Downloaded 425 times



![Introduction
• Variance: Average of the squares of deviations of the observations of a
sample from the mean of the sample drown from a population
[ ∑(x – x)2/N]
• Variance: The square of the standard deviation.
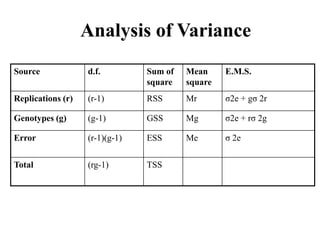
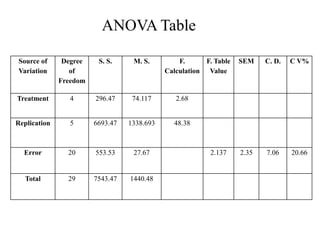
• The statistical procedure which separate or split the total variation into
different components is known as “ANOVA”
• R.A. Fisher
• “It is the technique of sorting out the total variation into some known and
unknown component of variation from a given set of data”
Recognized source of variance are replication, genotype, error and total.
It is a mathematical procedure of partitioning the total variation into various
recognized source of variance](https://image.slidesharecdn.com/gp504-151102052211-lva1-app6892/85/Analysis-of-Variance-ANOVA-MANOVA-Expected-variance-components-Random-and-fixed-models-3-320.jpg)





































This document provides an introduction to analysis of variance (ANOVA) and multivariate analysis of variance (MANOVA). It discusses key concepts like variance components, fixed and random models, and the assumptions of MANOVA. The goals of ANOVA are described as estimating variance components, evaluating genetic contributions, and testing hypotheses. MANOVA tests for differences in multiple dependent variables simultaneously, which can protect against Type I errors compared to multiple ANOVAs. Both methods require assumptions like normality and homogeneity of variances.



































































