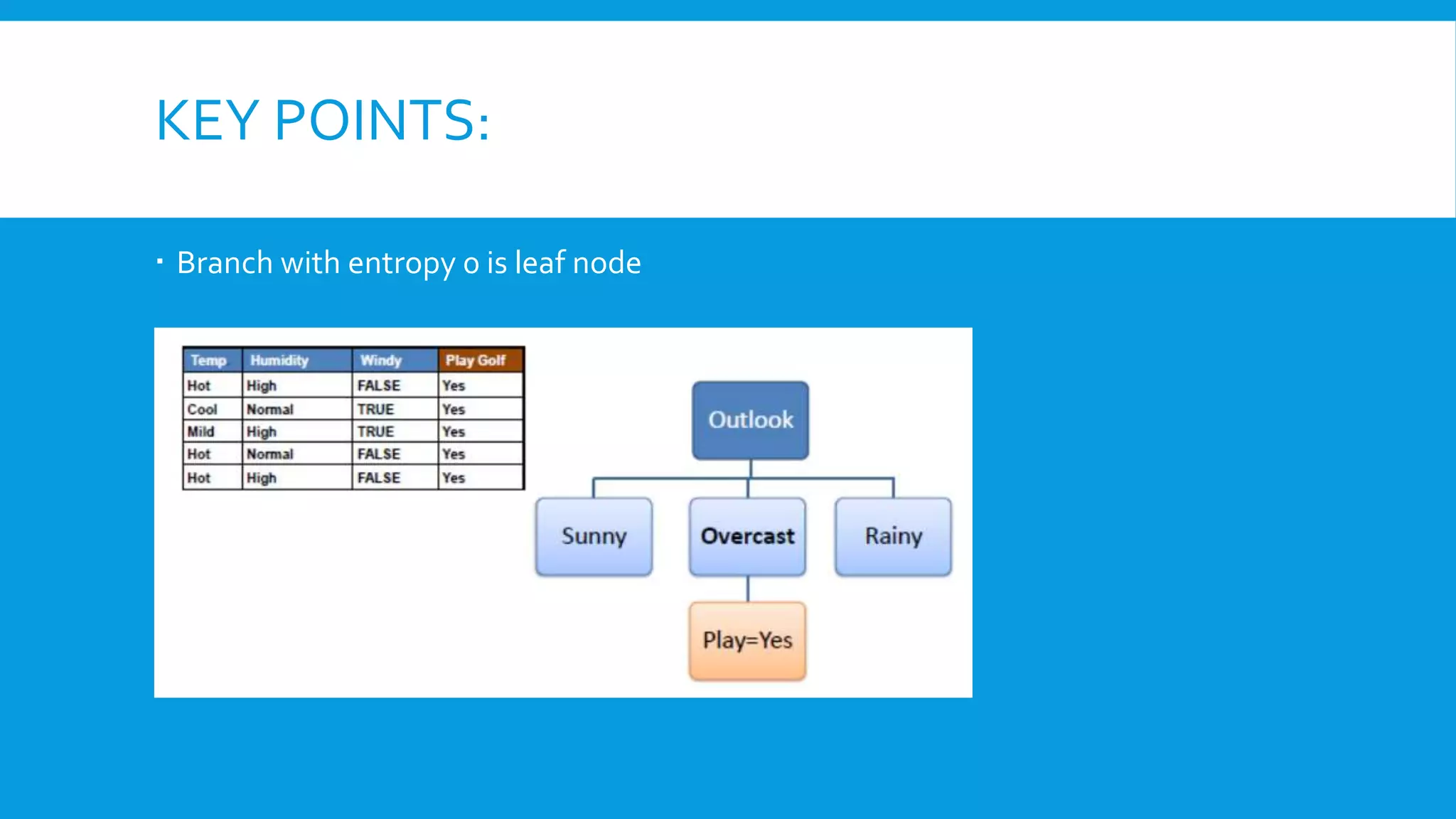
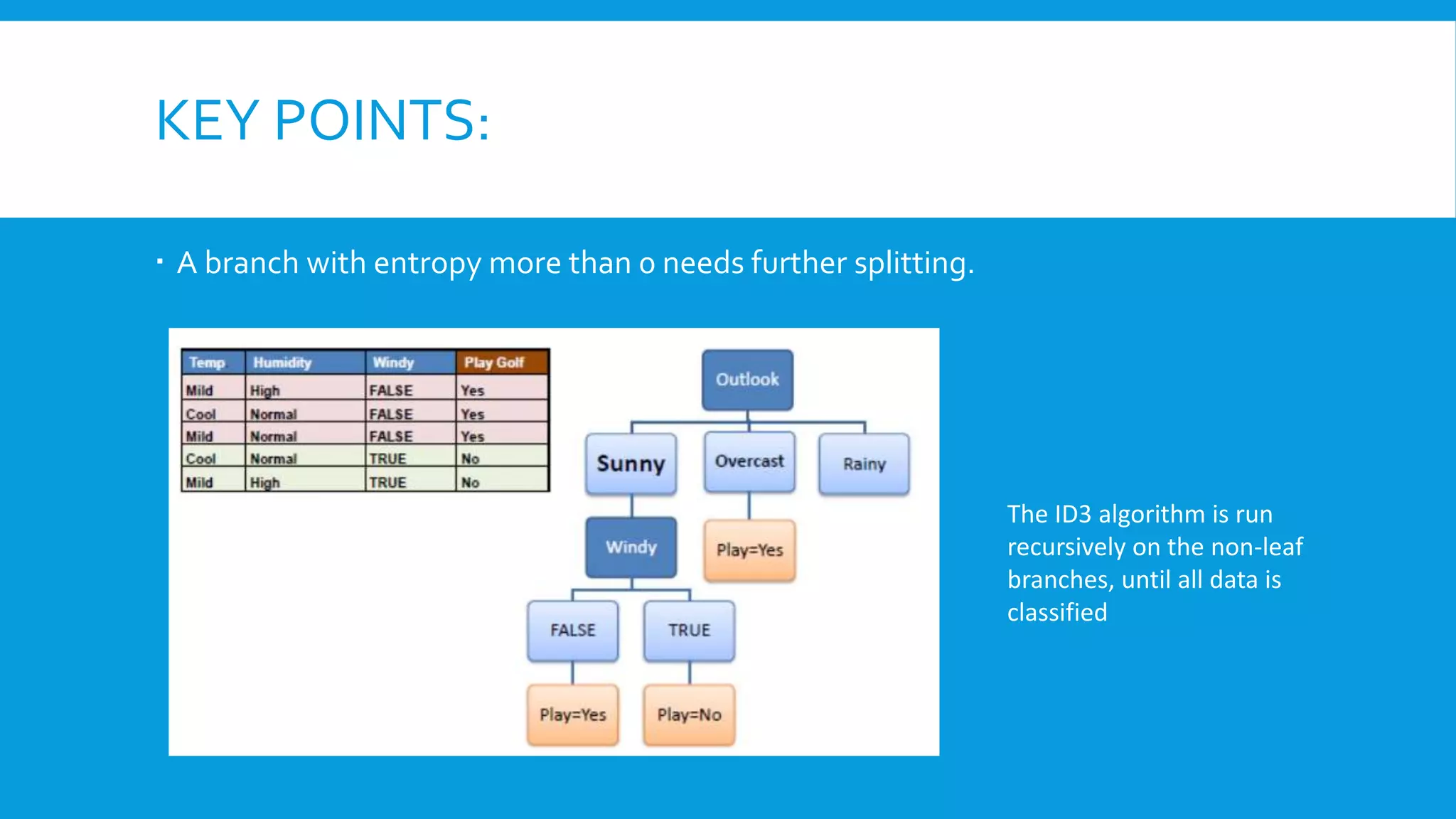
Downloaded 85 times














![NEARZEROVARIANCE
data(mdrr)
data.frame(table(mdrrDescr$nR11))
nzv <- nearZeroVar(mdrrDescr, saveMetrics= TRUE)
nzv[nzv$nzv,][1:10,]
dim(mdrrDescr)
nzv <- nearZeroVar(mdrrDescr)
filteredDescr <- mdrrDescr[, -nzv]
dim(filteredDescr)](https://image.slidesharecdn.com/dimensionreductionv1-150905132343-lva1-app6891/75/Dimension-Reduction-What-Why-and-How-16-2048.jpg)














![R CODE
w <- read.csv("weather.csv",header=T)
library(randomForest)
set.seed(12345)
w <- as.data.frame(w)
w <- read.csv("weather.csv",header=T)
str(w)
w <- w[names(w)[1:5]]
fit1 <- randomForest(Play~ Outlook+Temperature+Humidity+Windy, data=w,
importance=TRUE, ntree=20)
varImpPlot(fit1)](https://image.slidesharecdn.com/dimensionreductionv1-150905132343-lva1-app6891/75/Dimension-Reduction-What-Why-and-How-36-2048.jpg)


















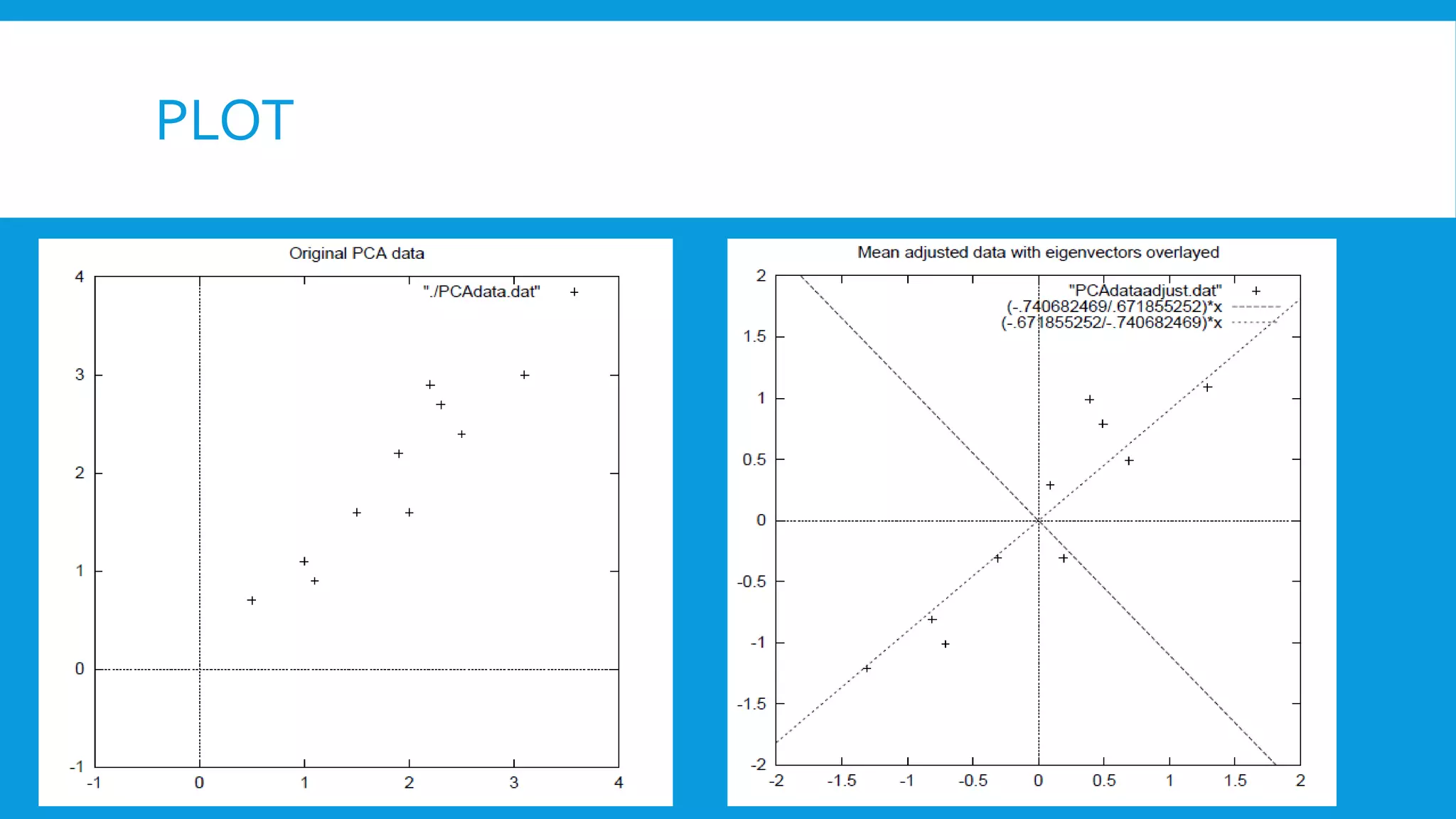


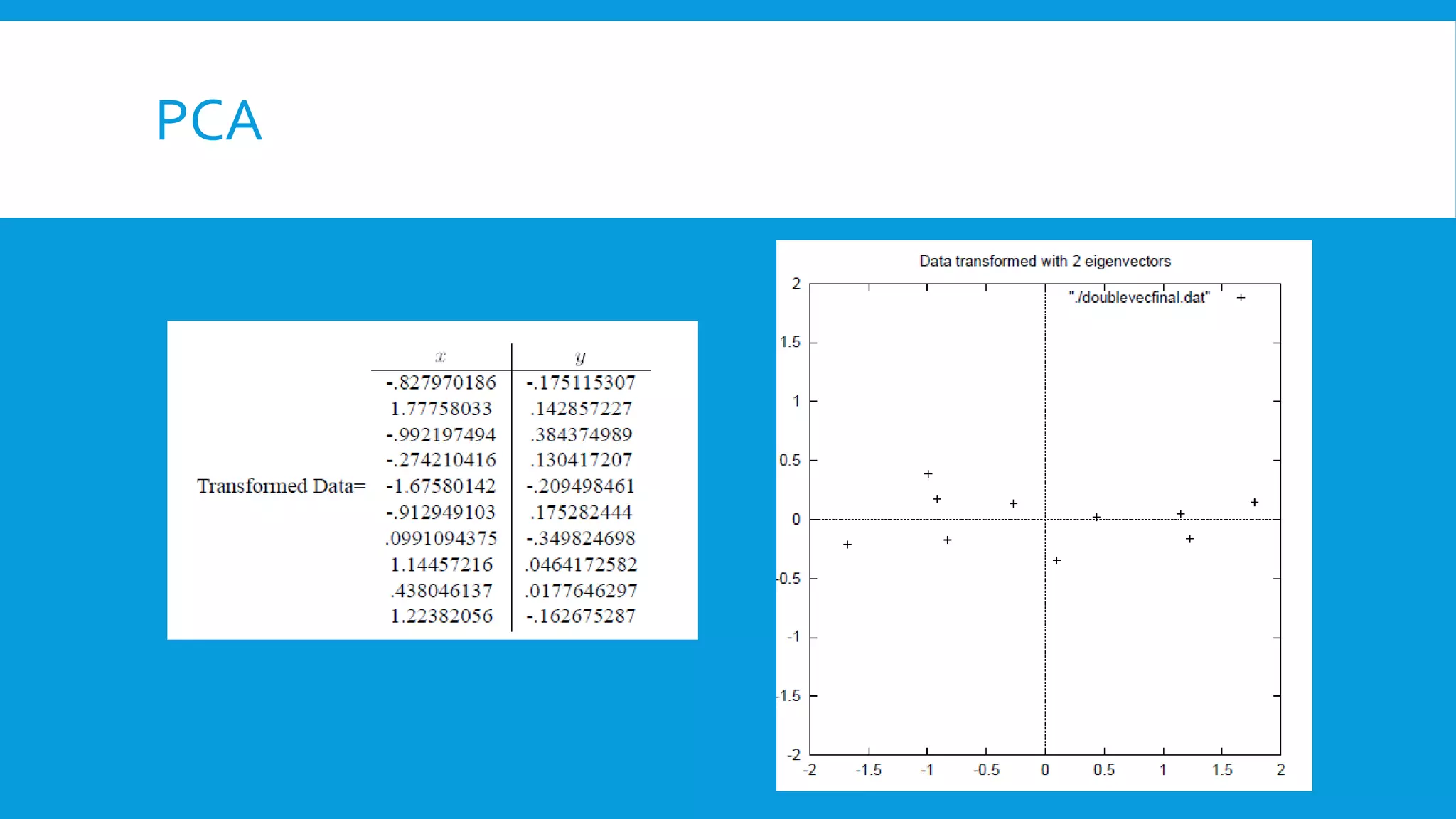


The document discusses dimension reduction, which is the process of reducing the number of features in a dataset while retaining its essential information, primarily to combat the 'curse of dimensionality' that leads to increased complexity and sparsity in data. It explains various techniques for dimension reduction, such as feature selection, PCA, and decision trees, noting advantages like improved model performance and reduced noise. Additionally, the document addresses issues such as multicollinearity and the importance of handling missing values and low-variance predictors in data preprocessing.




















![Dimension reduction techniques[Feature Selection]](https://cdn.slidesharecdn.com/ss_thumbnails/dimensionreductiontechnibyaakankshajain-210625102243-thumbnail.jpg?width=640&height=640&fit=bounds)














































