Download as PDF, PPTX







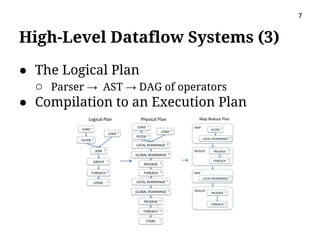


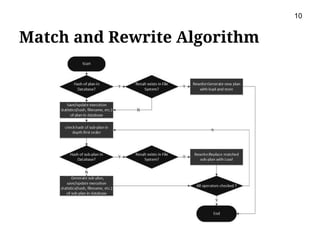
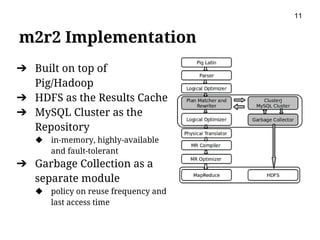

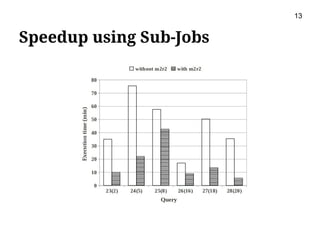
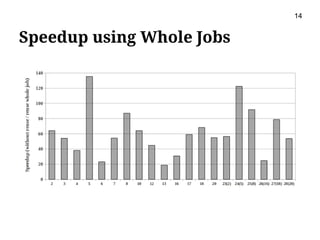




This document presents m2r2, a framework for materializing and reusing results in high-level dataflow systems for big data. The framework operates at the logical plan level to be language-independent. It includes components for matching plans, rewriting queries to reuse past results, optimizing plans, caching results, and garbage collection. An evaluation using the TPC-H benchmark on Pig Latin showed the framework reduced query execution time by 65% on average by reusing past query results. Future work includes integrating it with more systems and minimizing materialization costs.











































































