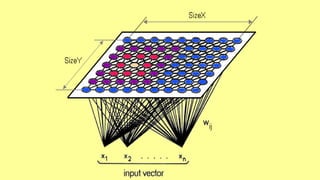
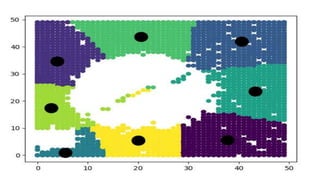
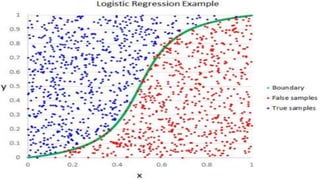
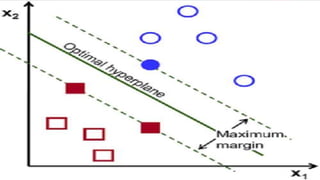
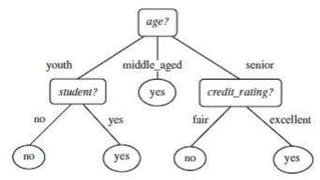
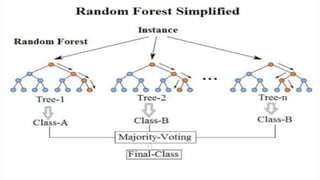
The document discusses several machine learning algorithms: Kohonen's self-organizing map (SOM) which reduces dimensionality; K-means clustering which groups similar data points; logistic regression which classifies data using probabilities; support vector machines (SVM) which find optimal separating hyperplanes; C4.5 decision trees which classify using a question-answer tree structure; random forests which create many decision trees; gradient boosting decision trees which iteratively adjust weights; and K-nearest neighbors (KNN) which classifies based on closest training examples. For each algorithm, it provides a brief overview of the approach and key steps or equations involved.


































































![Different Algorithms used in classification [Auto-saved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/differentalgorithmsusedinclassificationauto-saved-230424061120-359bae8f-thumbnail.jpg?width=640&height=640&fit=bounds)



















