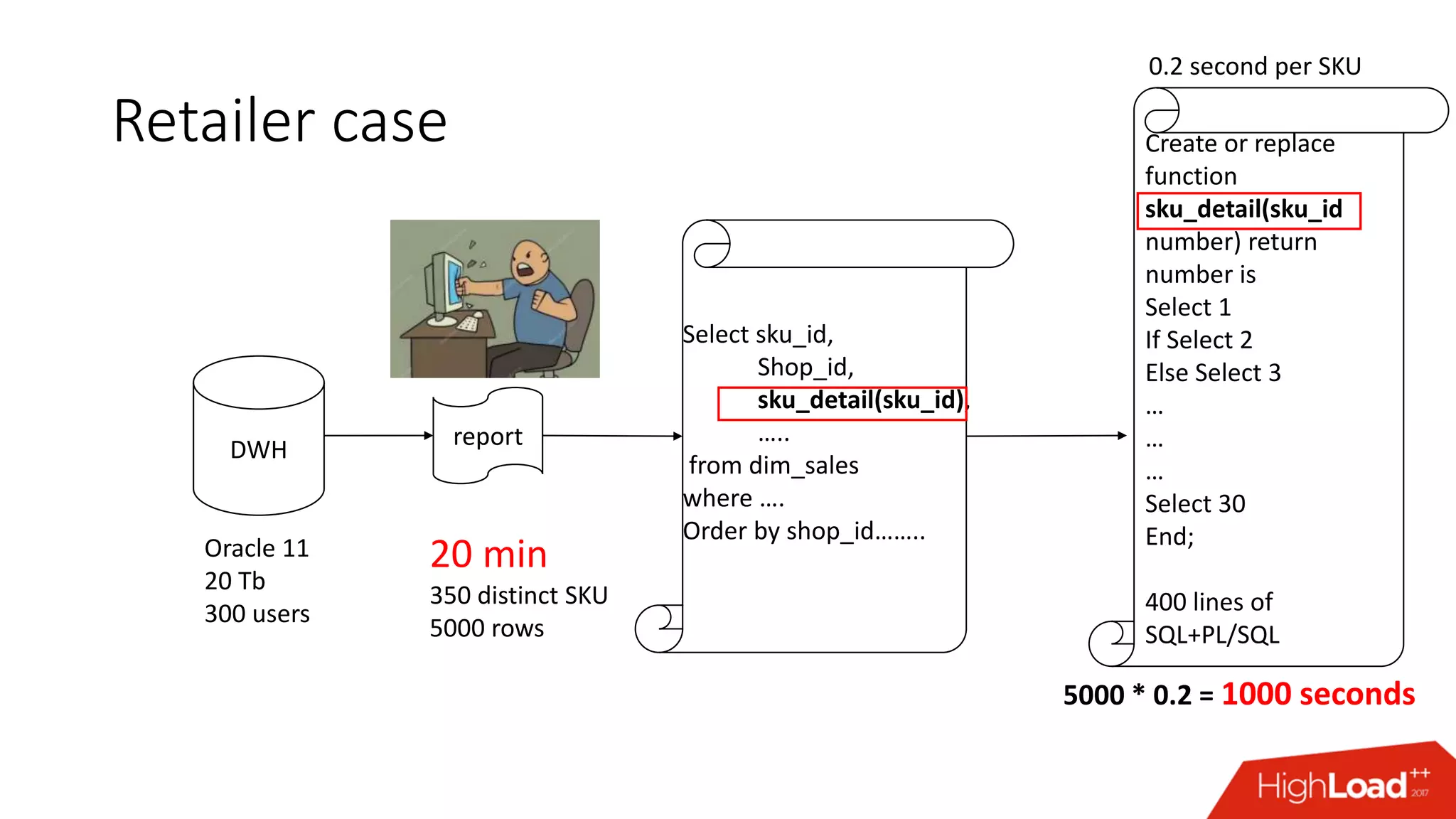
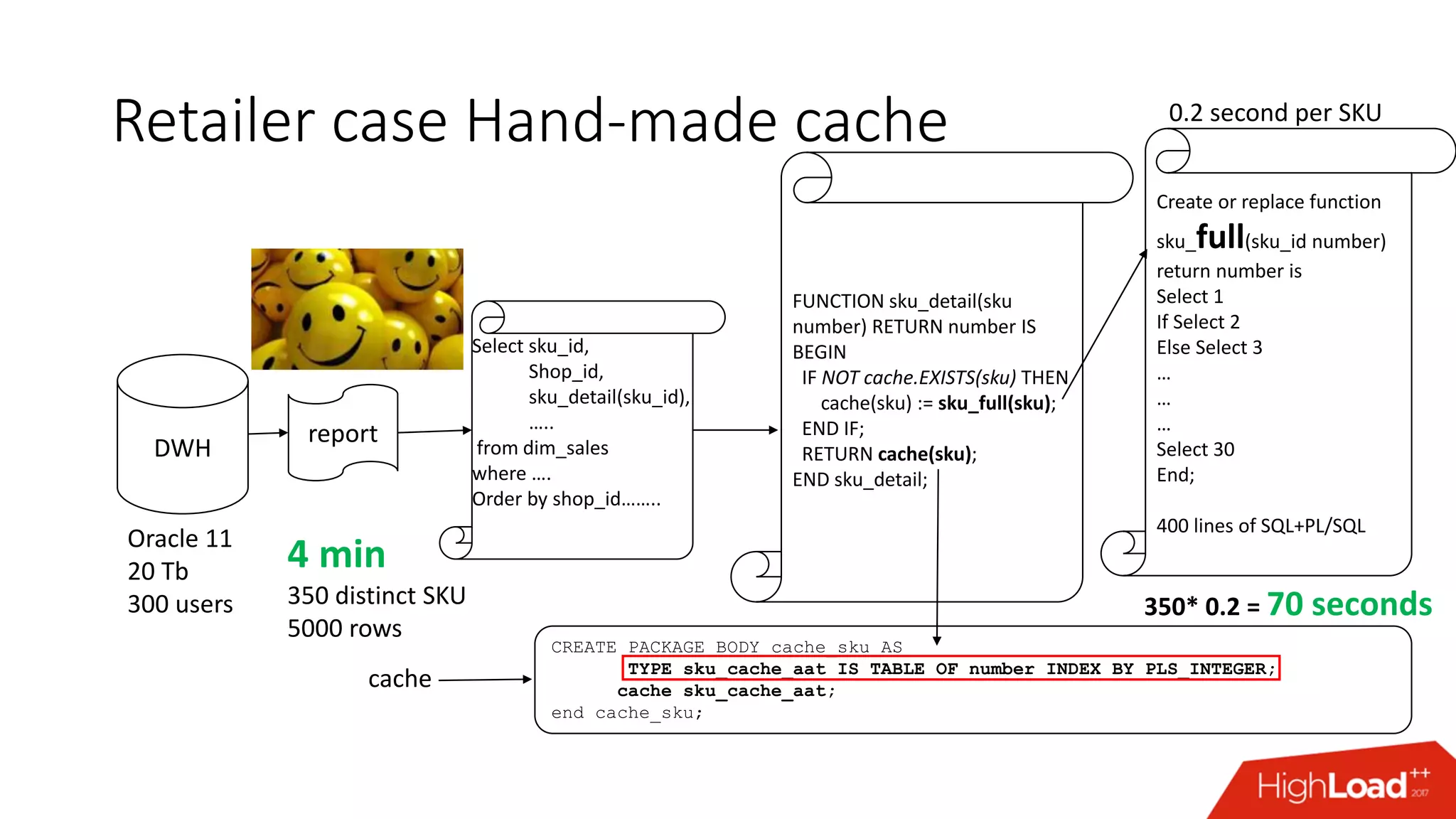
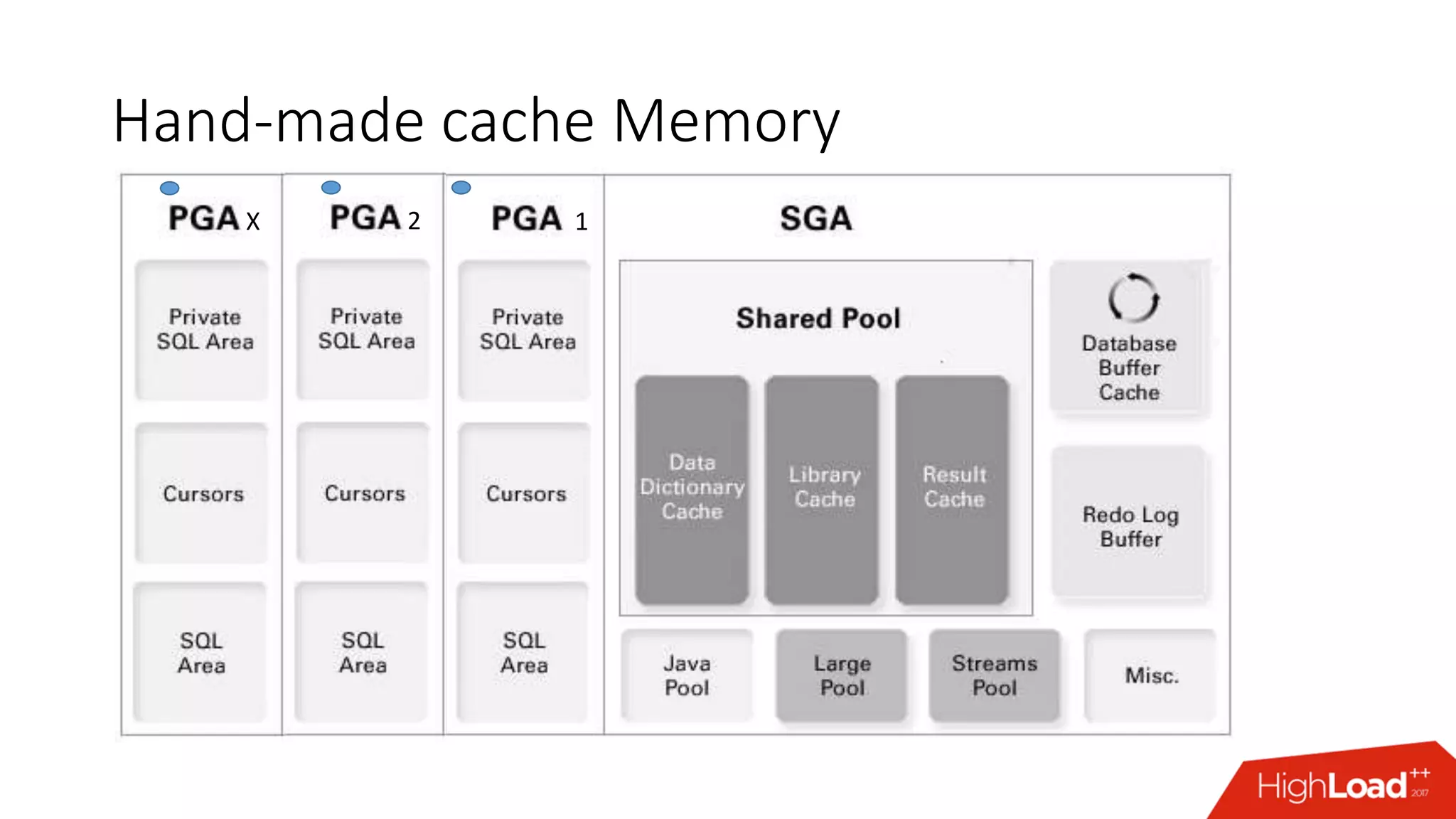



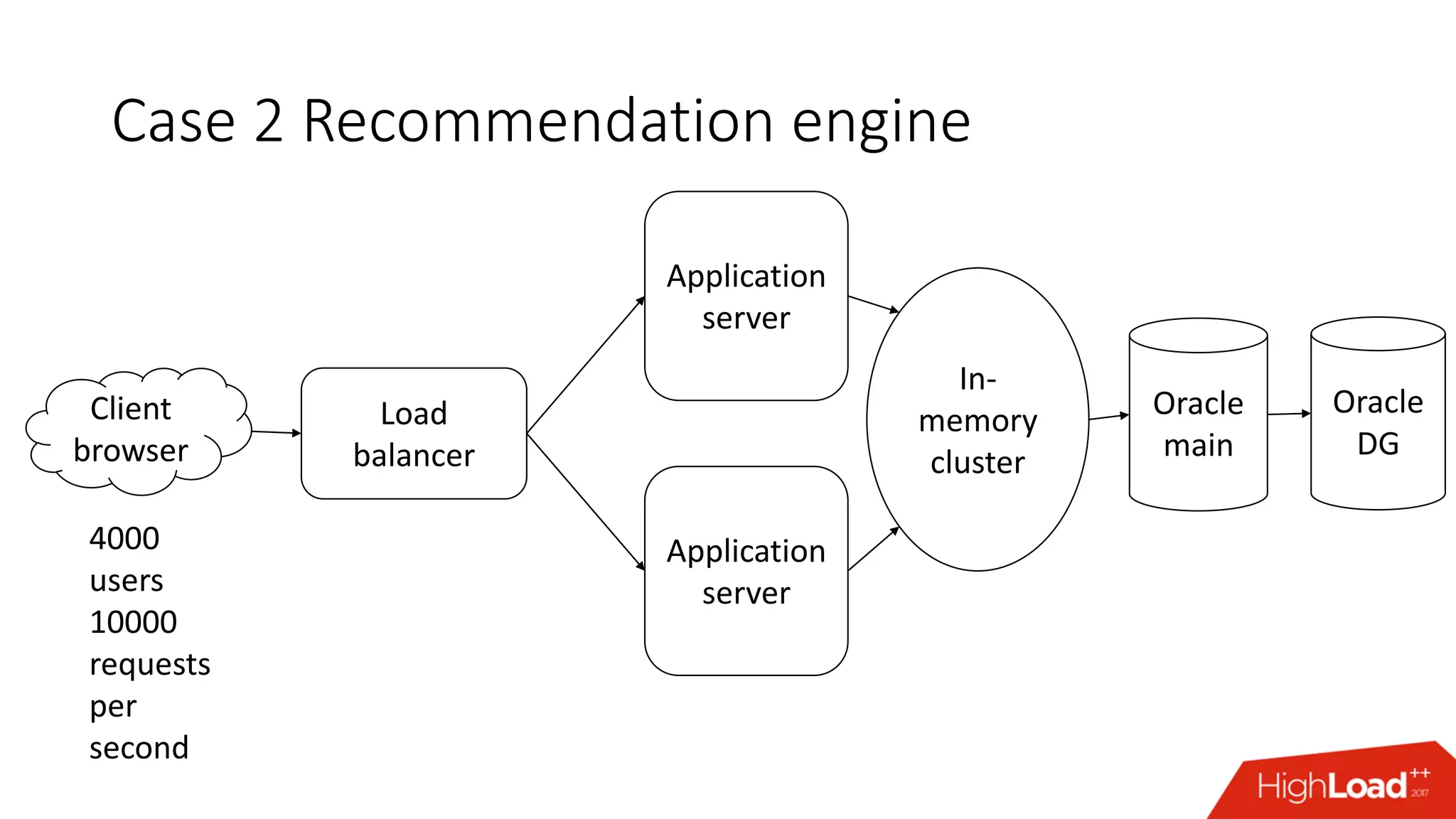




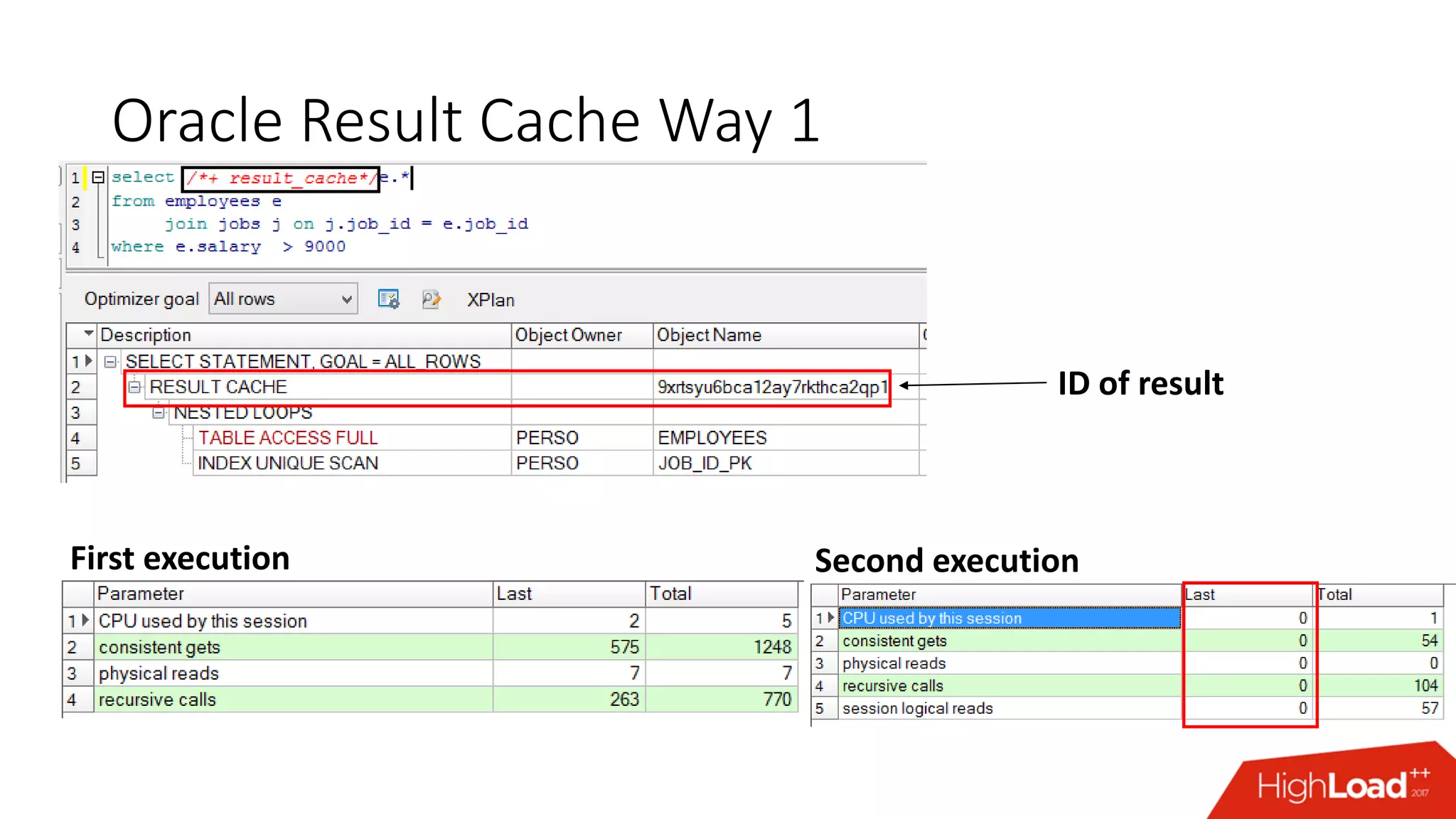
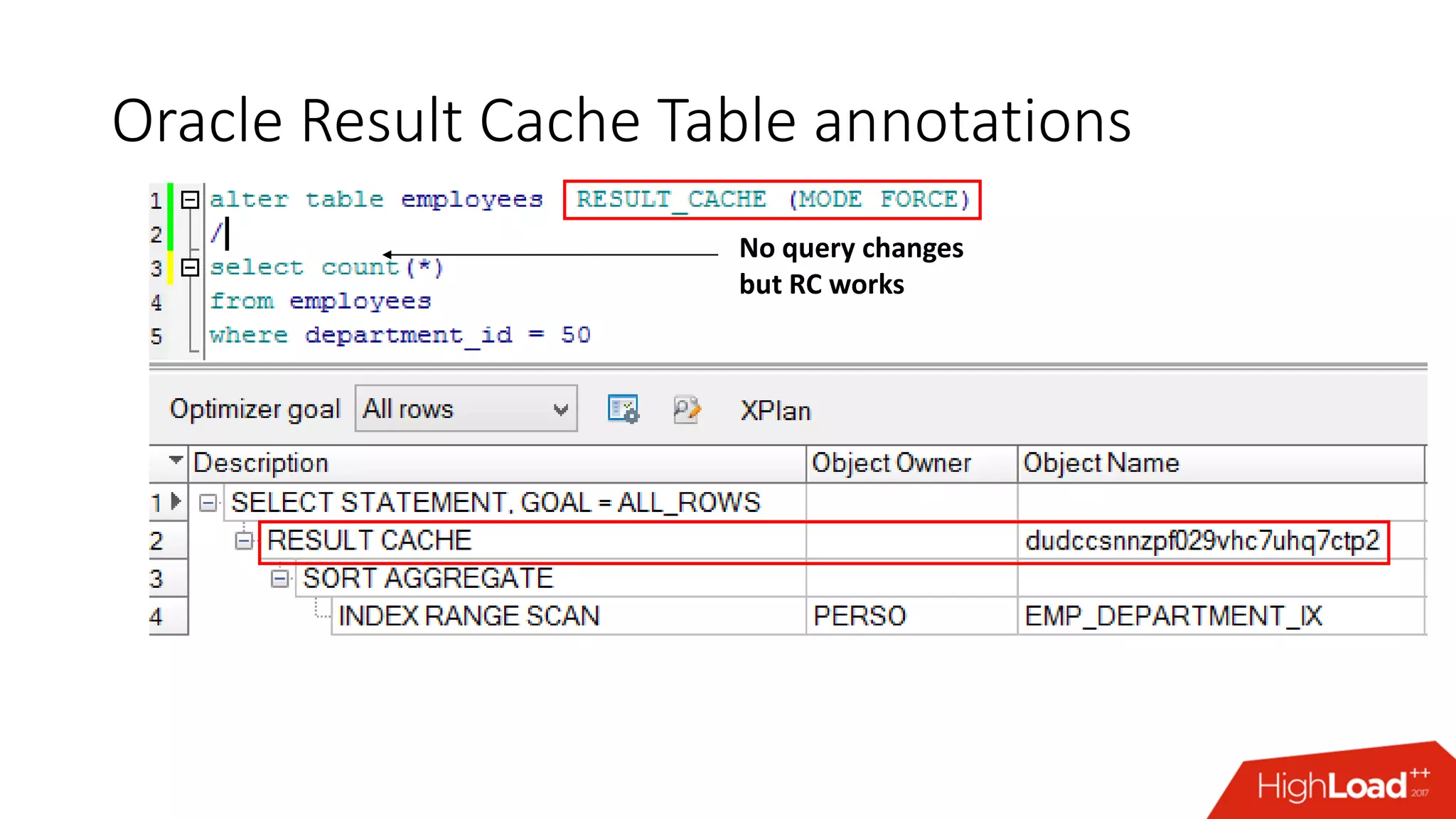
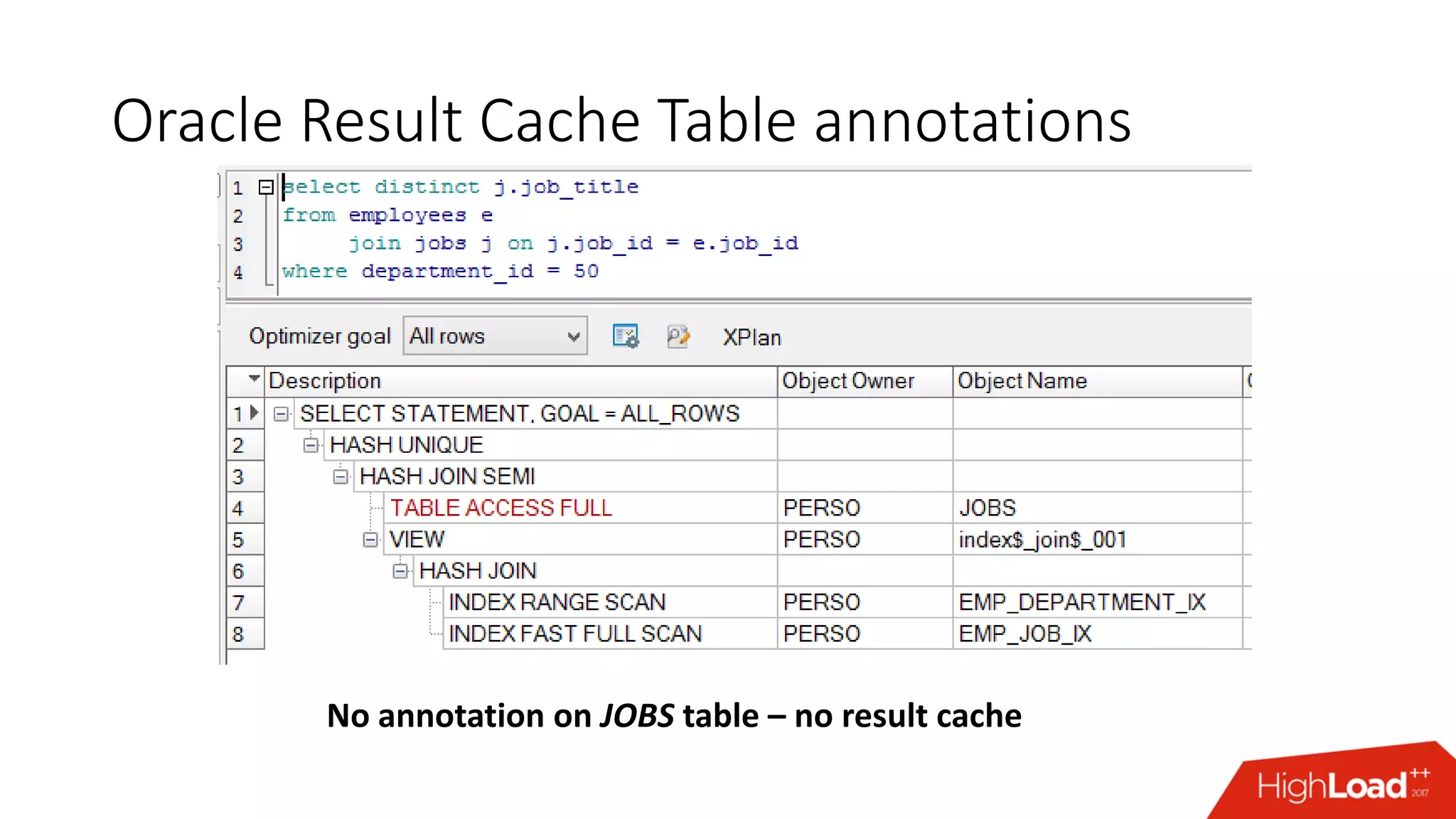



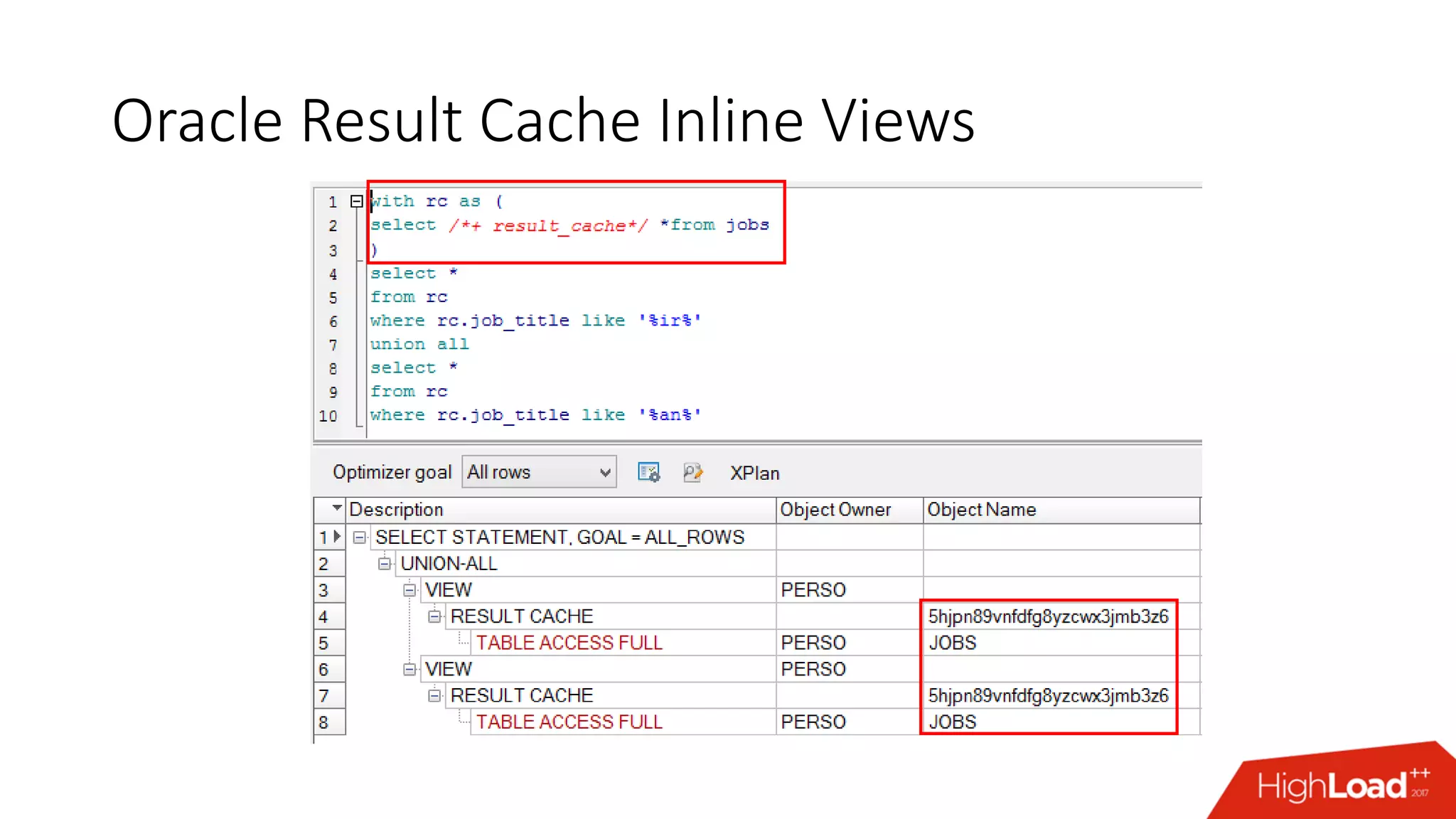

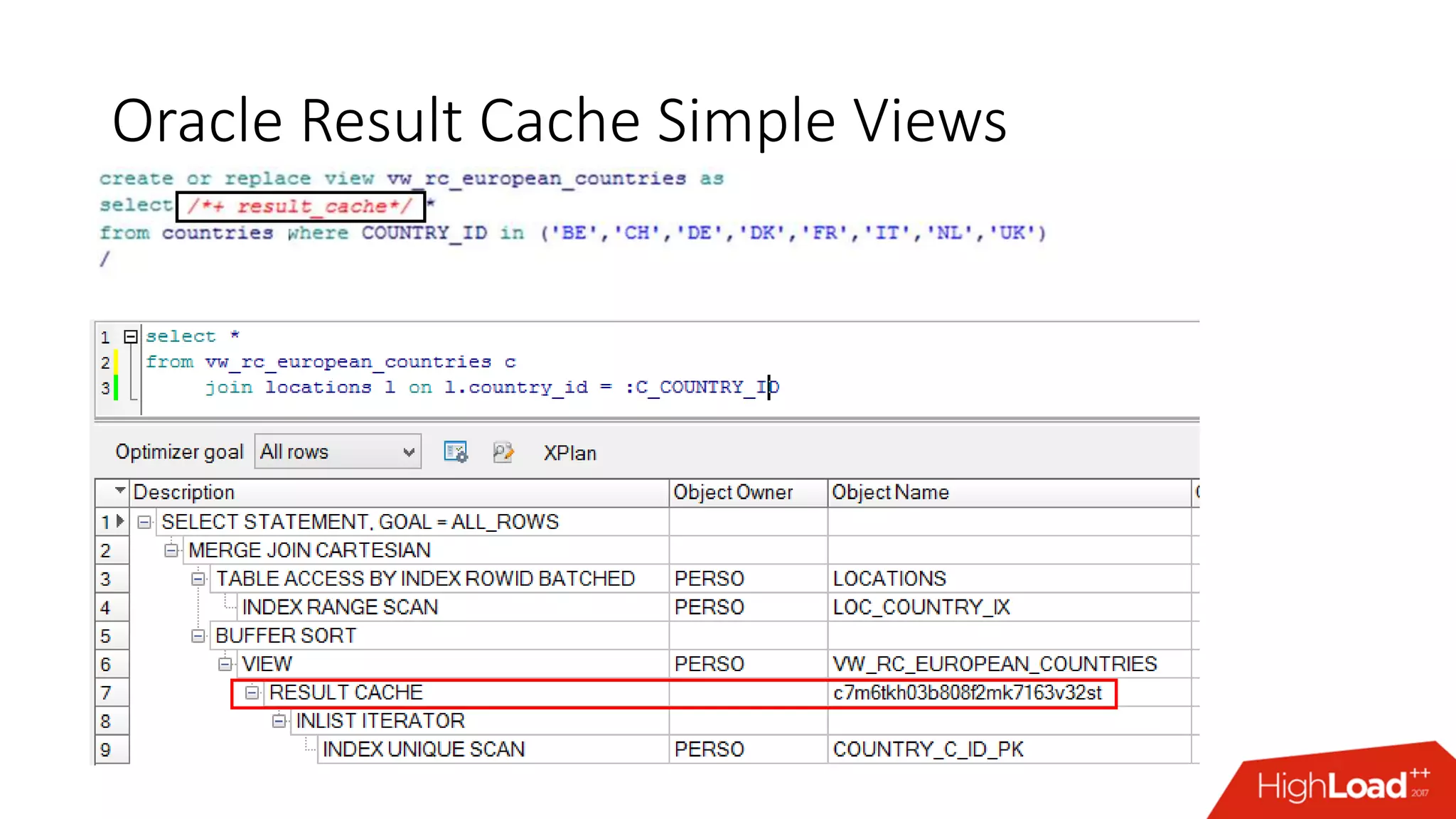
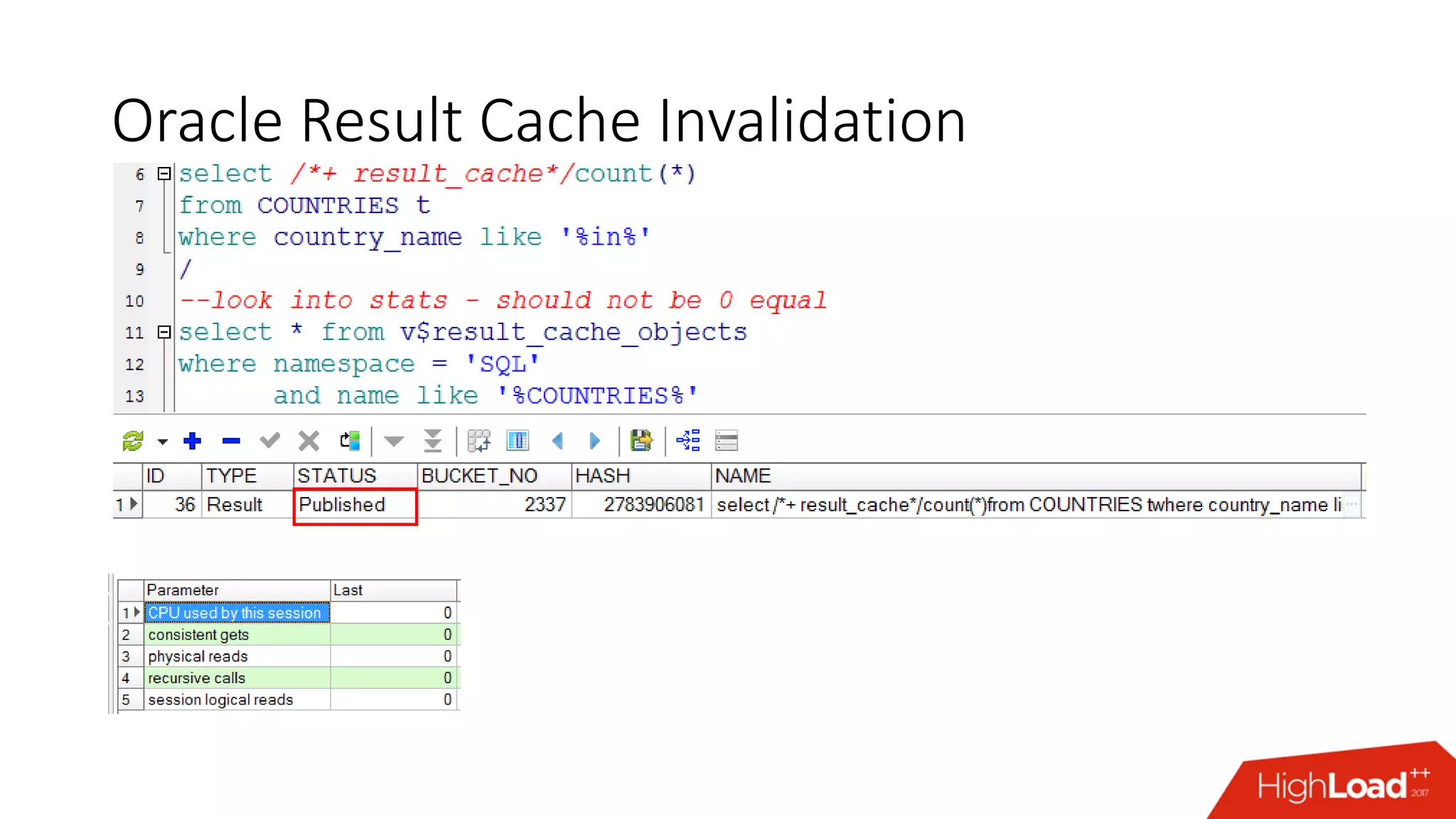
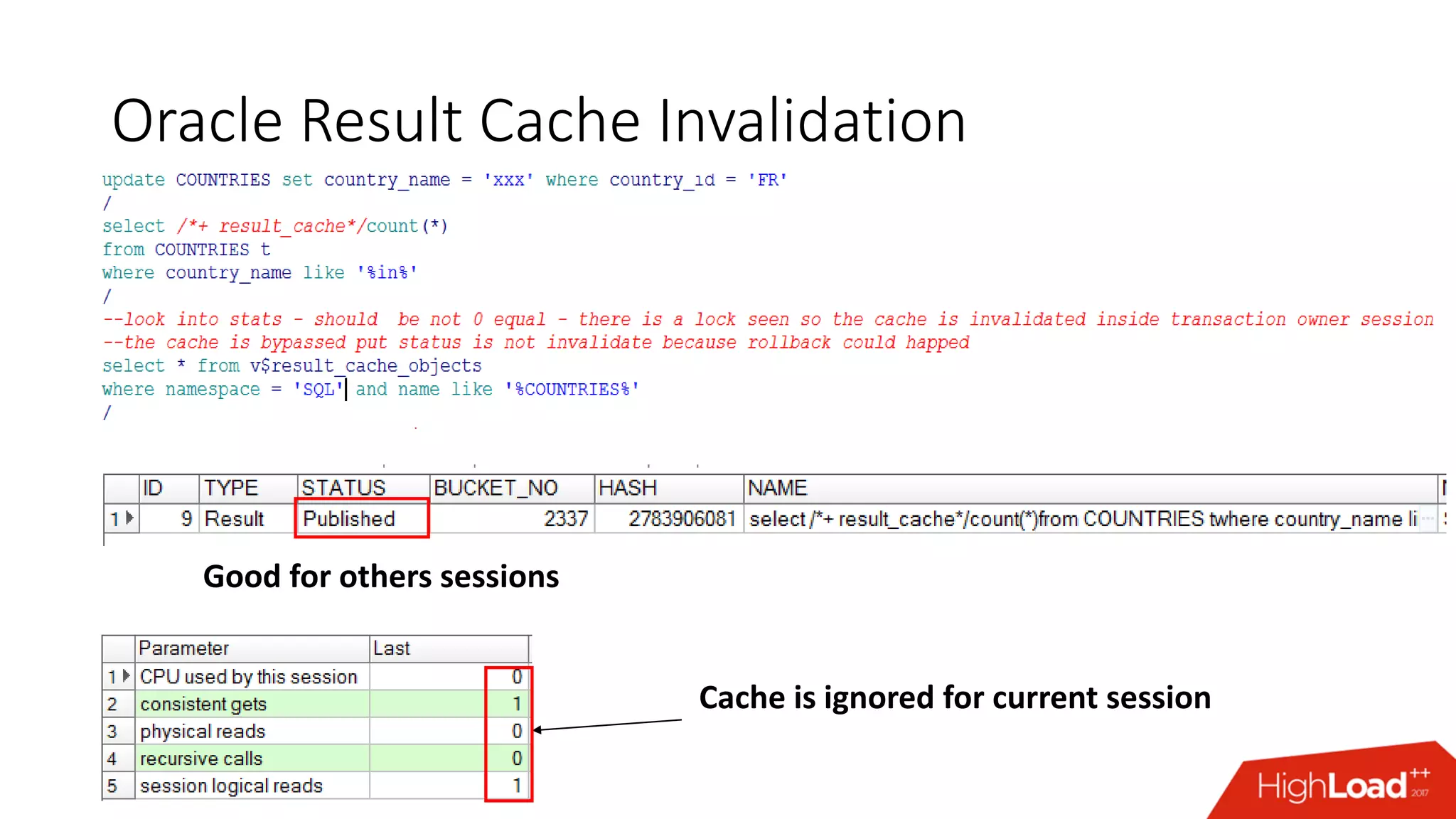
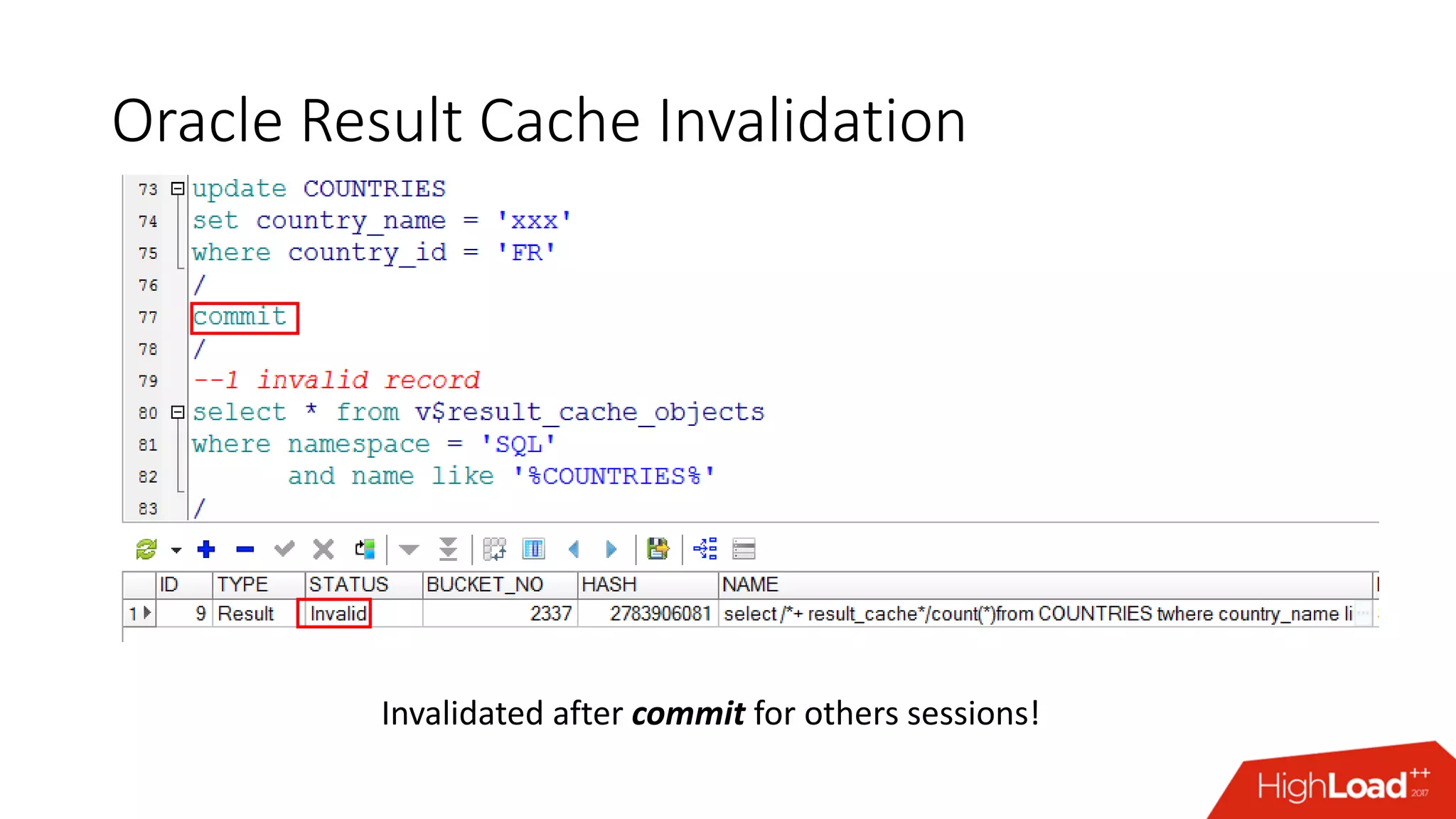








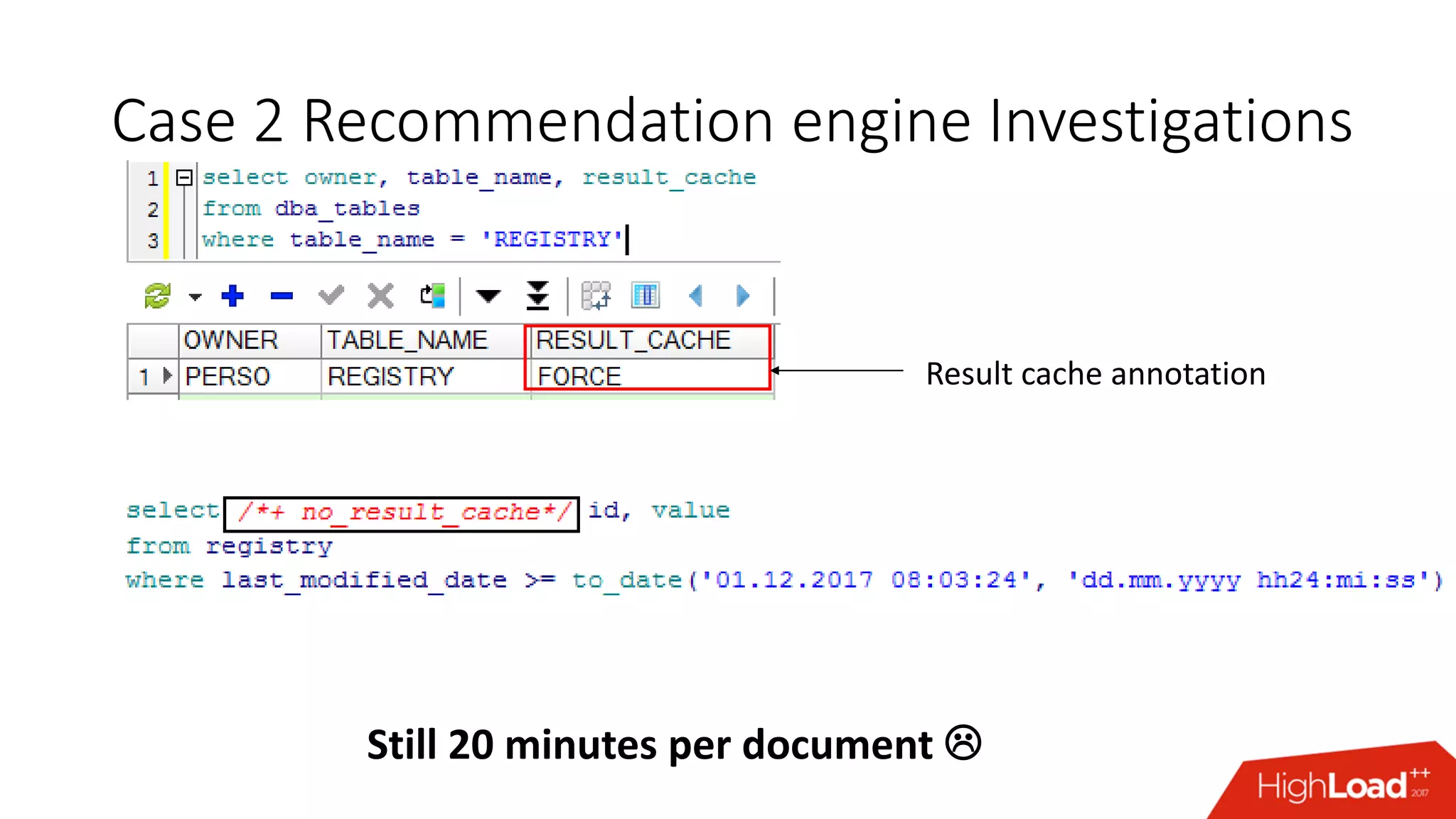
























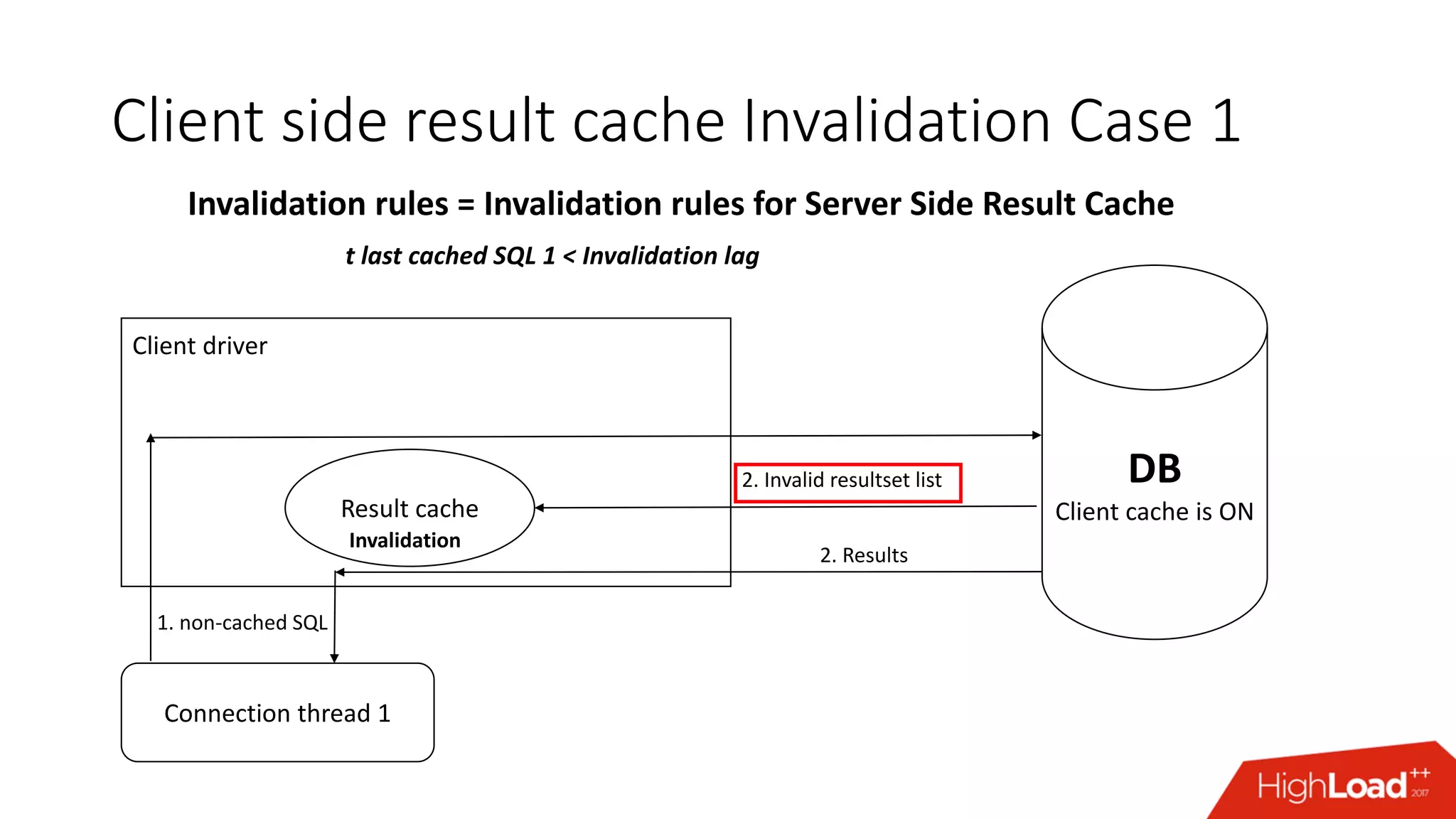













The document outlines various caching techniques in Oracle Database to optimize query performance, including database caches, result caches, and hand-made cache implementations, along with their pros and cons. It discusses a case study involving a recommendation engine, detailing the application of Oracle's result cache to enhance performance, the associated challenges, and several performance test results. The document concludes with recommendations for effective caching strategies and troubleshooting tips for result cache-related issues.
























![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)

























































