Downloaded 11 times








![Adapter
Implement SchemaFactory interface
Connect to a data source using
parameters
Extract schema - return a list of tables
Push down processing to the data source:
A set of planner rules
Calling convention (optional)
"schemas": [
{
"name": "HR",
"type": "custom",
"factory":
"org.apache.calcite.adapter.file.FileSchemaFactory",
"operand": {
"directory": "hr-csv"
}
}
]
$ ls -l hr-csv
-rw-r--r-- 1 jhyde staff 62 Mar 29 12:57 DEPTS.csv
-rw-r--r-- 1 jhyde staff 262 Mar 29 12:57 EMPS.csv.gz
$ ./sqlline -u jdbc:calcite:model=hr.json -n scott -p tiger
sqlline> select count(*) as c from emp;
'C'
'5'
1 row selected (0.135 seconds)](https://image.slidesharecdn.com/170517apechebigdataelilevine-170619222804/85/A-Smarter-Pig-Building-a-SQL-interface-to-Pig-using-Apache-Calcite-15-320.jpg)






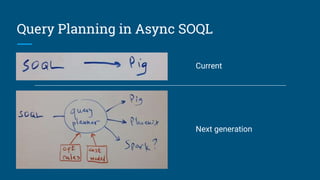
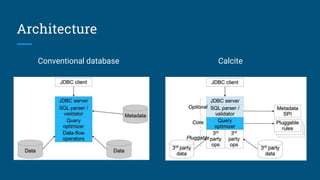
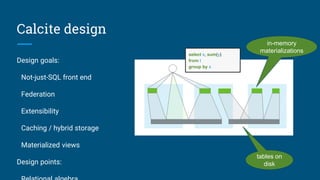
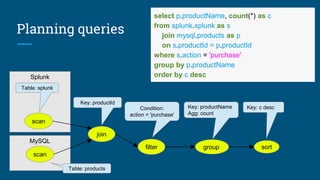
This document summarizes a presentation about building a SQL interface for Apache Pig using Apache Calcite. It discusses using Calcite's query planning framework to translate SQL queries into Pig Latin scripts for execution on HDFS. The presenters describe their work at Salesforce using Calcite for batch querying across data sources, and outline their process for creating a Pig adapter for Calcite, including implementing Pig-specific operators and rules for translation. Lessons learned include that Calcite provides flexibility but documentation could be improved, and examples from other adapters were helpful for their implementation.


















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)




