Download as PDF, PPTX










![SIGGRAPH 2019 | LOS ANGLES | 28 JULY - 1 AUGUST
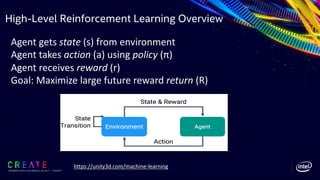
Optimizing the Software Stack - 1
ØRe-evaluating libraries included in software stack for DeepMimic
• Recompiling Tensorflow* with Intel® MKLDNN
bazel --output_base=output_dir build --config=mkl --config=opt
//tensorflow/tools/pip_package:build_pip_package
python -c "import tensorflow; print(tensorflow.pywrap_tensorflow.IsMklEnabled())“ à Result : True
• Evaluate different threading parameters to reduce spin time
import tensorflow # this sets KMP_BLOCKTIME and OMP_PROC_BIND
import os # delete the existing values
del os.environ['OMP_PROC_BIND’]
del os.environ['KMP_BLOCKTIME’]
ØMoving Python installation à Optimize Intel Python libraries
• Simple optimizations by moving numpy libraries to more efficient Intel
Numpy libraries](https://image.slidesharecdn.com/bringintelligentmotionusingreinforcementlearning-190813170339/85/Bring-Intelligent-Motion-Using-Reinforcement-Learning-Engines-SIGGRAPH-2019-Technical-Sessions-14-320.jpg)






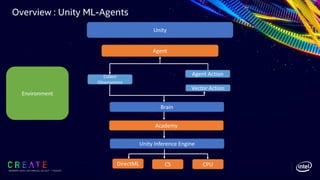









The document discusses the application of reinforcement learning (RL) in gaming and motion optimization, focusing on various RL algorithms, training techniques, and the use of Intel CPUs and DirectML for enhanced performance. It highlights the importance of optimizing software stacks, libraries, and data types to improve training efficiency by 2.6x and the role of Unity ML Agents in bridging the gap between academic research and practical game integration. Additionally, it emphasizes leveraging Intel's technology to achieve significant boosts in both training and inference performance for machine learning applications in game development.




















































































