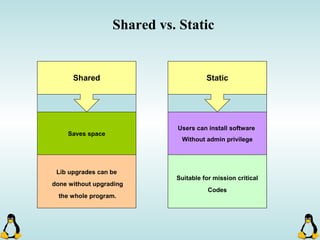
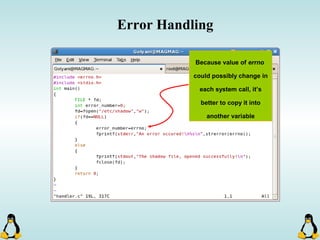
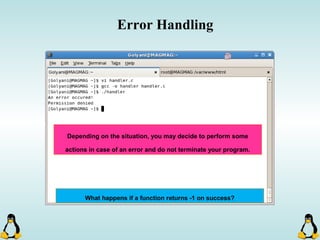
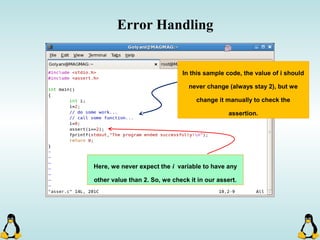
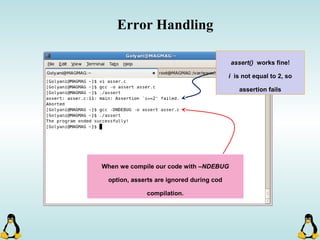
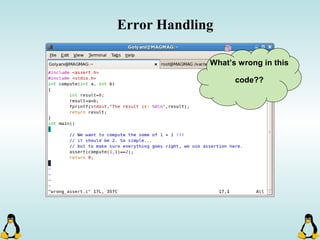
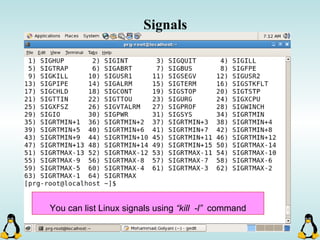
Downloaded 52 times


















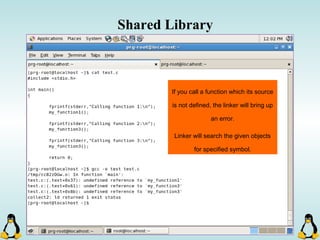








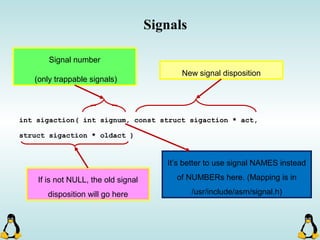











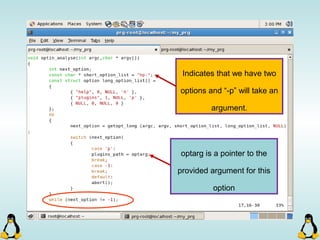
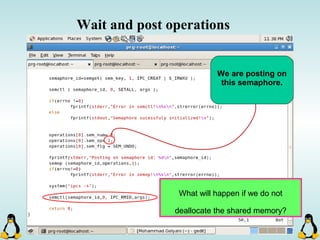
![Managing command-line arguments
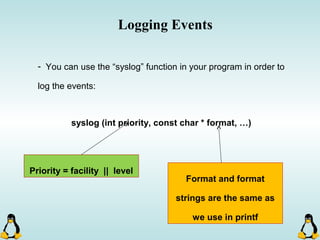
- By using getopt_long you can manage arguments passed to
your program.
- Traditional argc,argv[] method is also available.
- getopt_long will handle short options as well as long options.
- getopt_long will generate errors in case of bad options and
also will take care of options which require an arguments.
- getopt_long will need the argc , argv[] in order to work
properly.](https://image.slidesharecdn.com/advancedcprogramminginlinux-fin2-171227080848/85/Advanced-c-programming-in-Linux-68-320.jpg)
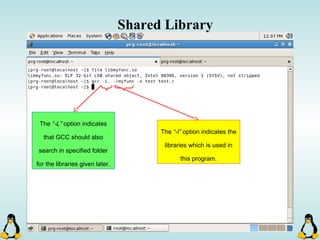
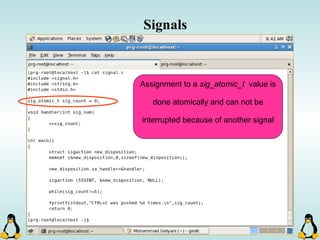
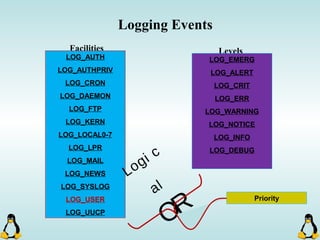
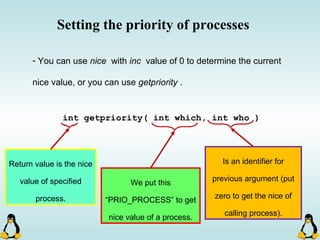
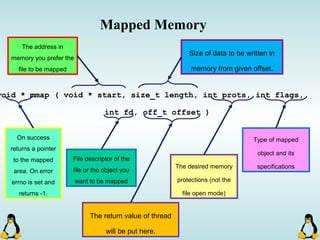
![Managing command-line arguments
int getopt_long( int argc, const char * argv[], const char * optstring,
const struct options * longopts, int * longindex )
- getopt_long will take lots of arguments!
This should be null or point to
index of long_options array.
This is an structure which is
filled with options declaration.
argc and argv[ ] !! Array of short options.](https://image.slidesharecdn.com/advancedcprogramminginlinux-fin2-171227080848/85/Advanced-c-programming-in-Linux-69-320.jpg)

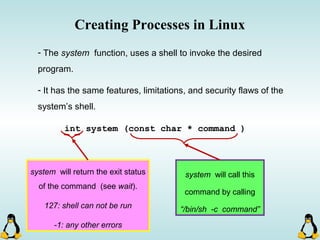
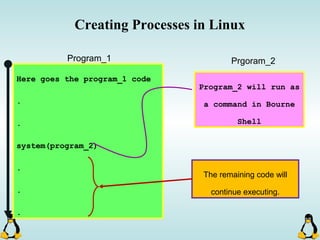
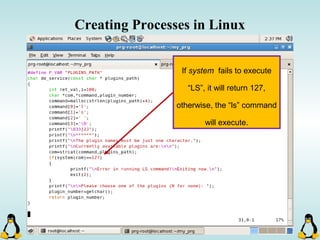

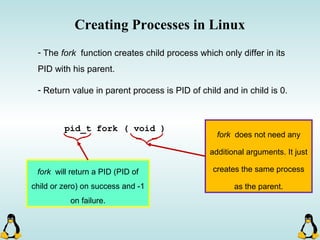
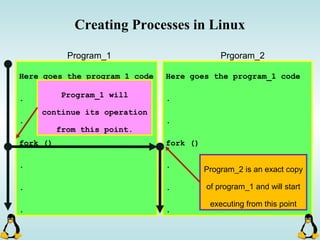
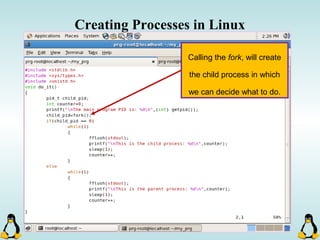

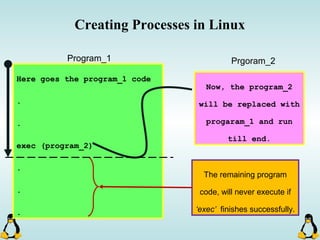
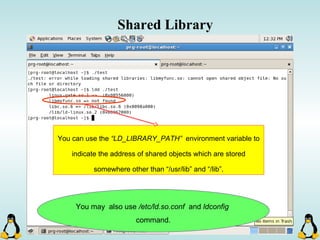
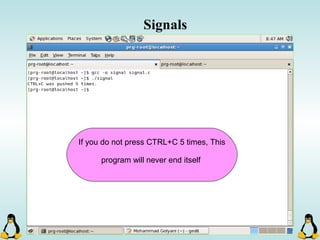
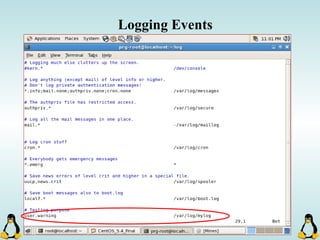
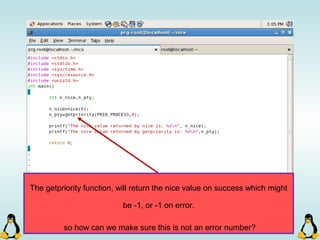
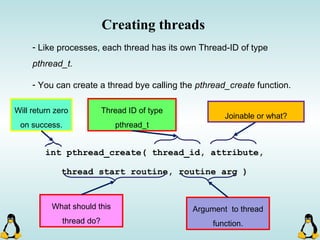
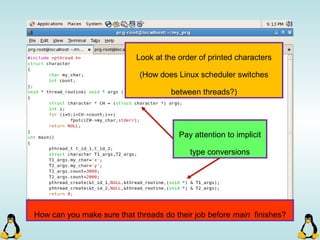
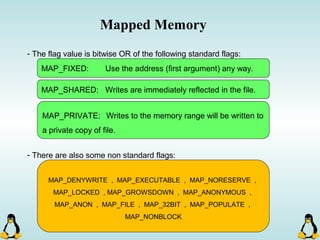
![Creating Processes in Linux
- All of the exec family of functions, use just one system call:
execve()
- execl() functions are variadic functions.
- When calling exec, remember that almost all Linux applications,
use argv[0] as their binary image name.
- When using exec family, the new process does not have the
previous’ signal handlers and other stuff.
- The new process has the same values for its PID, PPID, priority
and permissions.](https://image.slidesharecdn.com/advancedcprogramminginlinux-fin2-171227080848/85/Advanced-c-programming-in-Linux-81-320.jpg)
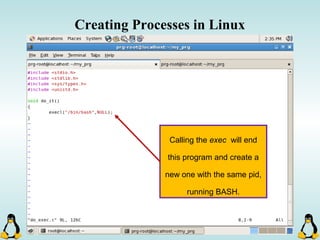




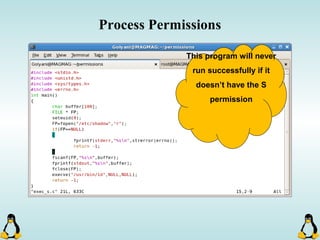





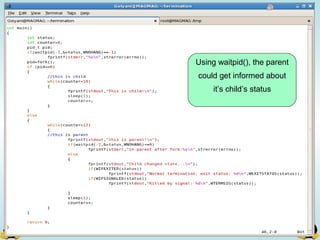

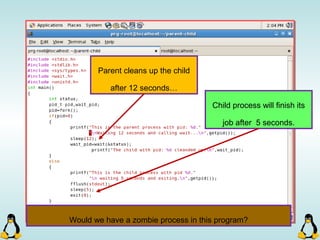



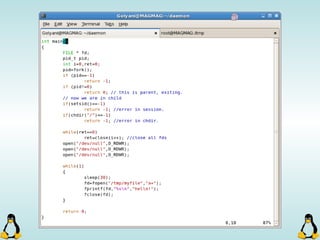





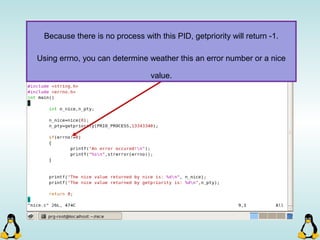

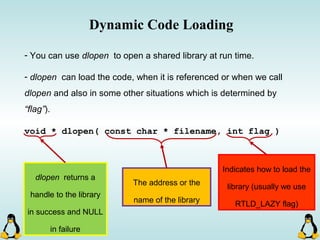
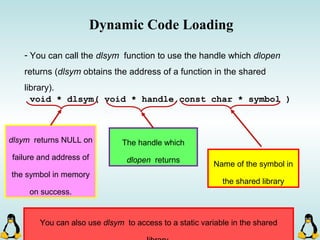

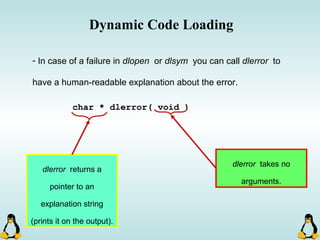
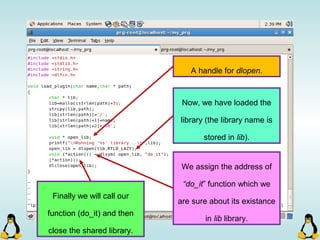

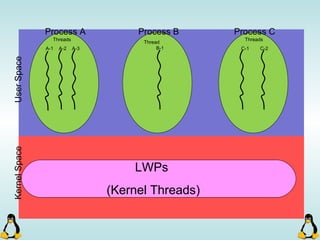


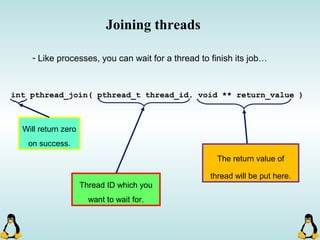
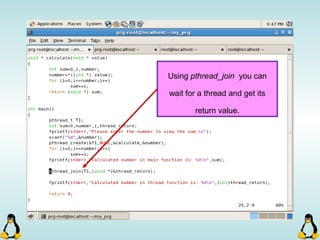


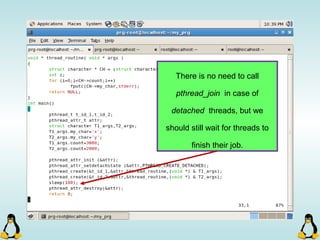


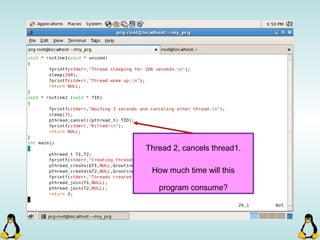
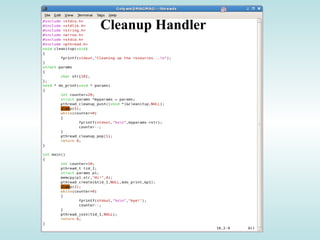


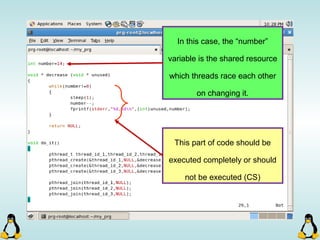



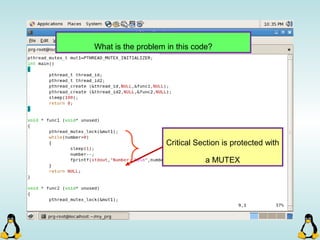

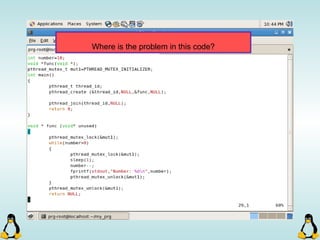


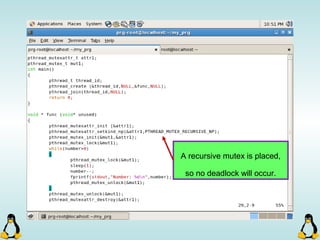





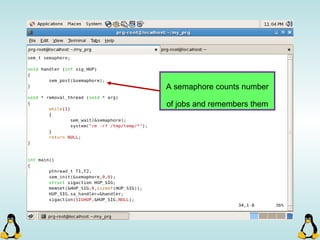





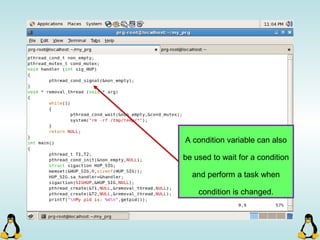







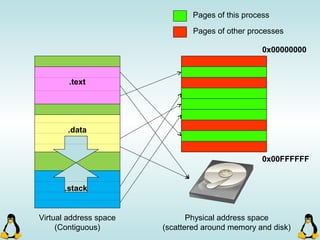

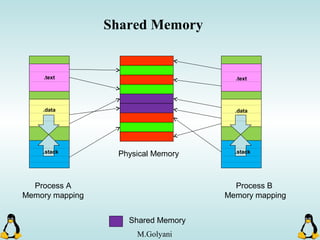





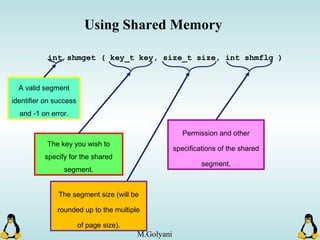

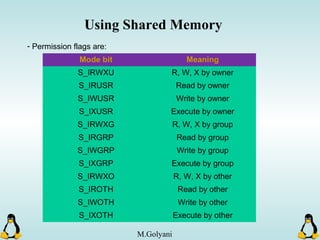
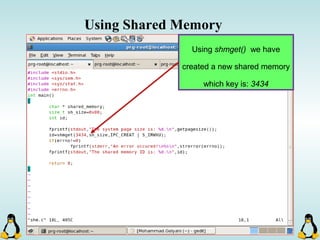
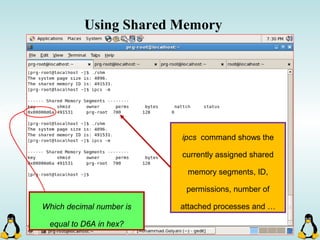

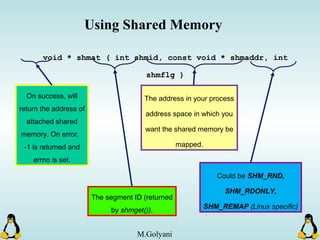
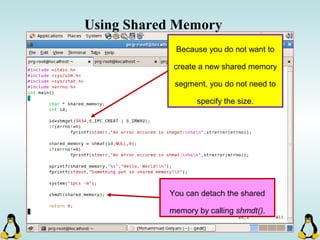
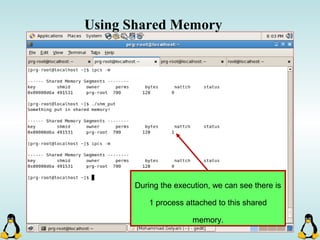

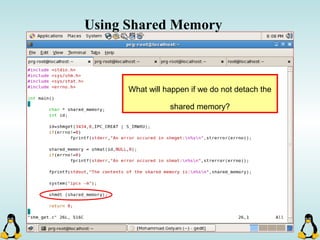

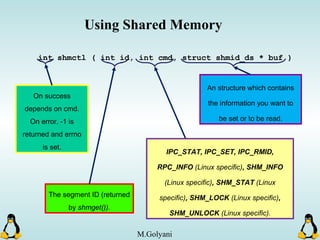



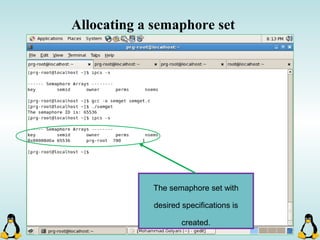

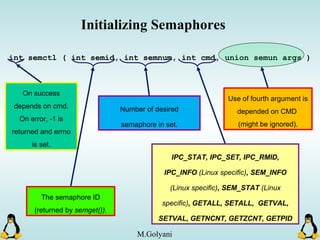

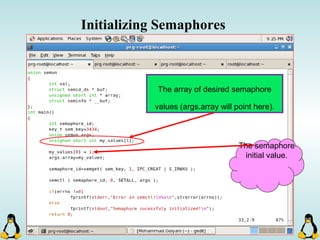

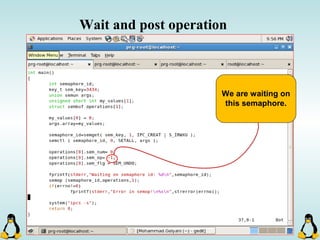


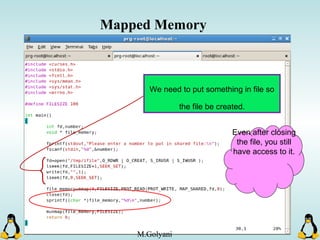



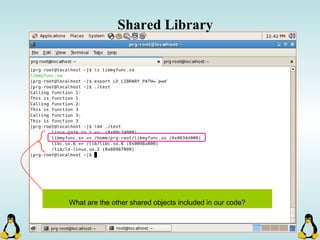
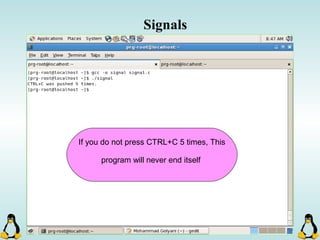
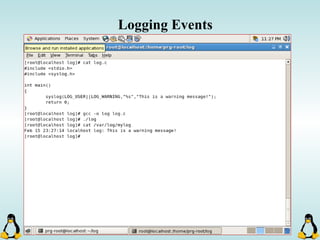
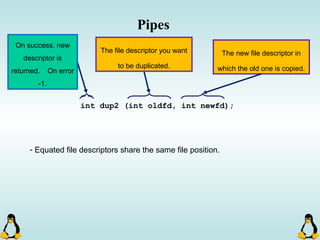
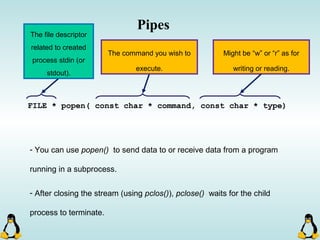
![Pipes
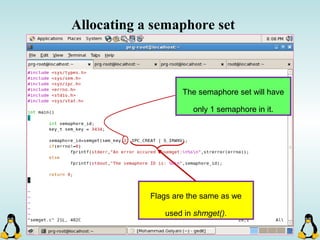
int pipe ( int filedes[2] );
An array of size 2, which
contains read and write file
descriptors.
On success, 0 is
returned and on
error, -1 is returned
and errno is set.
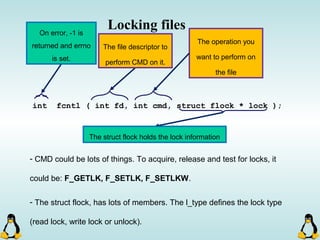
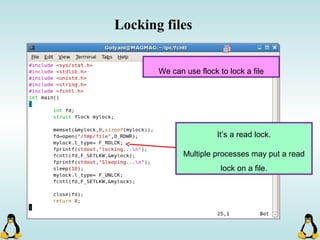
- pipe() stores the reading file descriptor in array position 0 and the writing
file descriptor in position 1.
- Read and write file descriptors are available only in calling process and its
children.
- You can use pipes to communicate between threads in a process.](https://image.slidesharecdn.com/advancedcprogramminginlinux-fin2-171227080848/85/Advanced-c-programming-in-Linux-206-320.jpg)
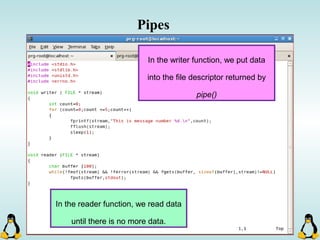
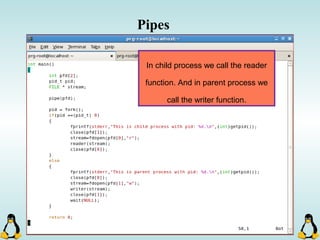
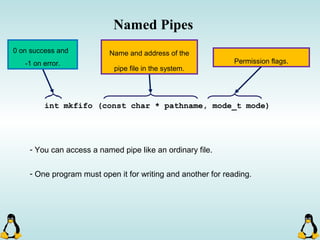

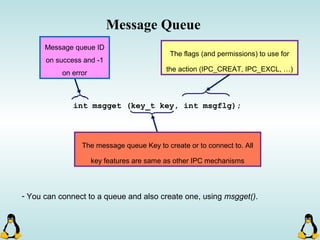
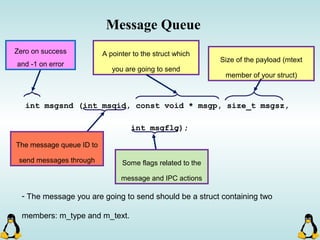
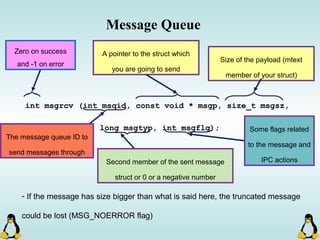
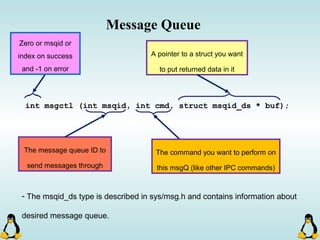


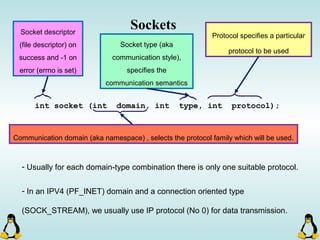


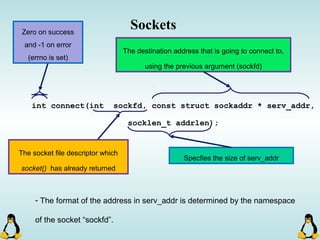
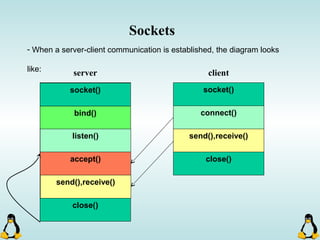
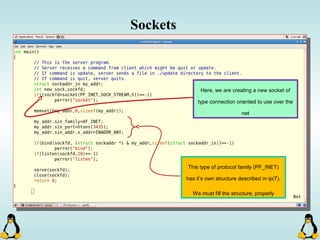
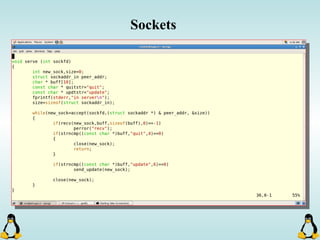
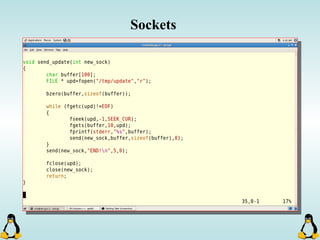
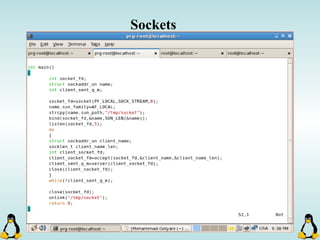
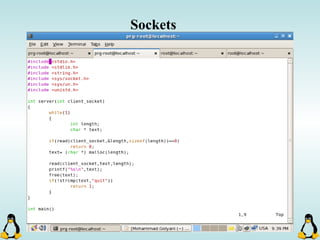

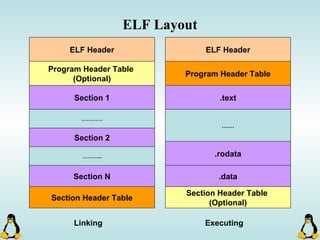
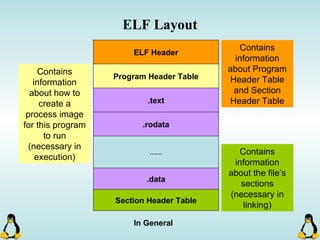
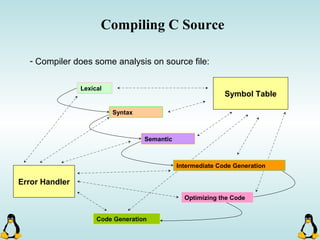
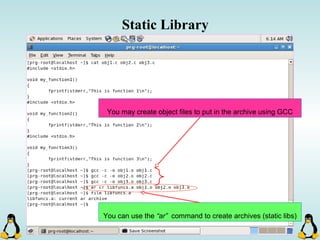
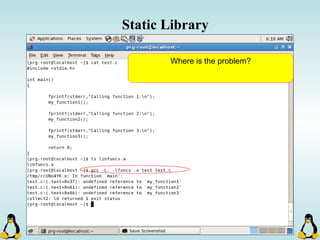
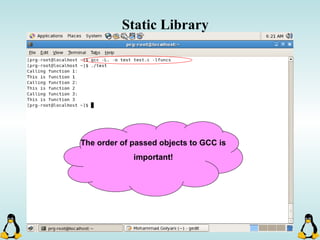
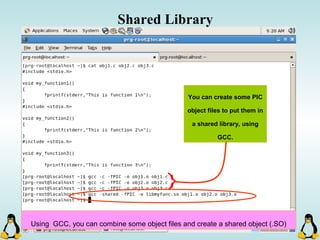
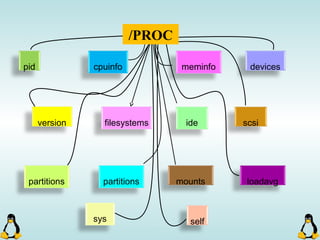
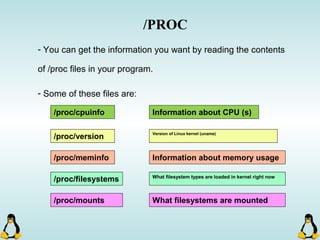
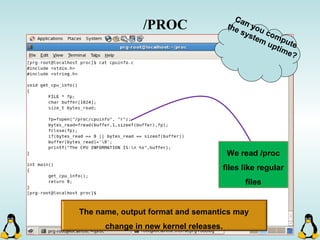
Linux executables are in ELF format. The document discusses Linux executable formats, compiling C programs in Linux using GCC, and executing programs. It also covers libraries in Linux including static and shared libraries, error handling using errno and assertions, signals and signal handling, process monitoring and /proc filesystem, and managing command line arguments using getopt_long.











































































