Download as PPSX, PPTX


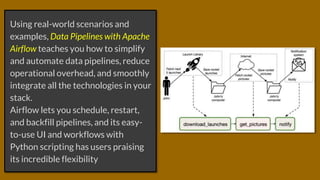





The document discusses the book 'Data Pipelines with Apache Airflow', which focuses on efficient data pipeline management using Apache Airflow. It highlights the book's practical approach to simplifying and automating data workflows and contains endorsements from industry professionals. Additionally, readers can purchase the book at a discount using a specific code on the publisher's website.























































































