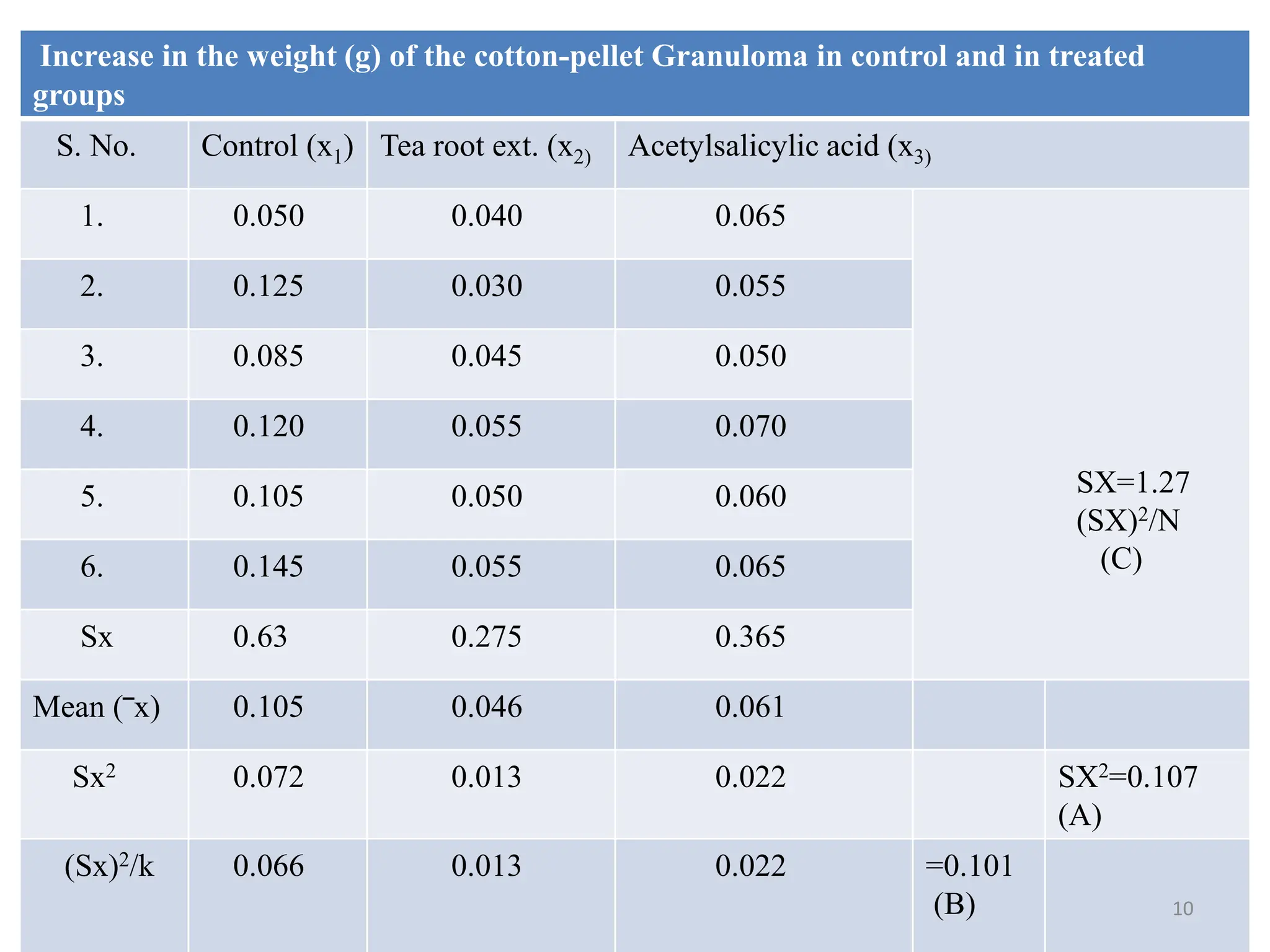
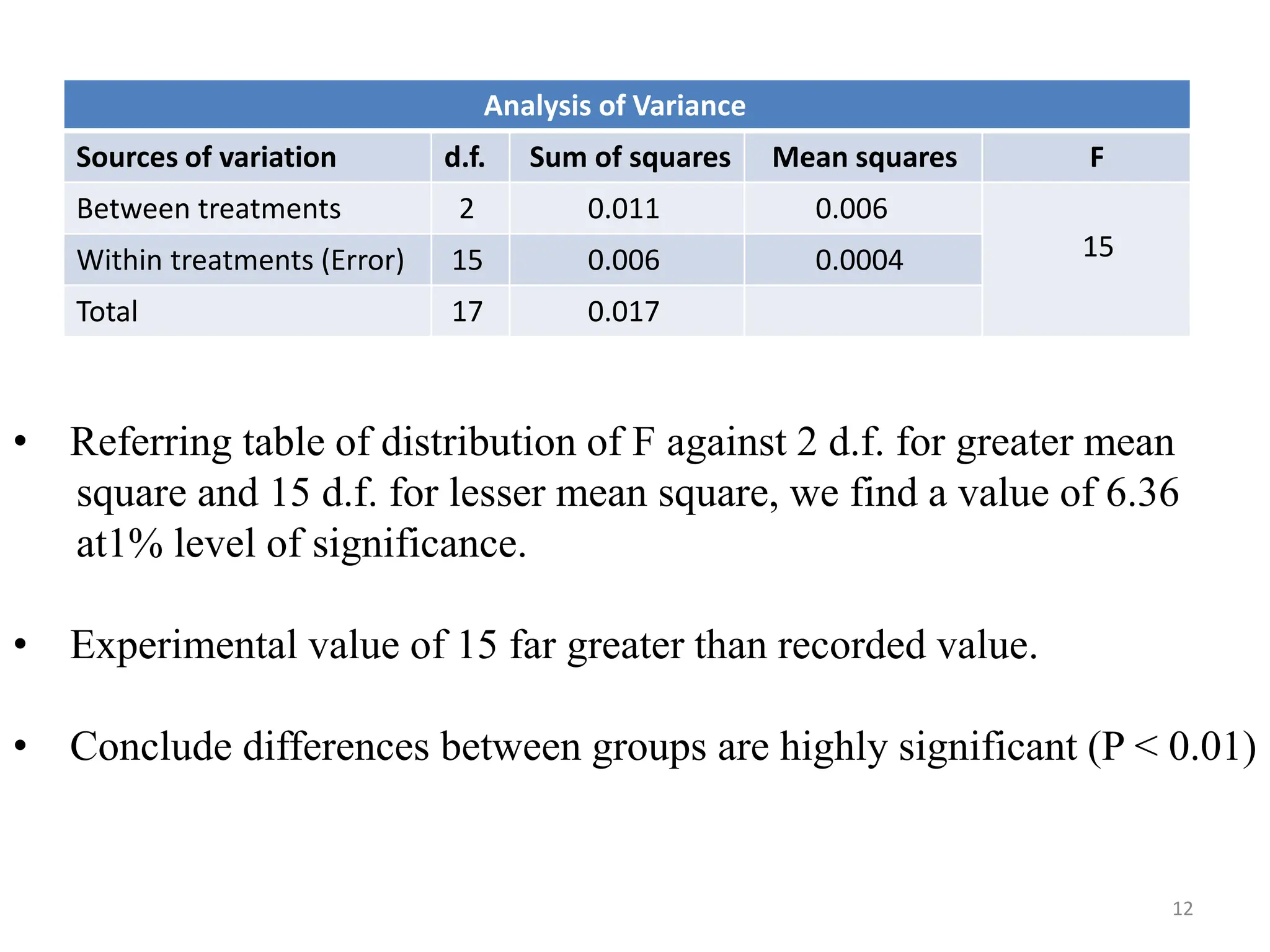
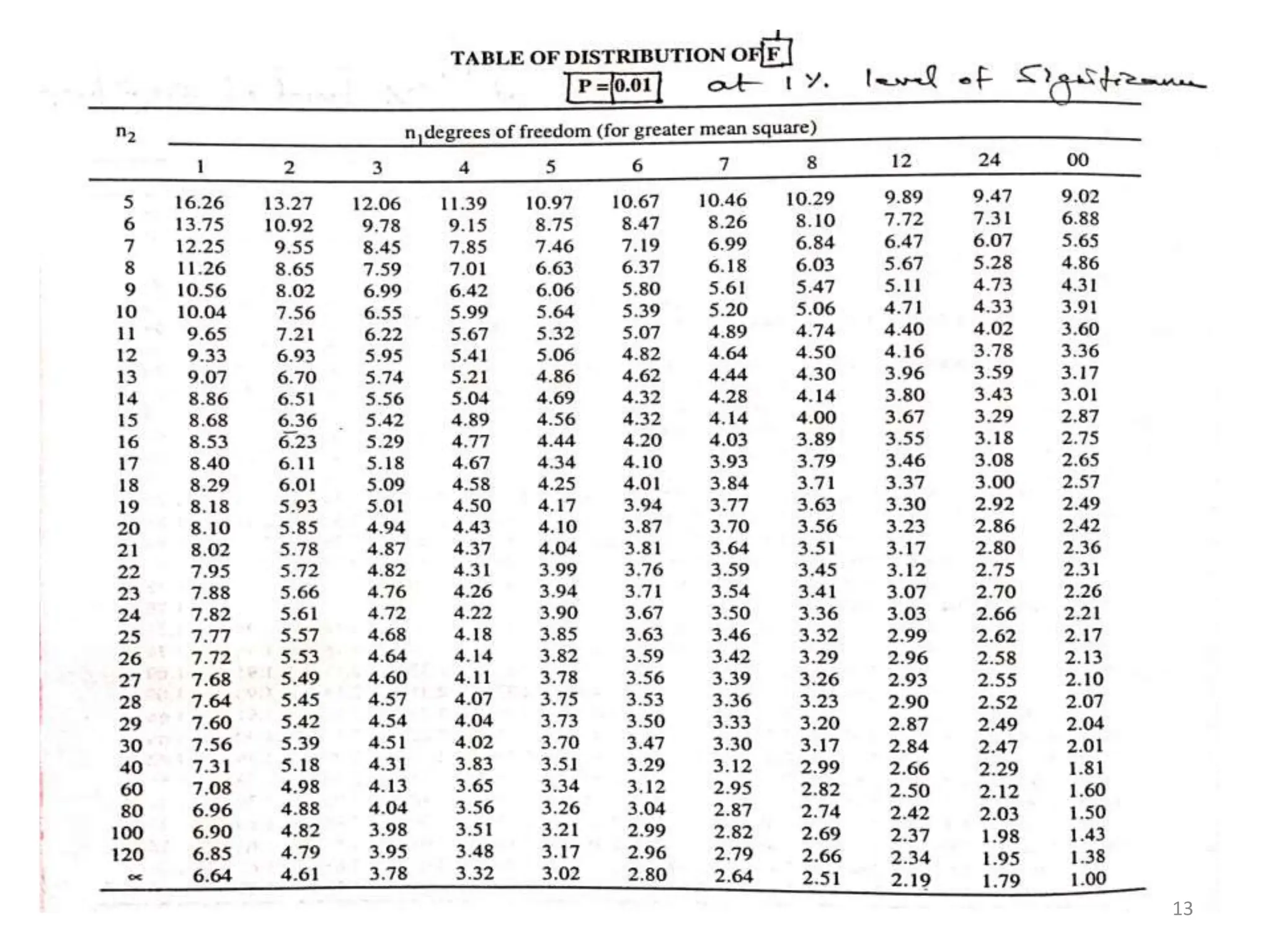
This document provides an overview of analysis of variance (ANOVA). It discusses how ANOVA compares mean differences across more than two groups, extending the t-test. It compares variations between and within groups to determine if mean differences are statistically significant. The document outlines different types of ANOVA including one-way ANOVA for a single independent variable, multifactor ANOVA for multiple independent variables, and MANOVA for multiple dependent variables. It provides an example calculation and analysis of a one-way ANOVA comparing three treatment groups.