Download to read offline


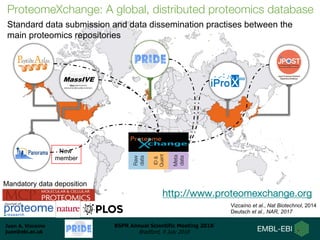
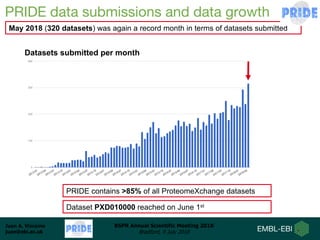
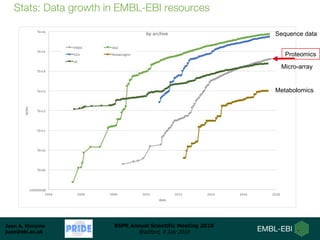


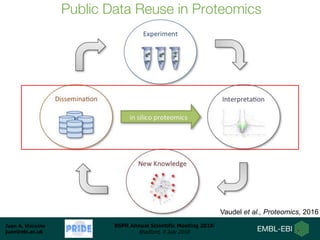
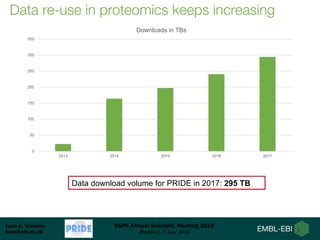








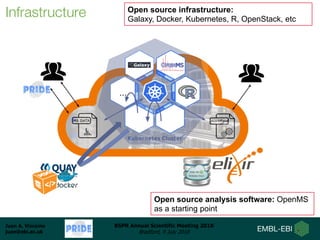






Dr. Juan Antonio Vizcaíno presented on developing open data analysis pipelines in the cloud to enable large-scale analysis of proteomics data. He introduced PRIDE and ProteomeXchange as repositories for proteomics data that are seeing substantial growth. Moving analysis pipelines to the cloud will facilitate public reuse of large datasets, improve scalability, and ensure reproducibility. Initial pipelines have been created for identification, quantification, and quality control of mass spectrometry data and deployed on the EMBL-EBI cloud platform. Future work includes optimizing access to PRIDE data and developing pipelines for analysis of DIA and proteogenomics data.















































































