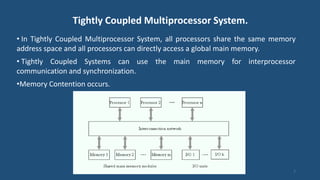
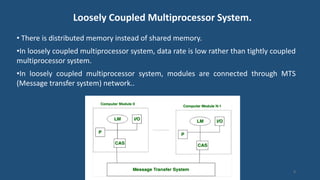
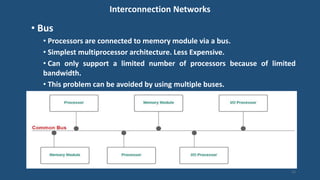
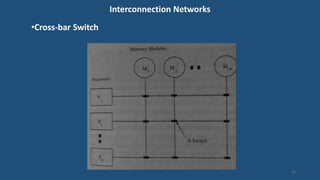
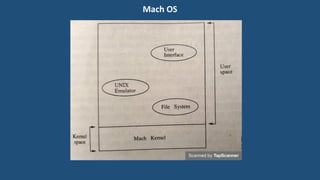
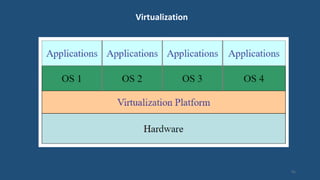
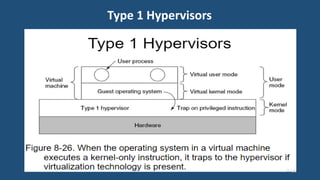
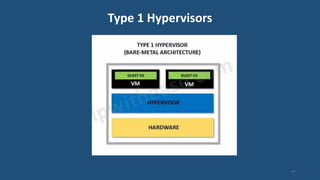
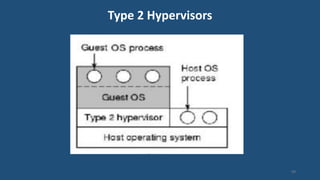
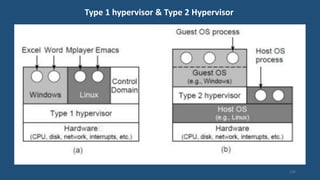
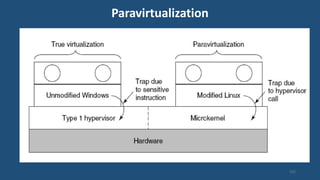
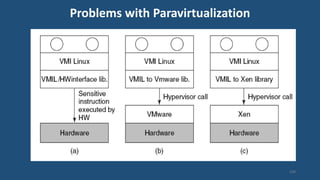
This document discusses multiprocessor operating systems. It covers basic multiprocessor system architectures including tightly coupled, loosely coupled, UMA, NUMA, and NORMA systems. It also discusses interconnection networks like bus, crossbar switch, and multistage networks. Additionally, it summarizes the structures of basic multiprocessor operating systems including separate supervisor, master-slave, and symmetric models.