Download to read offline



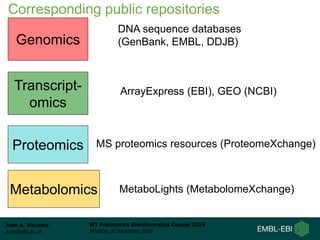









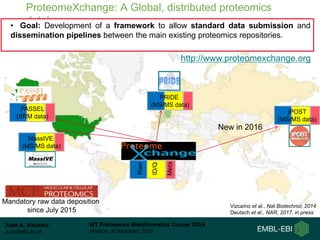


















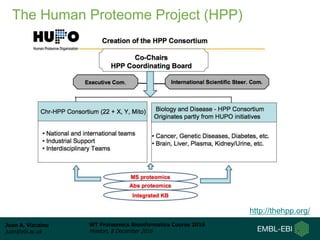









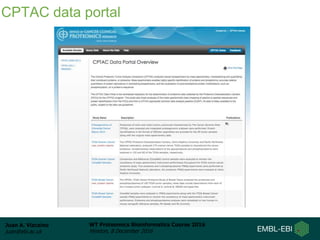
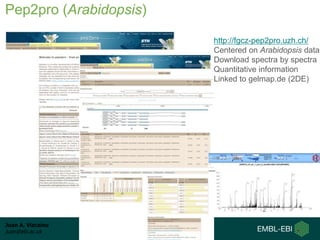







This document summarizes a presentation about proteomics repositories. It discusses why sharing proteomics data is important, the types of information stored in repositories, and some of the main existing repositories and their characteristics. Some repositories, like PRIDE and MassIVE, store data as originally analyzed without reprocessing. Others, like PeptideAtlas and GPMDB, reprocess raw data using a standardized pipeline to provide an updated view. The document also discusses resources developed from draft human proteome papers, including proteomicsDB and the Human Proteome Map.





















































































