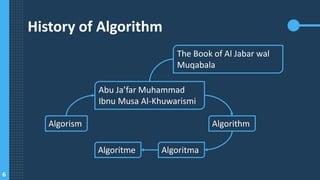
The document provides an overview of algorithms and data structures, defining algorithms as structured sequences of steps to solve problems and data structures as methods for organizing data effectively. It discusses the correlation between algorithms and data structures, highlighting the importance of data structure in optimizing algorithm implementation. Additionally, it covers algorithm characteristics, basic constructions, examples, and notation methods such as flowcharts and pseudocode.