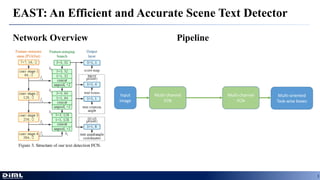
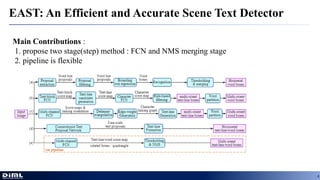
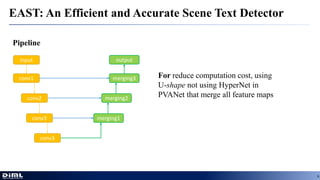
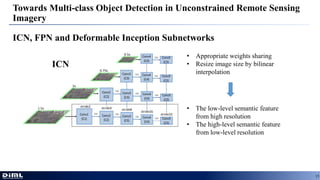
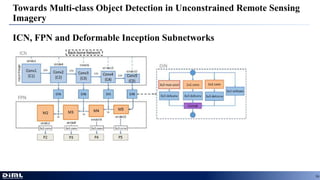
The document discusses advancements in aerial object detection, highlighting two main approaches: EAST for efficient scene text detection and a multi-class object detection framework for unconstrained remote sensing imagery. It details methodologies such as a two-stage pipeline, label generation techniques, and the use of a locality-aware NMS for improved accuracy. Additionally, it introduces a new joint image cascade and feature pyramid network, alongside a domain adaptation module and specialized loss functions for optimizing rectangular outputs.



























![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)

![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PaperReview] LightGCN: Simplifying and Powering Graph Convolution Network fo...](https://cdn.slidesharecdn.com/ss_thumbnails/lightgcn-211217151725-thumbnail.jpg?width=640&height=640&fit=bounds)
























































