Download as PDF, PPTX




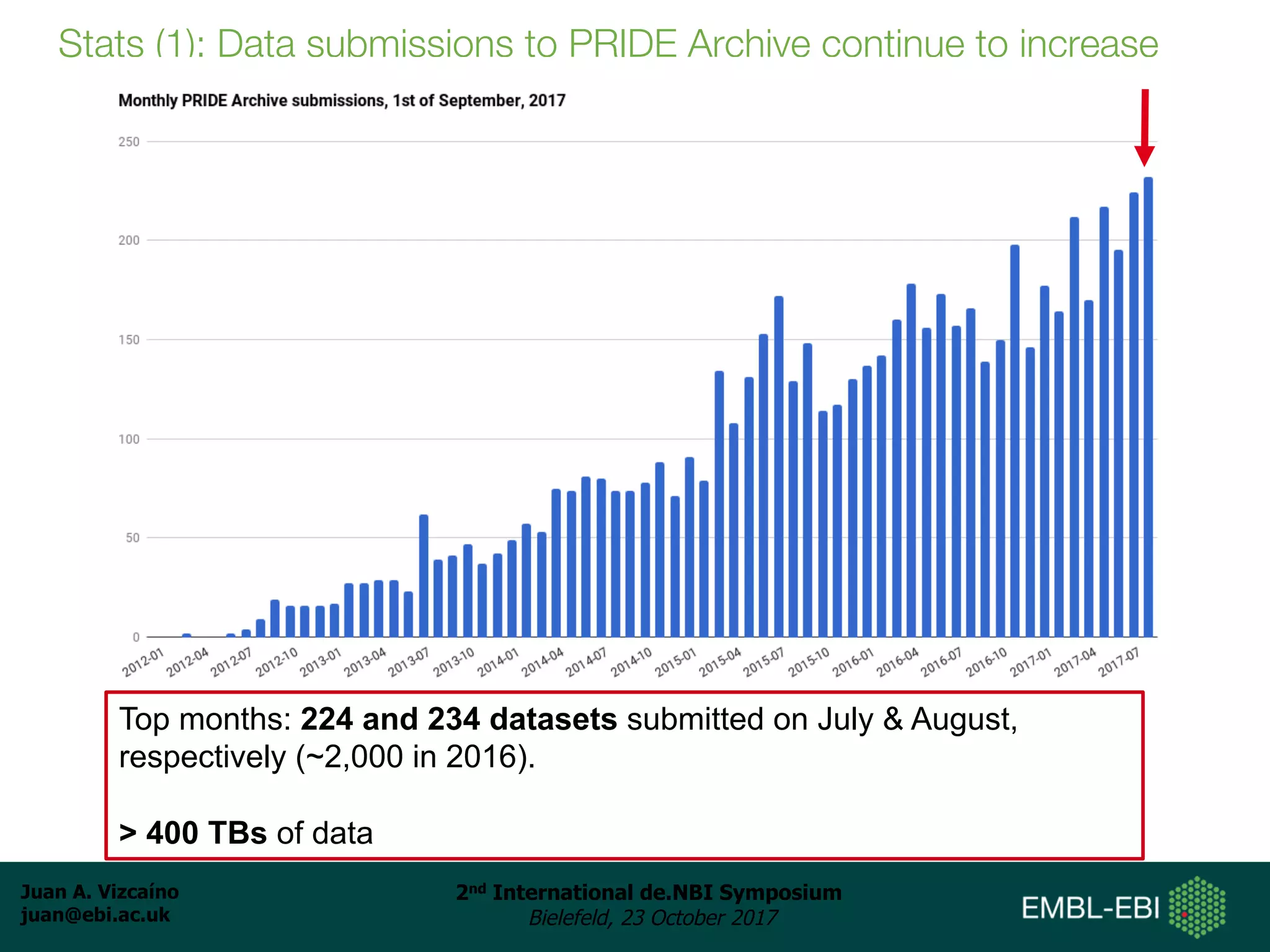
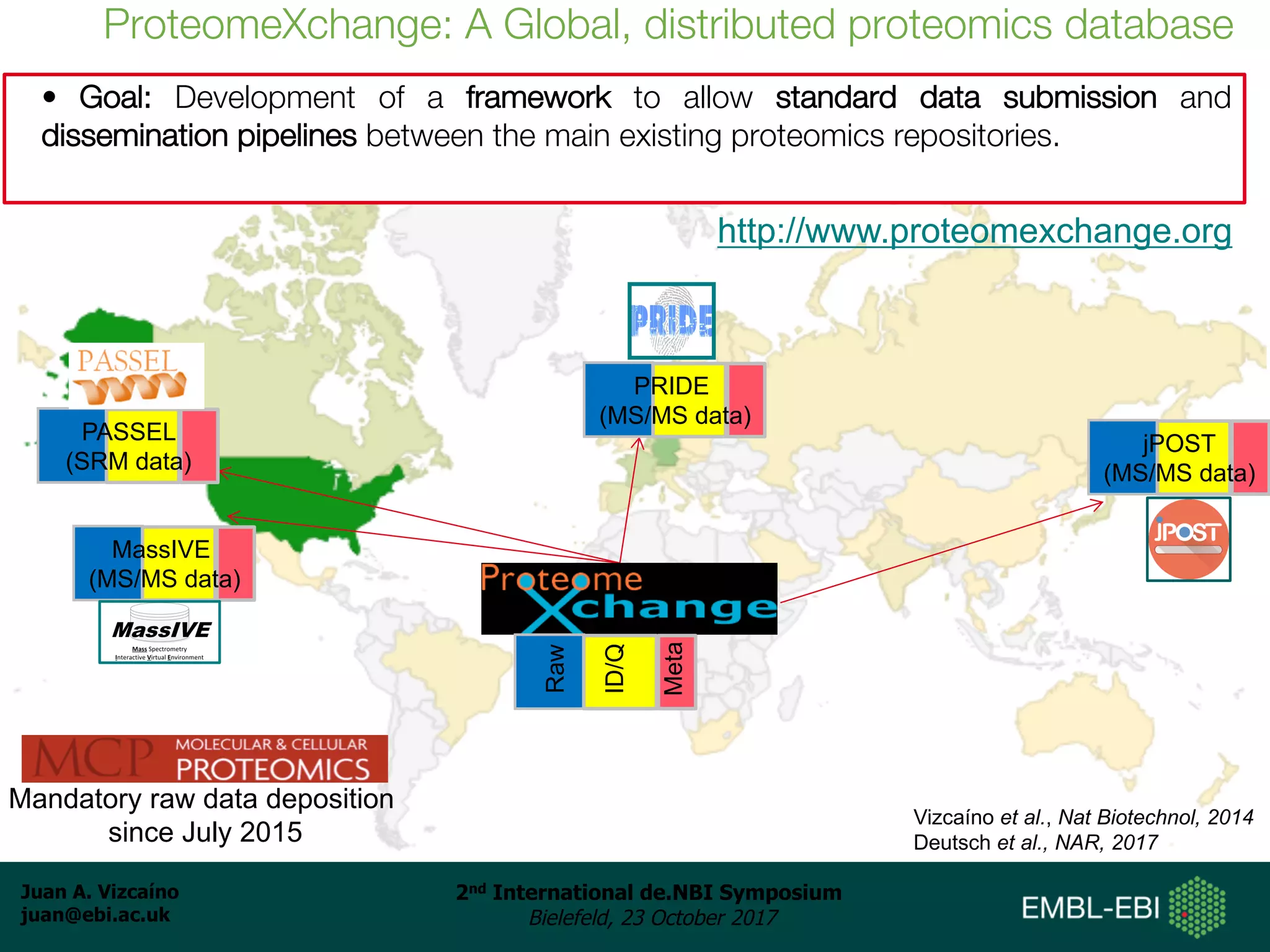
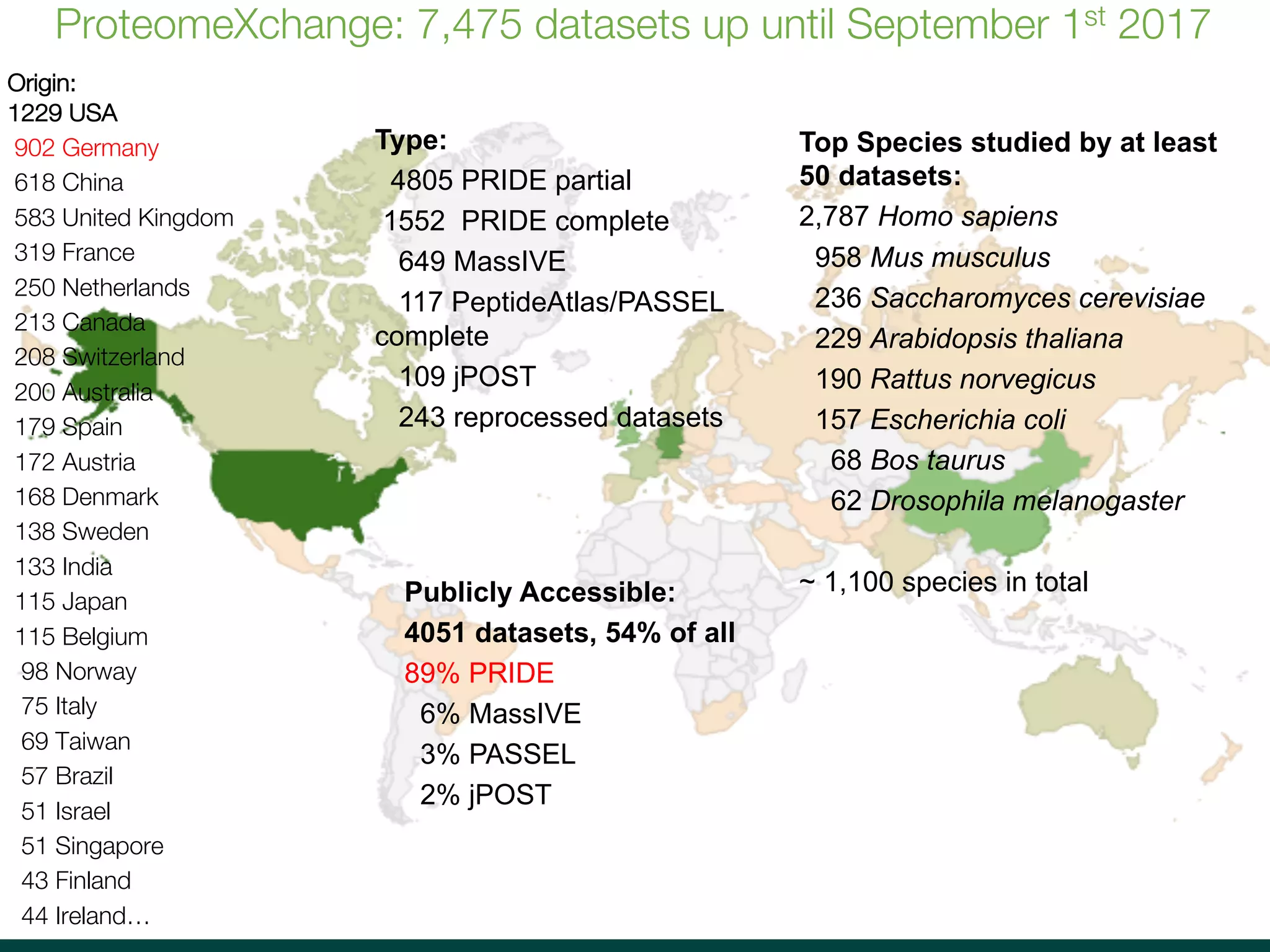
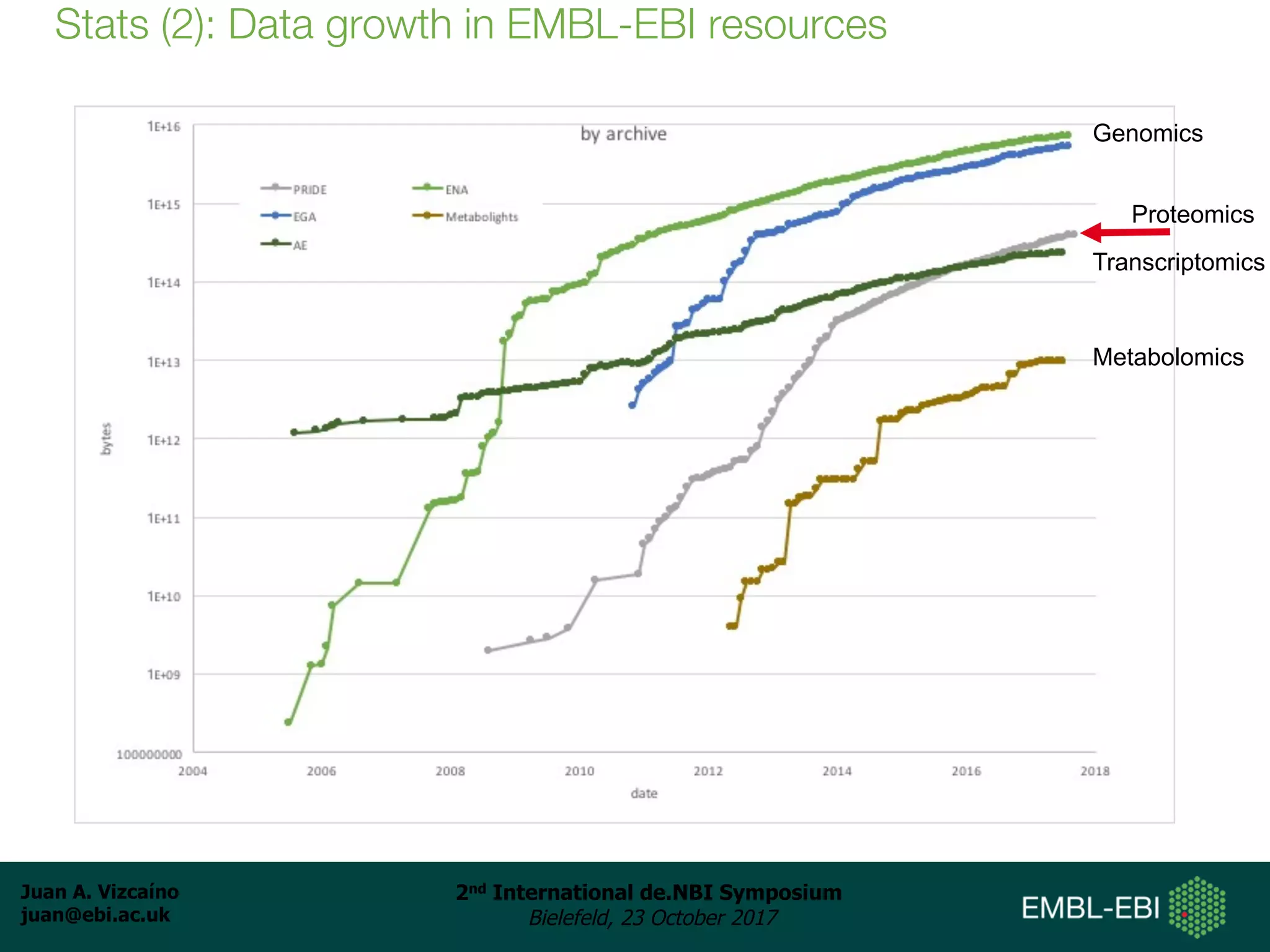

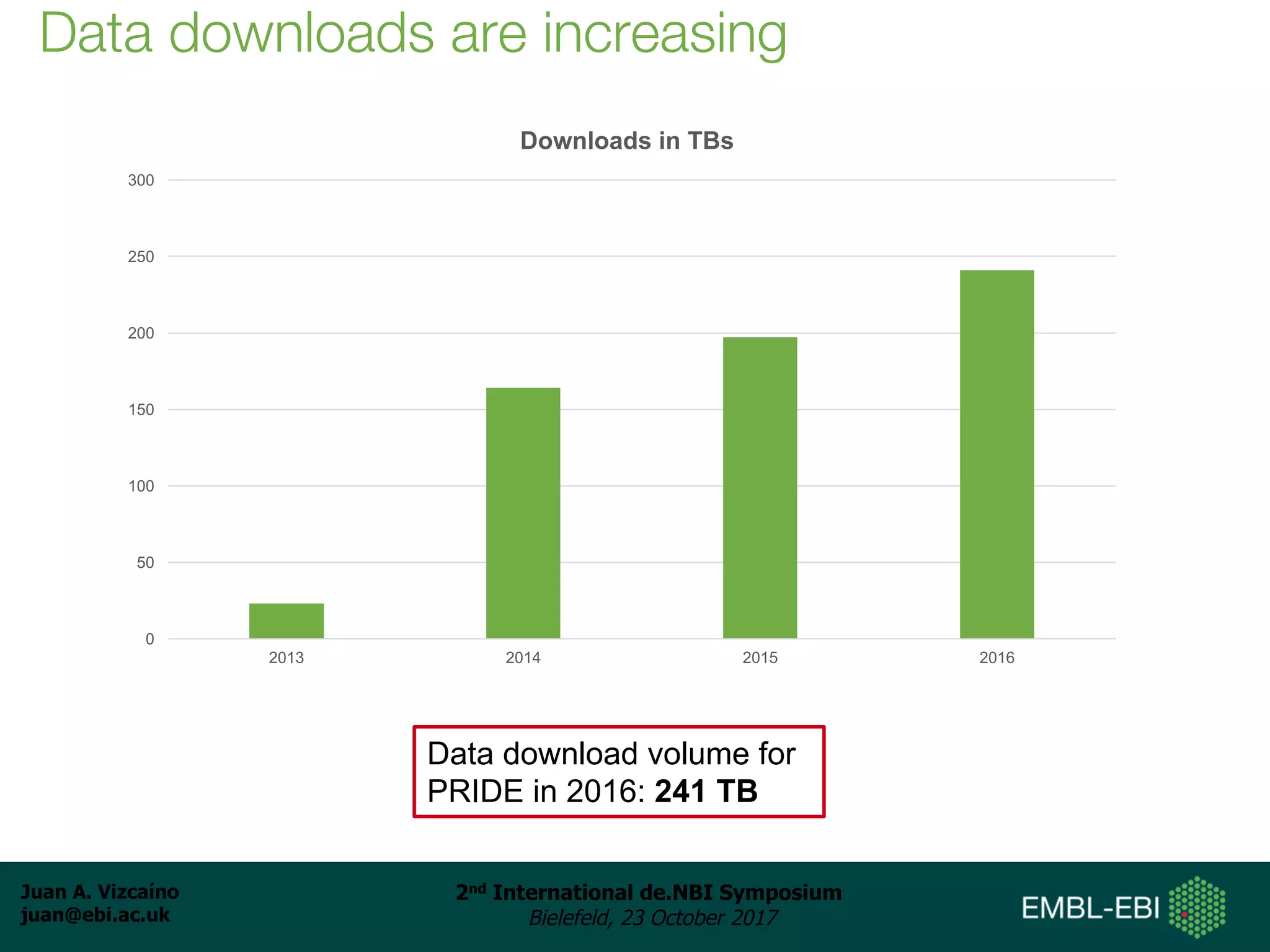


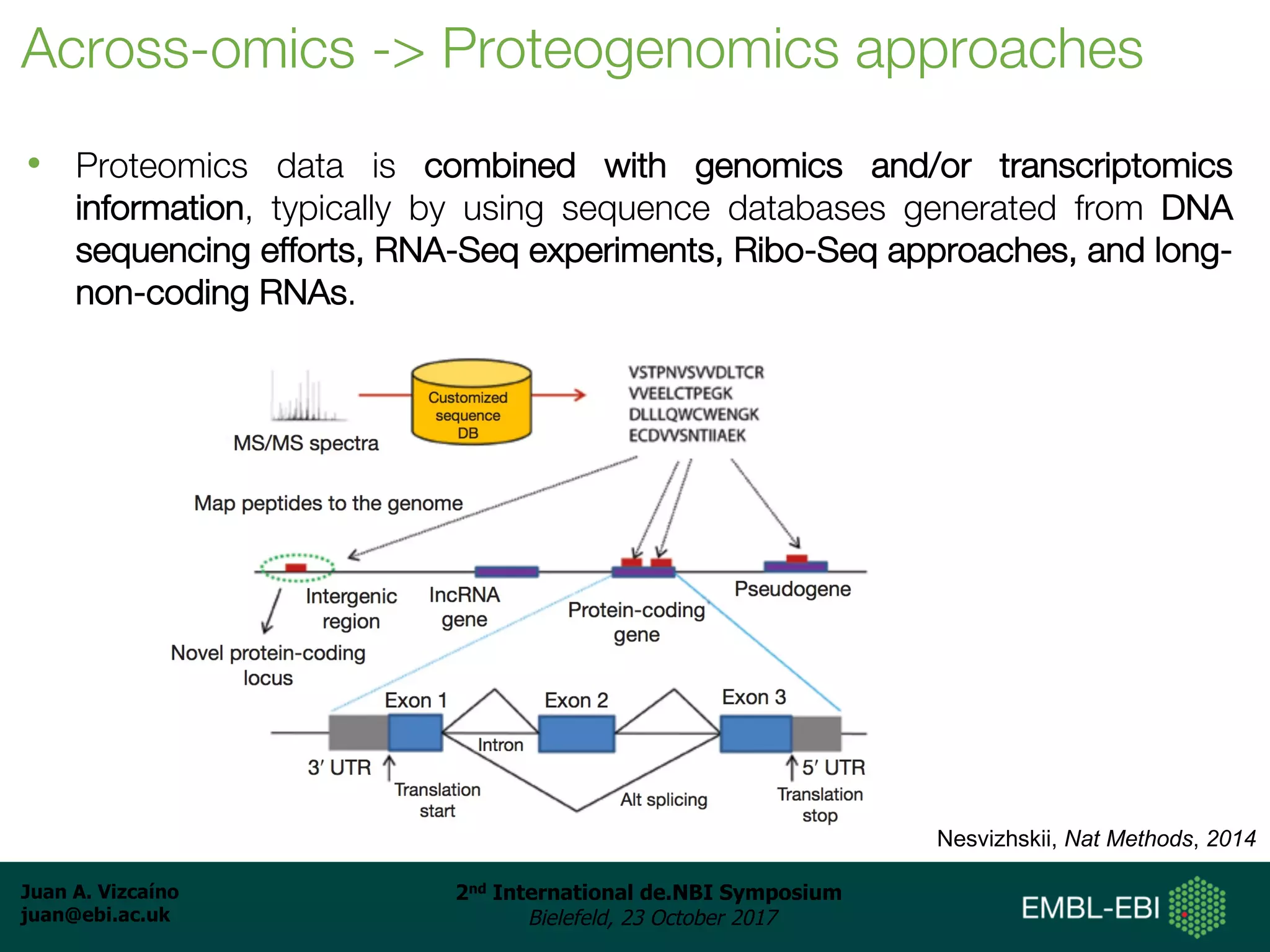
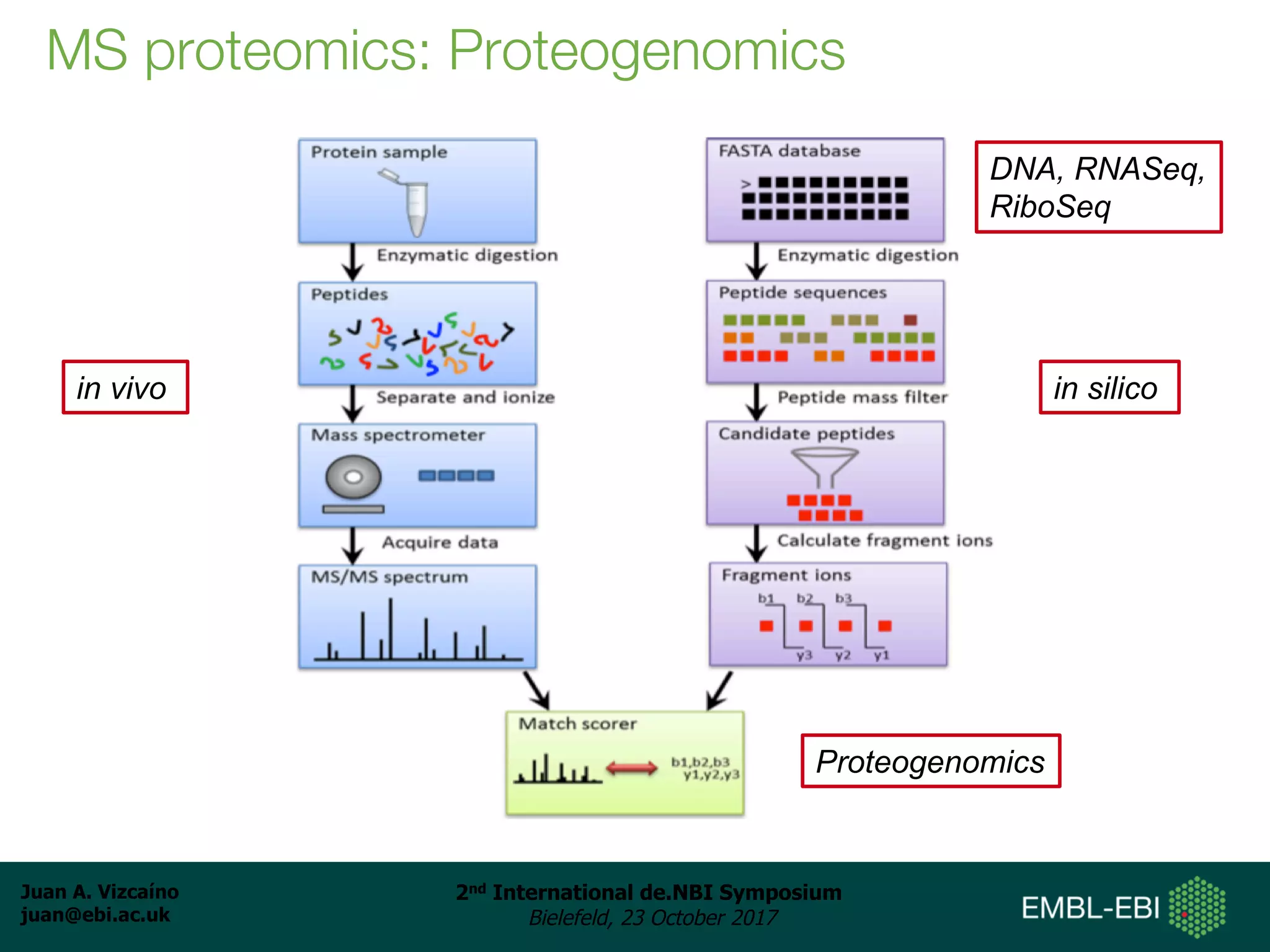


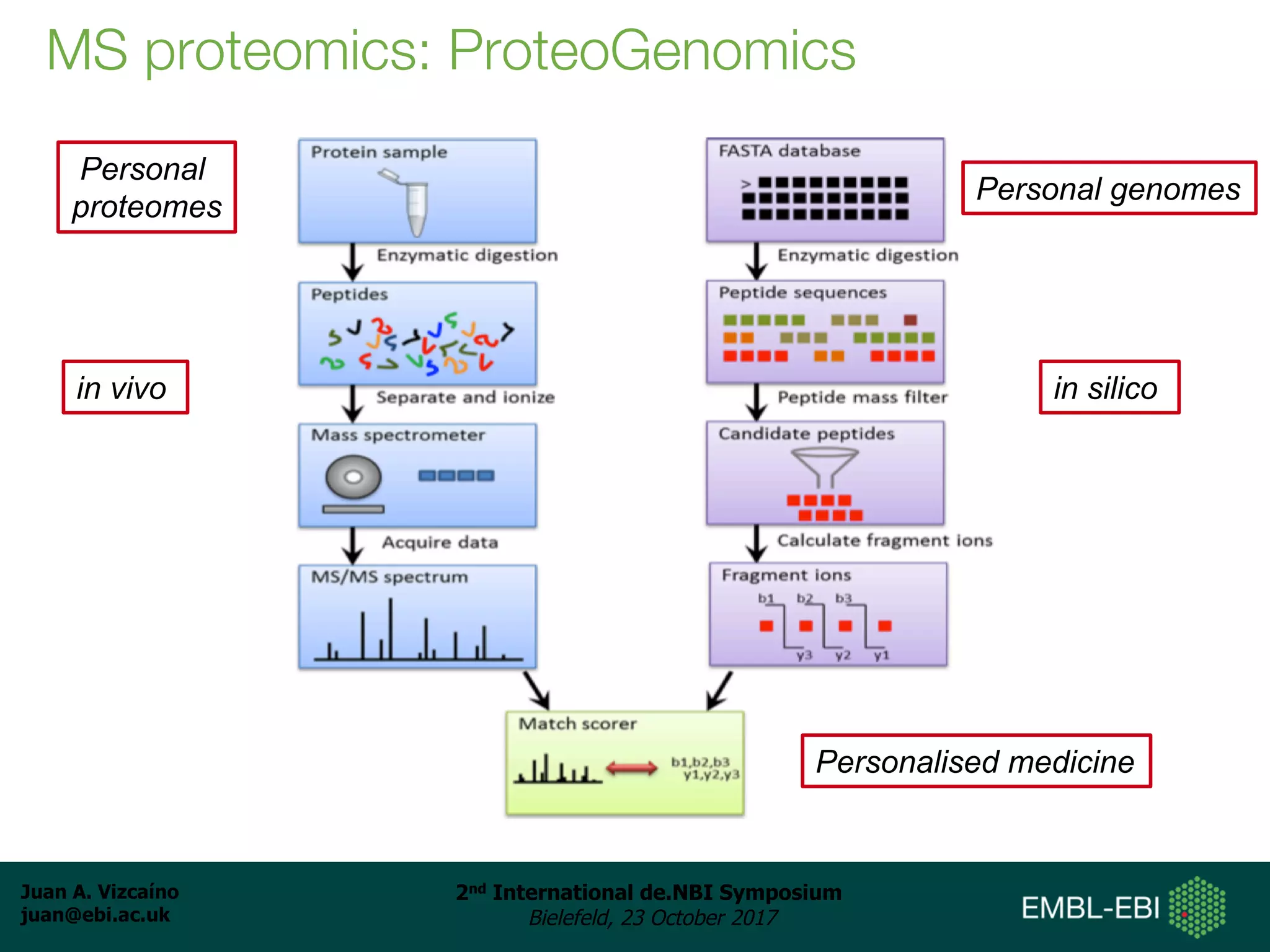
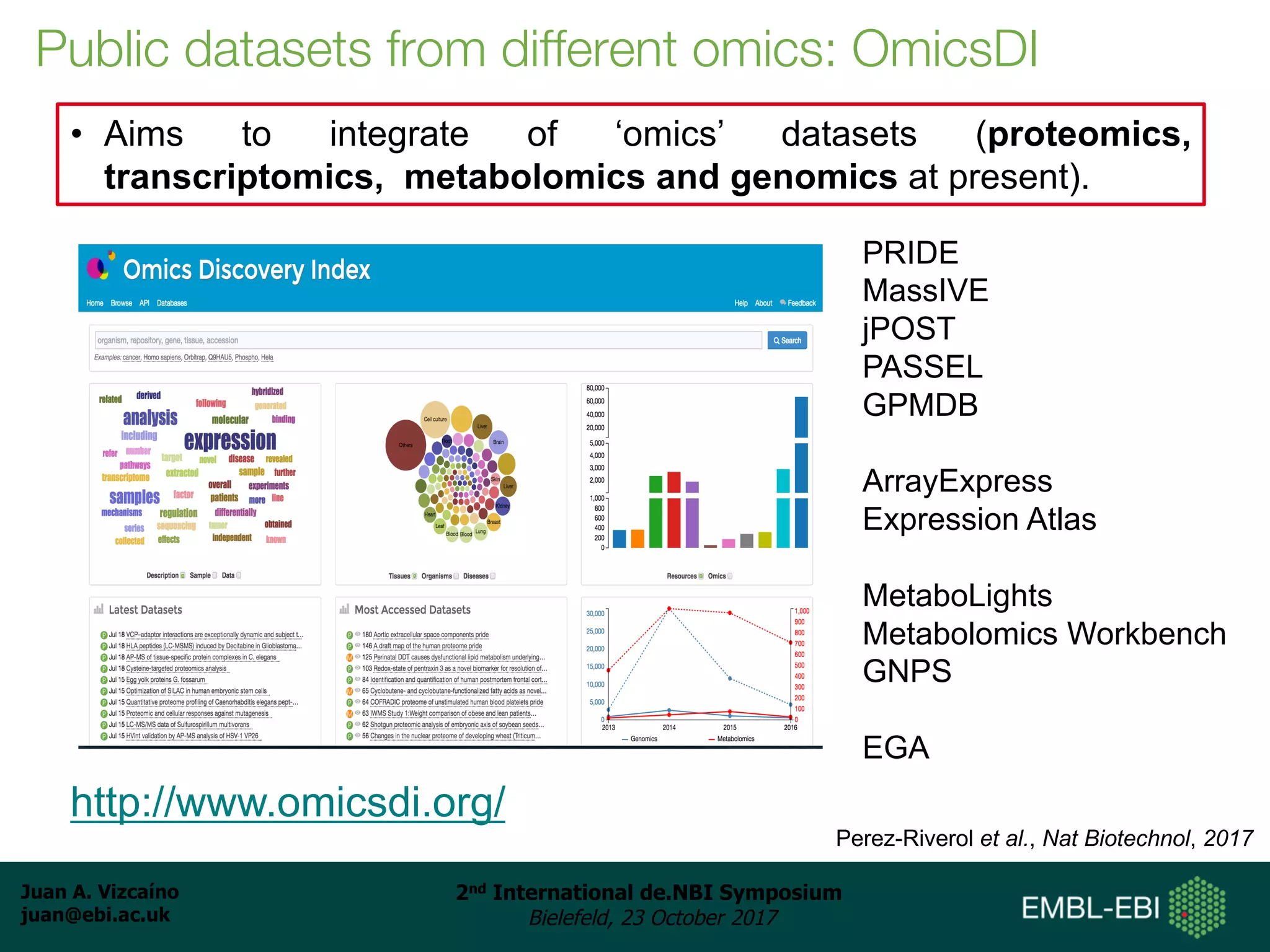





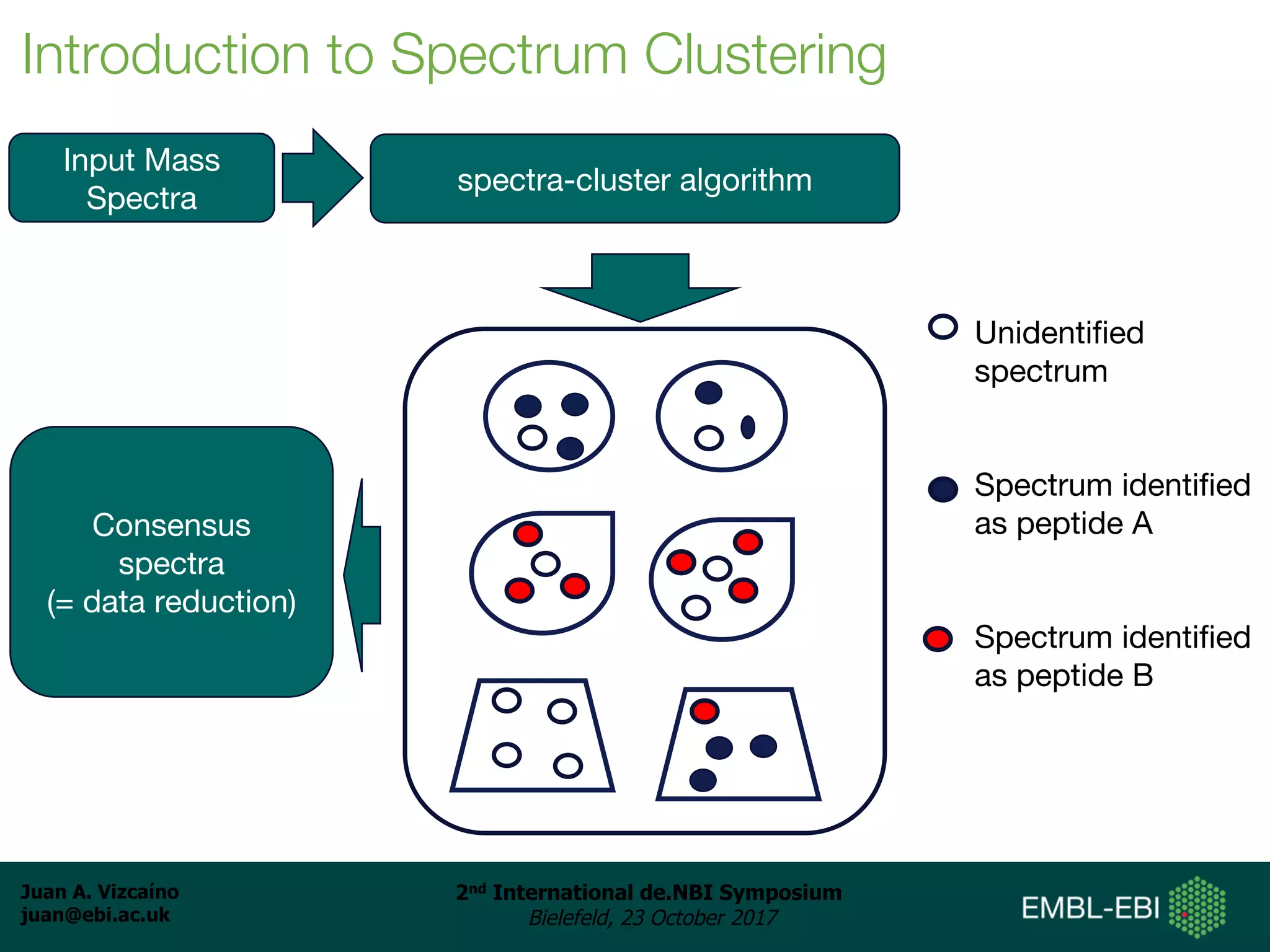

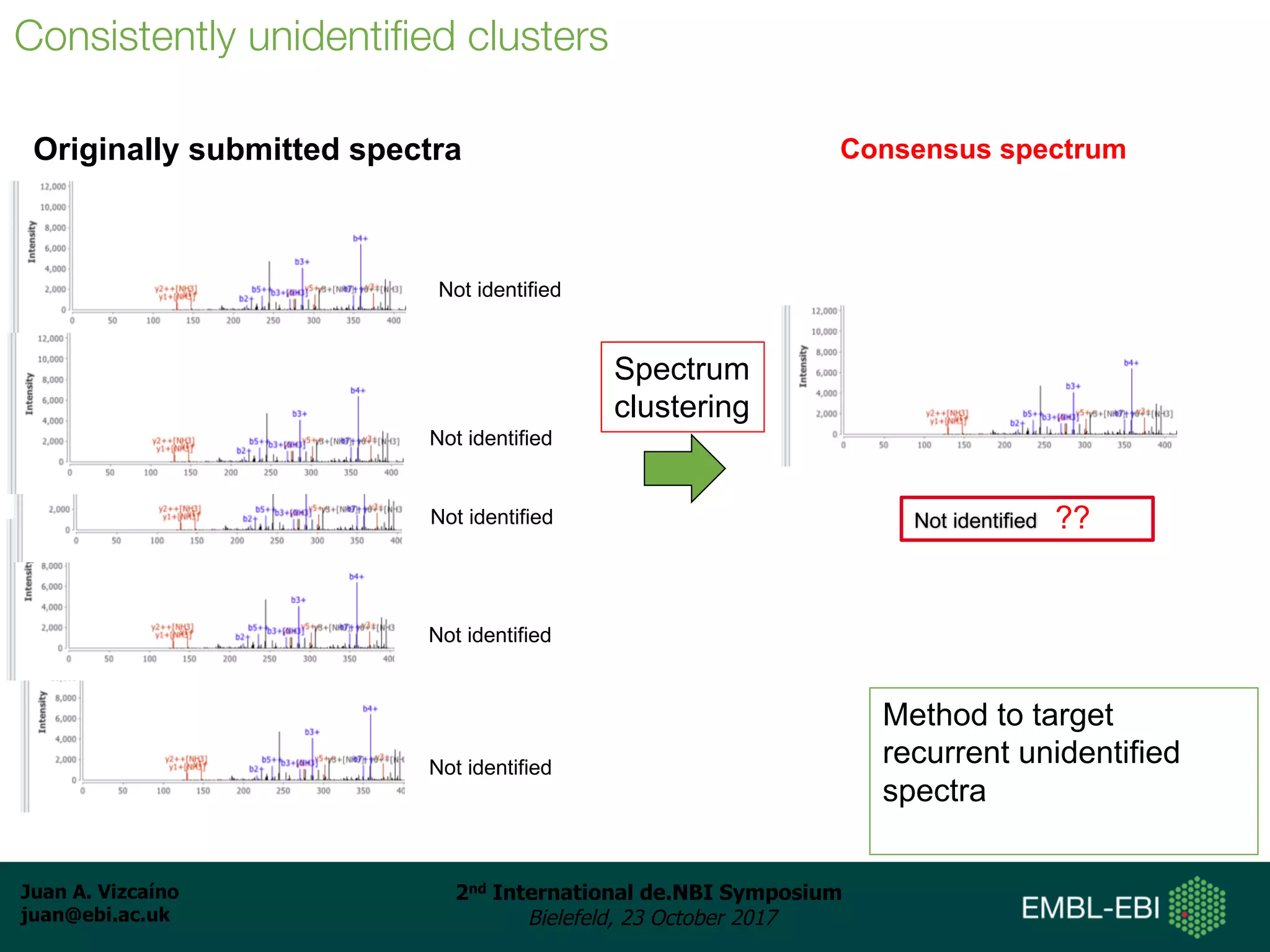

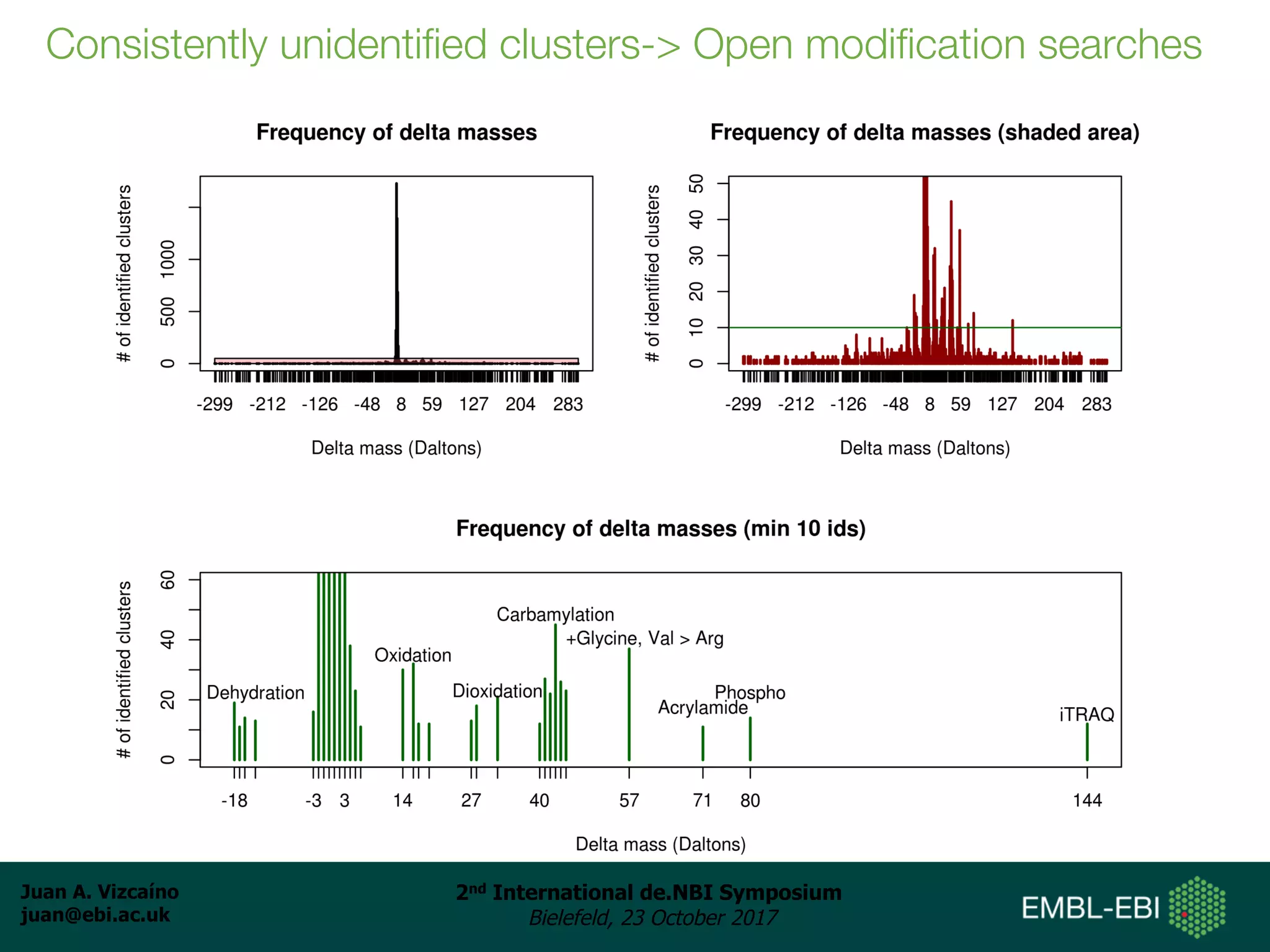










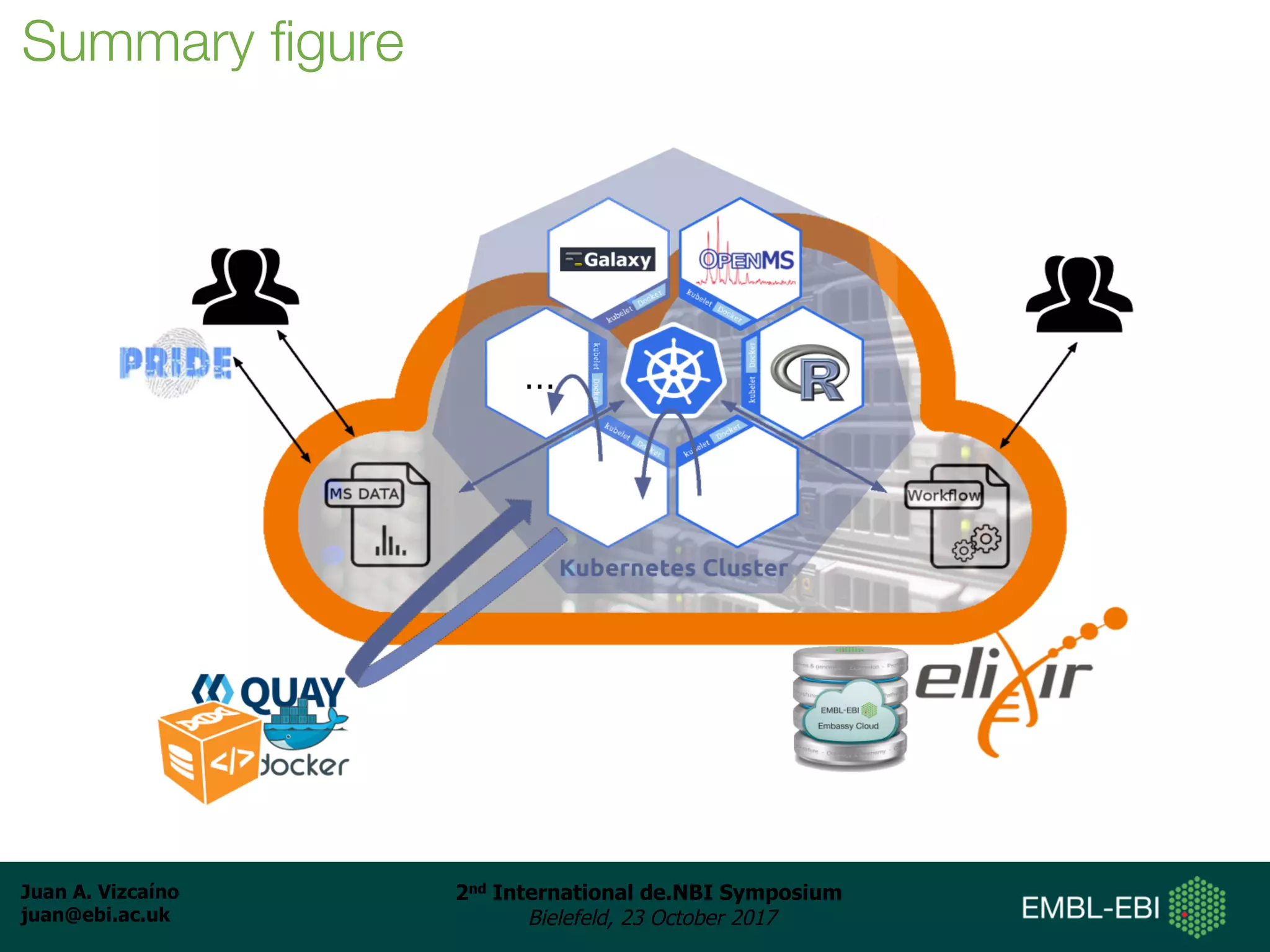

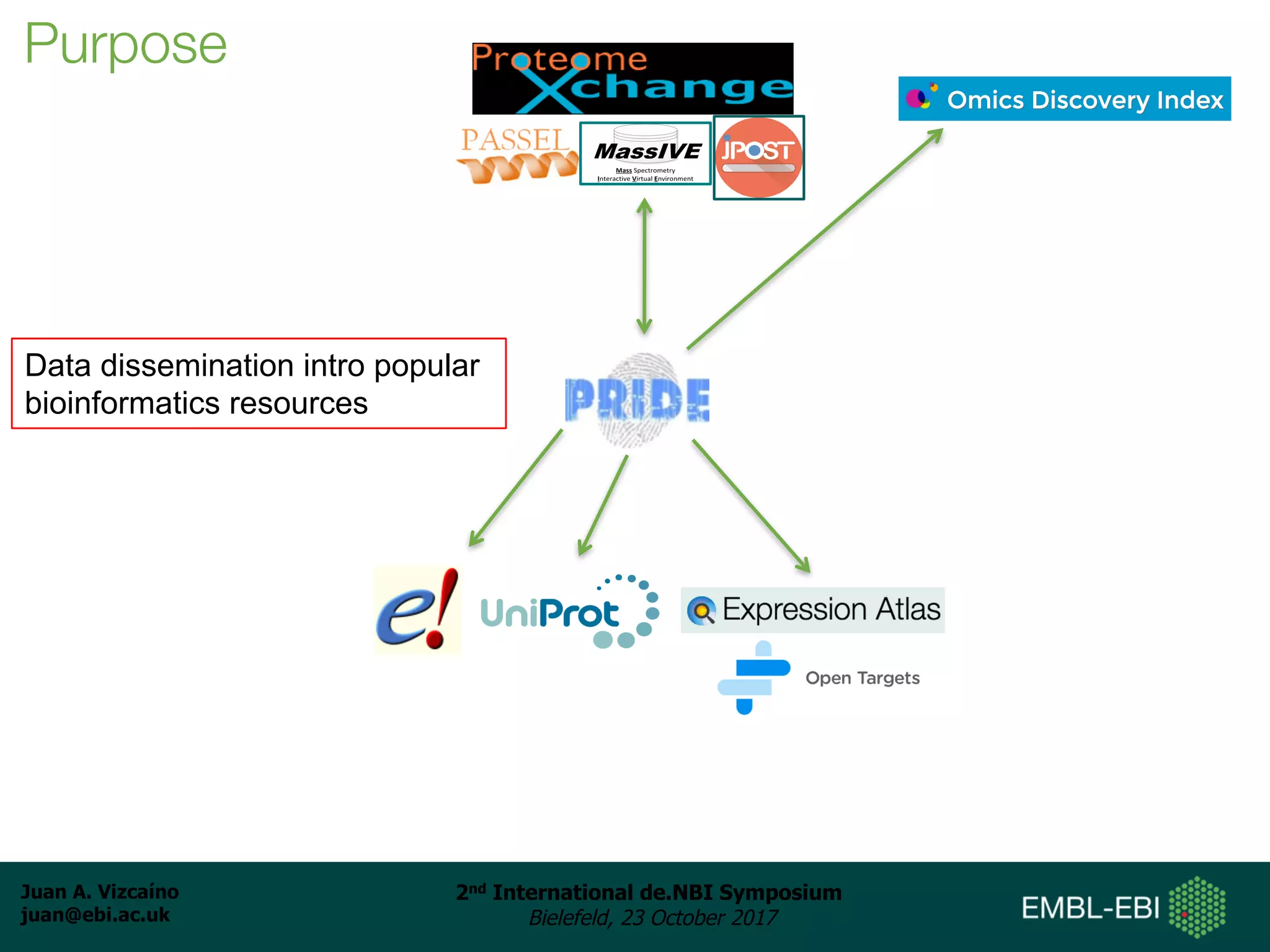








The document discusses the reuse of public proteomics data. It describes how data from the PRoteomics IDEntifications (PRIDE) Archive can be reanalyzed to conduct proteogenomics studies, discover new post-translational modifications and variants, and enable meta-analysis studies of protein-protein interactions and associations. It also examines challenges around analyzing the "dark proteome" of consistently unidentified spectra in public datasets and developing open analysis pipelines for proteomics data in cloud environments.

















































































