Downloaded 37 times








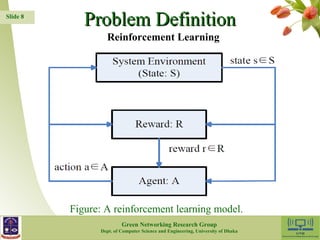


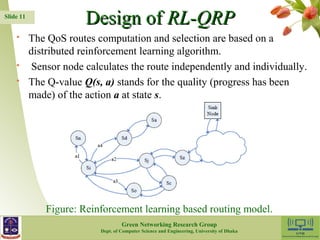





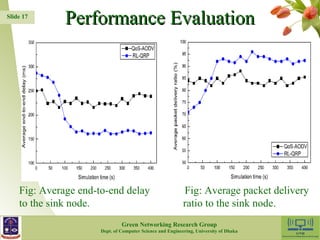
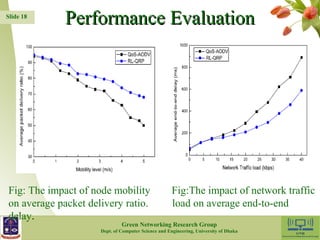



The document presents a reinforcement learning-based routing protocol (RL-QRP) designed for biomedical sensor networks, which allows for optimal routing policies without precise network state information. It discusses the challenges faced by existing QoS support routing protocols and provides insights into the implementation of a Q-learning approach for dynamic and mobile network environments. The performance evaluation demonstrates RL-QRP's effectiveness in terms of QoS metrics and energy efficiency, while also acknowledging limitations regarding certain QoS requirements and interactions between sensor nodes.
























![11.[1 5]comparative analysis of qo s-aware routing protocols for](https://cdn.slidesharecdn.com/ss_thumbnails/11-1-5comparativeanalysisofqos-awareroutingprotocolsfor-120512235326-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)

