Downloaded 12 times









![3/12/09 Bill Howe, eScience Institute14
Data Model Operations Services
GPL * * None for free
Workflow * arbitrary boxes-
and-arrows
typing, provenance,
Pegasus-style resource
mapping, task
parallelism
SQL /
Relational
Algebra
Relations Select, Project,
Join, Aggregate, …
optimization, physical
data independence,
indexing, parallelism
MapReduce [(key,value)] Map, Reduce massive data
parallelism, fault
tolerance, scheduling
Pig Nested
Relations
RA-like, with
Nest/Flatten
optimization,
monitoring, scheduling
DryadLINQ IQueryable,
IEnumerable
RA + Apply +
Partitioning
typing, massive data
parallelism, fault
tolerance
MPI Arrays/
Matrices
70+ ops data parallelism, full
control](https://image.slidesharecdn.com/escience2009-101029114705-phpapp01/75/A-New-Partnership-for-Cross-Scale-Cross-Domain-eScience-14-2048.jpg)

![3/12/09 Bill Howe, eScience Institute16
public class LogEntry {
public string user, ip;
public string page;
public LogEntry(string line) {
string[] fields = line.Split(' ');
this.user = fields[8];
this.ip = fields[9];
this.page = fields[5];
}
}
public class UserPageCount{
public string user, page;
public int count;
public UserPageCount(
string usr, string page, int cnt){
this.user = usr;
this.page = page;
this.count = cnt;
}
}
PartitionedTable<string> logs =
PartitionedTable.Get<string>(@”file:…logfile.pt”);
var logentries =
from line in logs
where !line.StartsWith("#")
select new LogEntry(line);
var user =
from access in logentries
where access.user.EndsWith(@"ulfar")
select access;
var accesses =
from access in user
group access by access.page into pages
select new UserPageCount("ulfar", pages.Key, pages.Count());
var htmAccesses =
from access in accesses
where access.page.EndsWith(".htm")
orderby access.count descending
select access;
htmAccesses.ToPartitionedTable(@”file:…results.pt”);
slide source: Christophe Poulain, MSR
A complete DryadLINQ program](https://image.slidesharecdn.com/escience2009-101029114705-phpapp01/75/A-New-Partnership-for-Cross-Scale-Cross-Domain-eScience-16-2048.jpg)


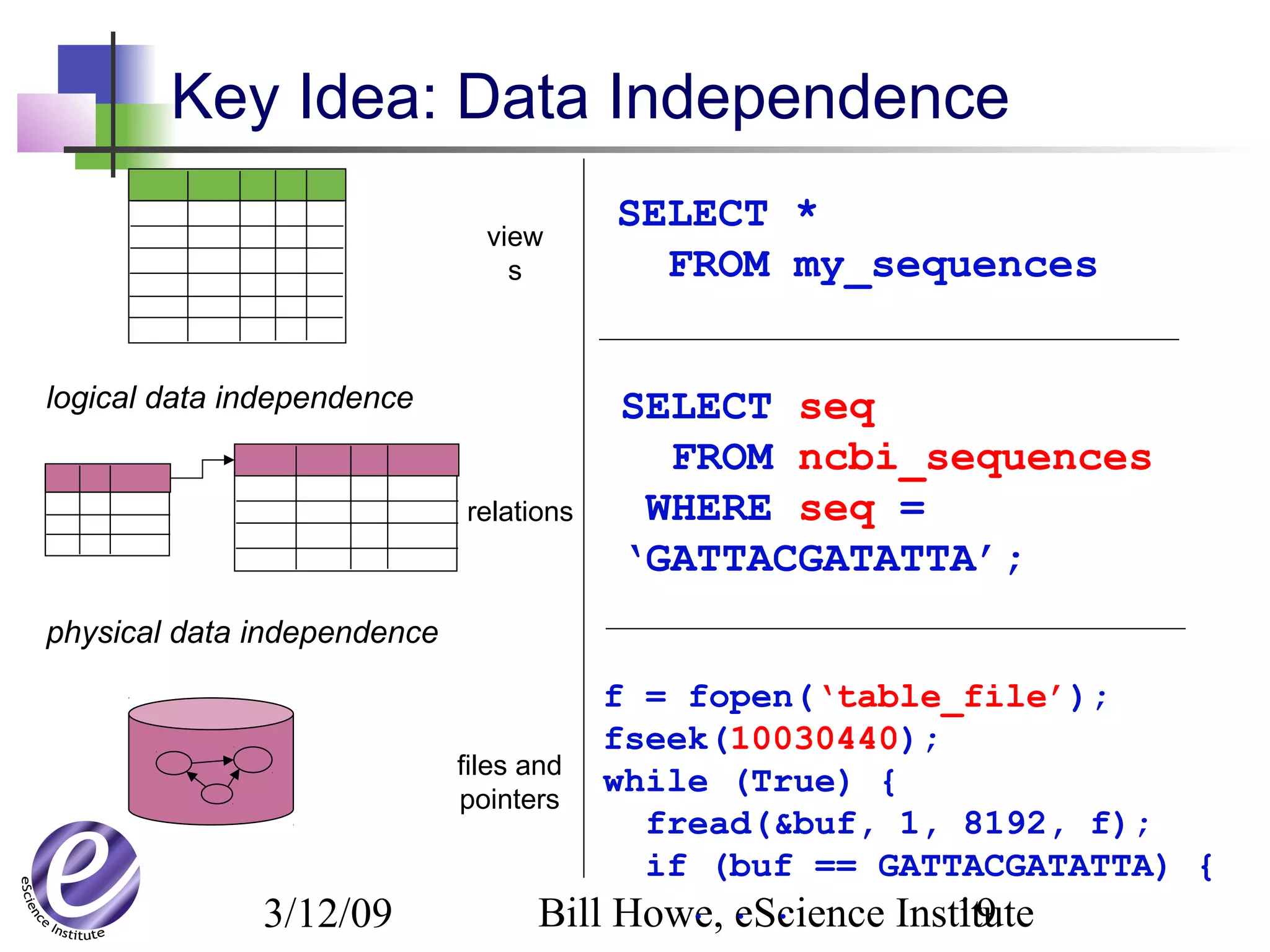
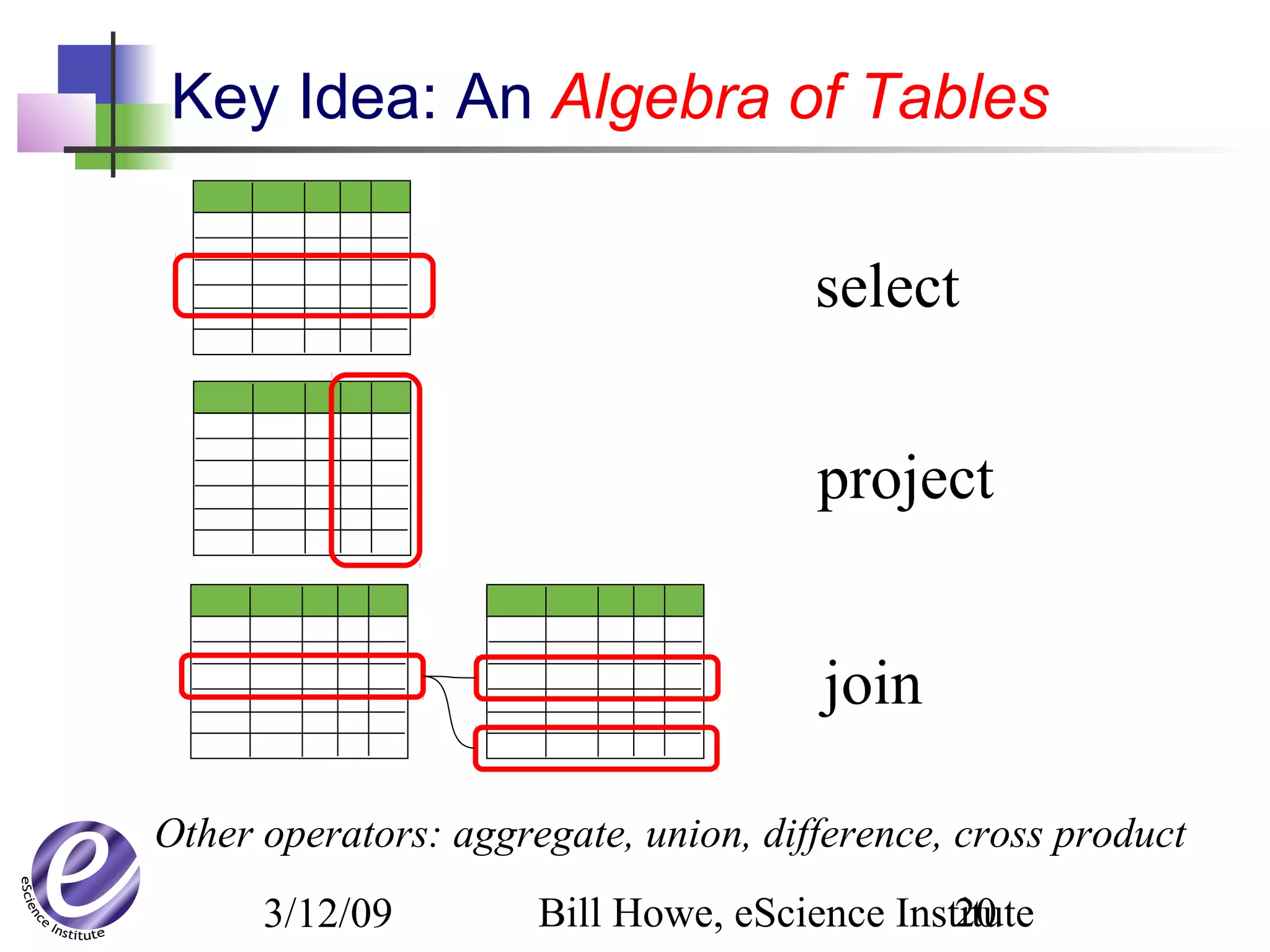





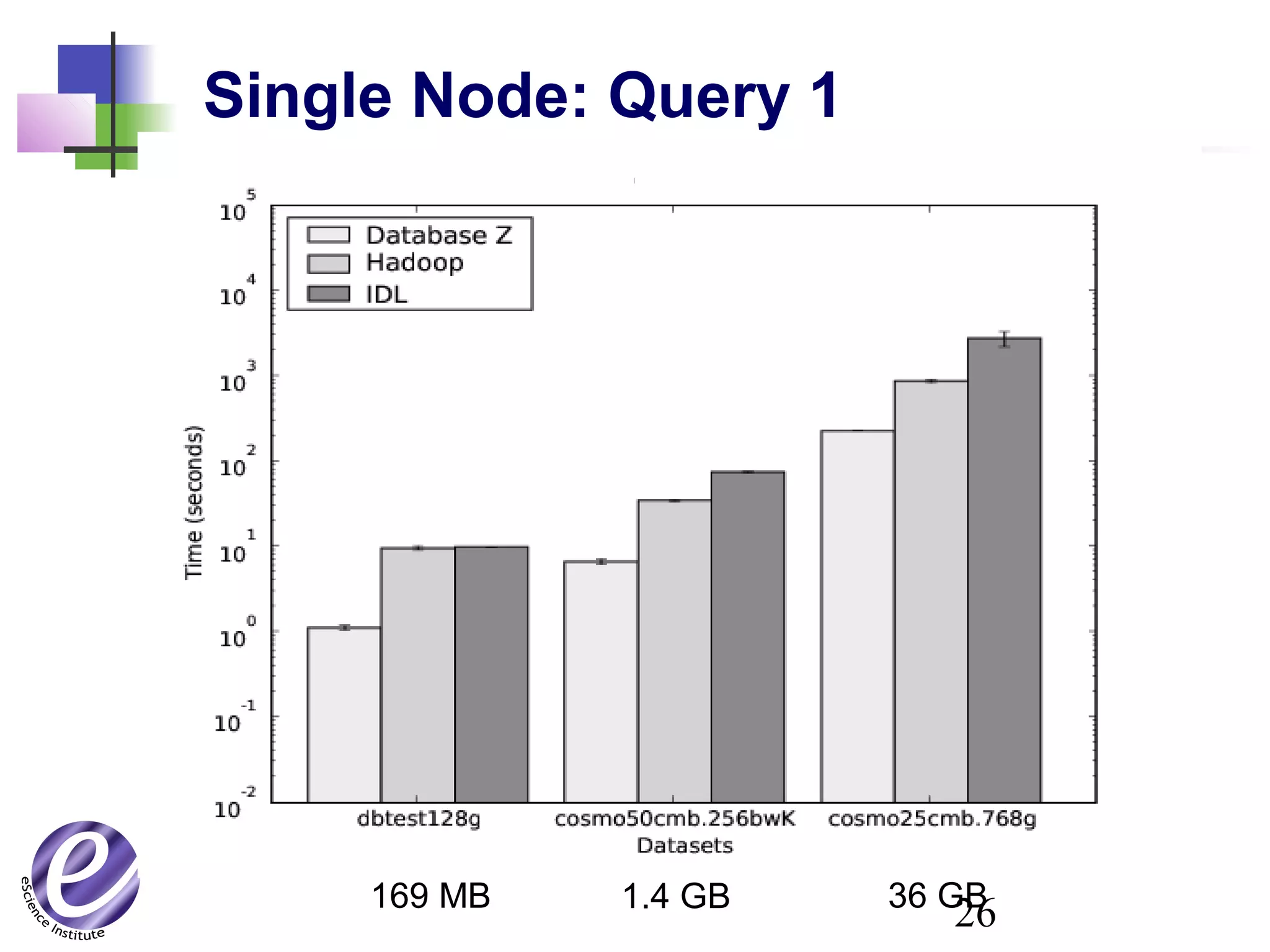
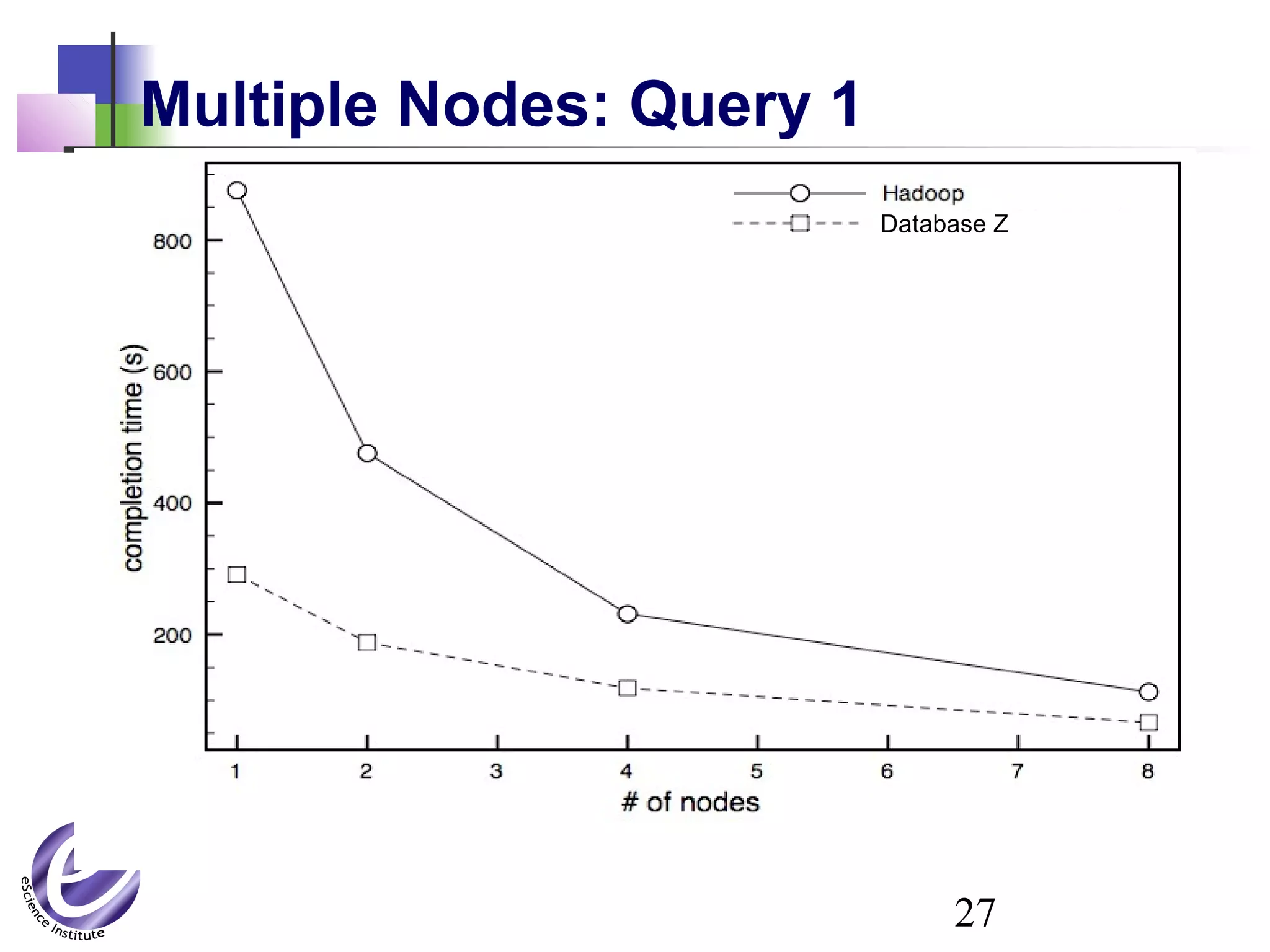
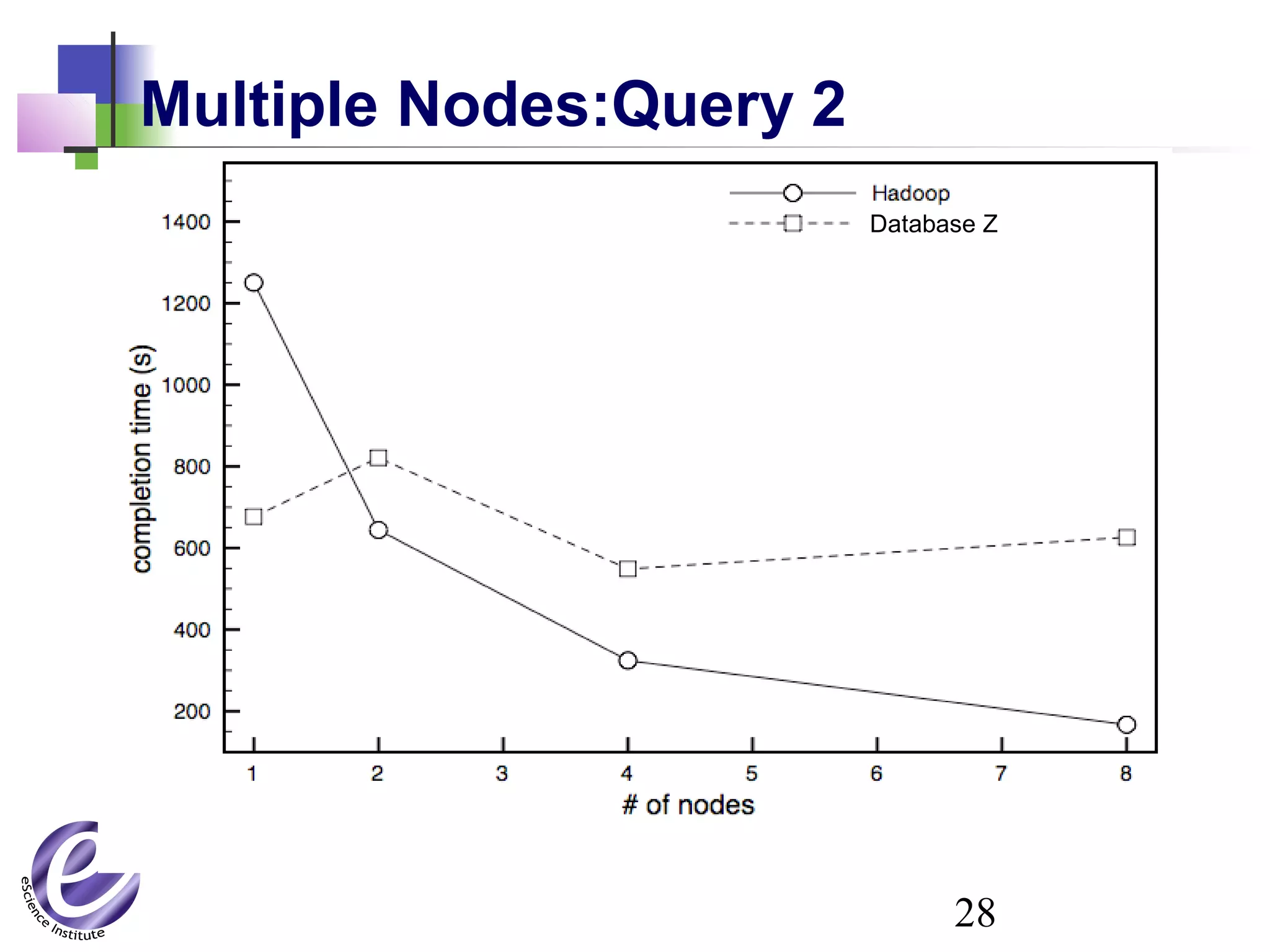

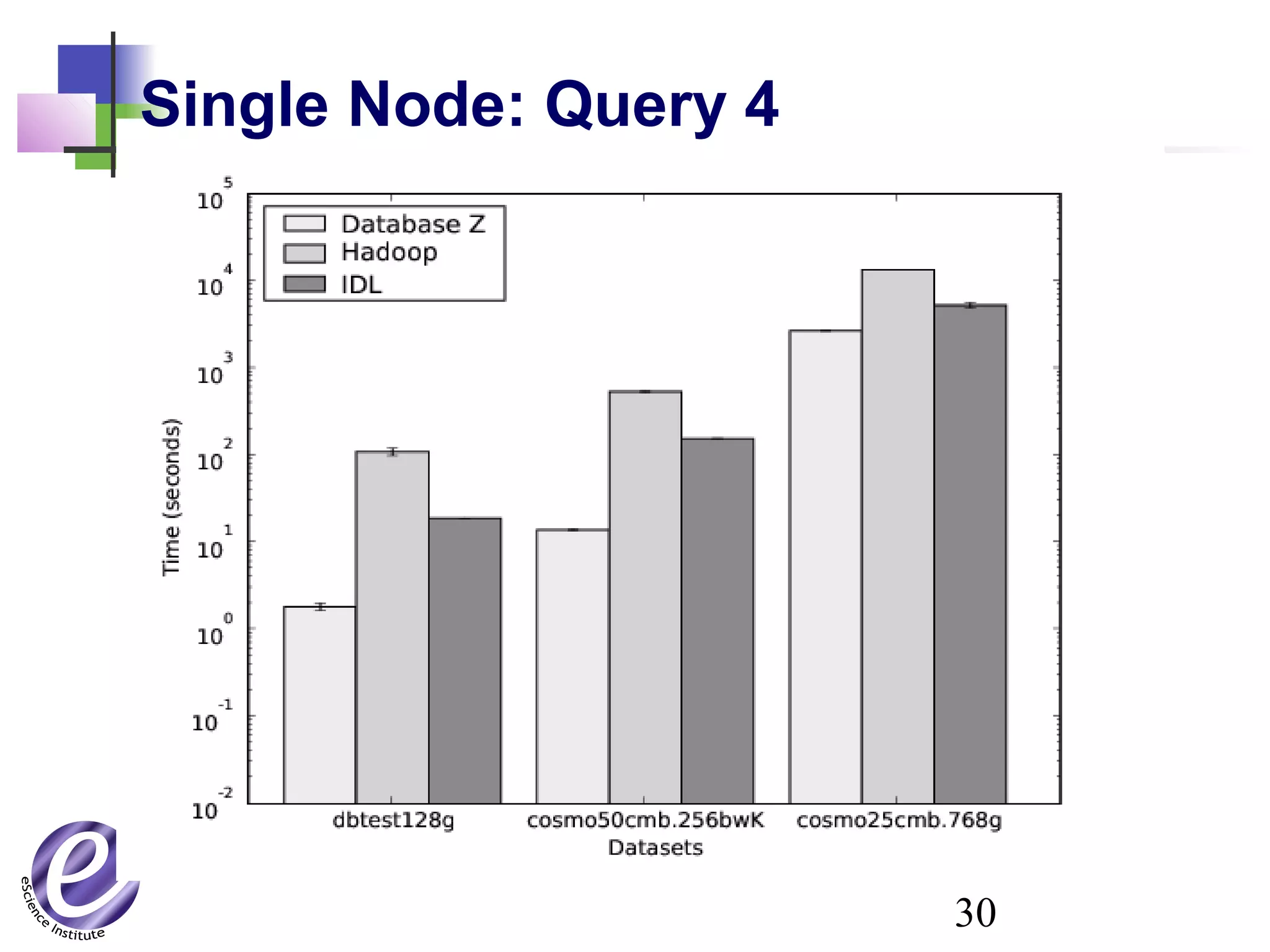
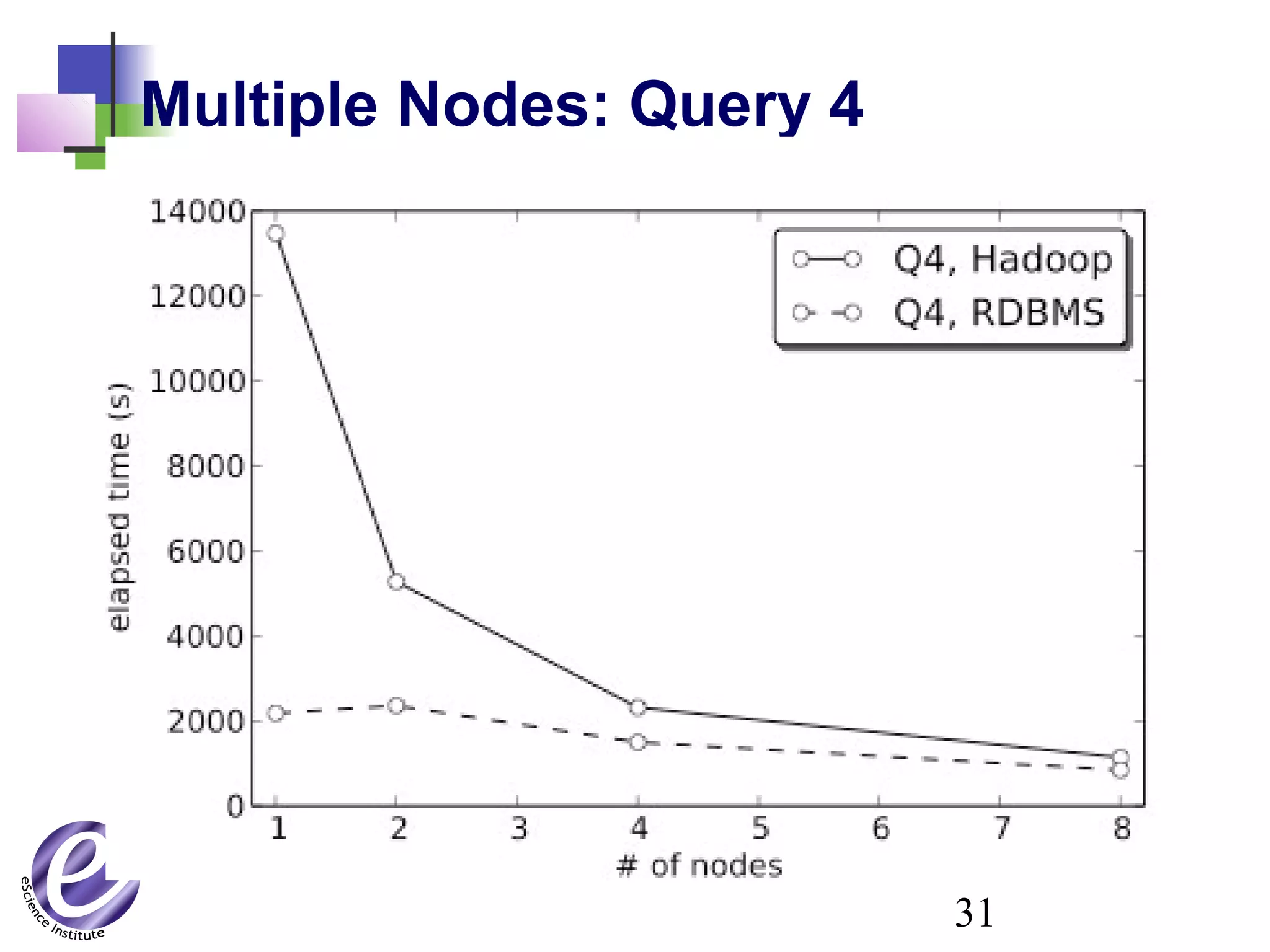




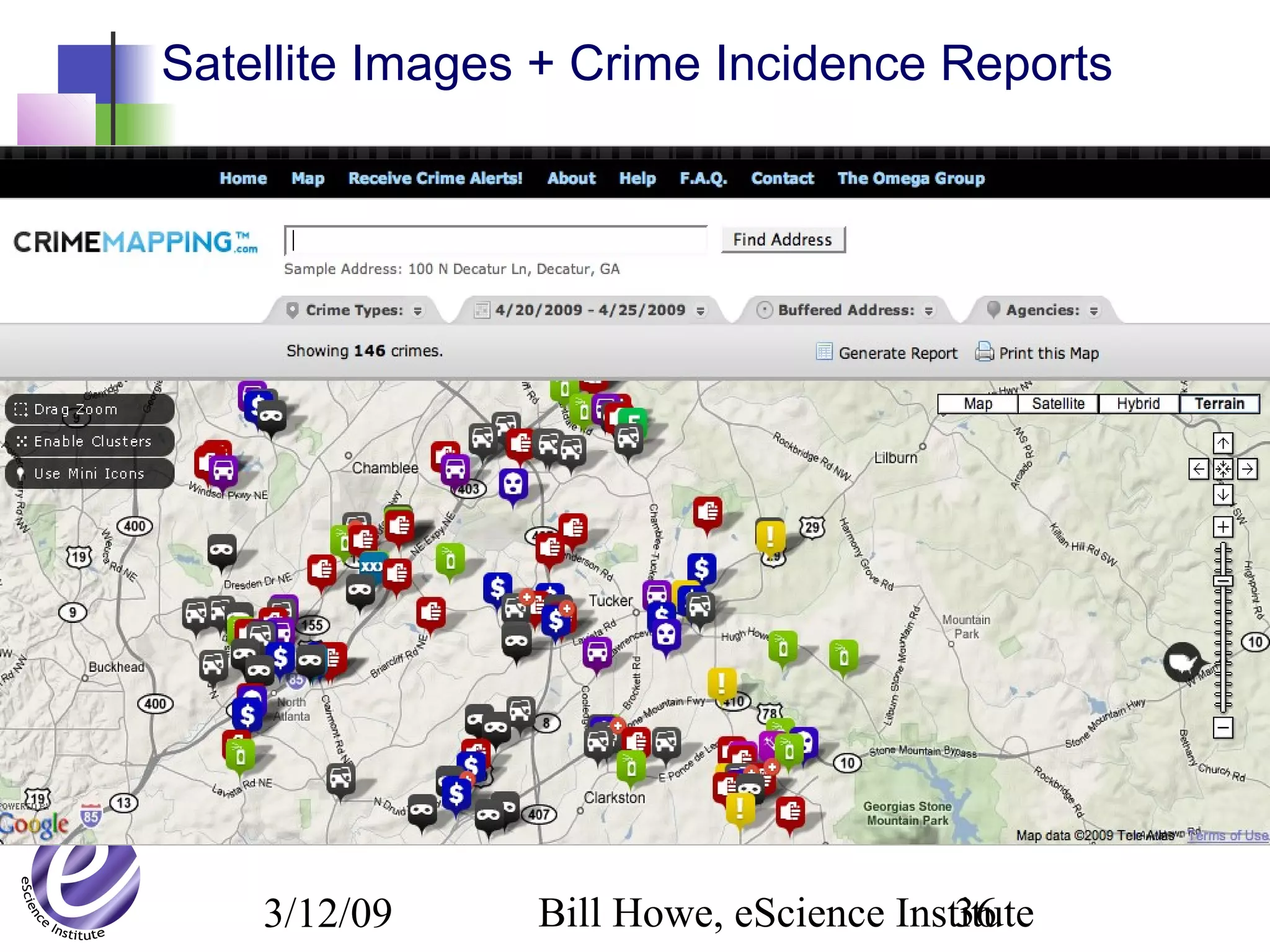



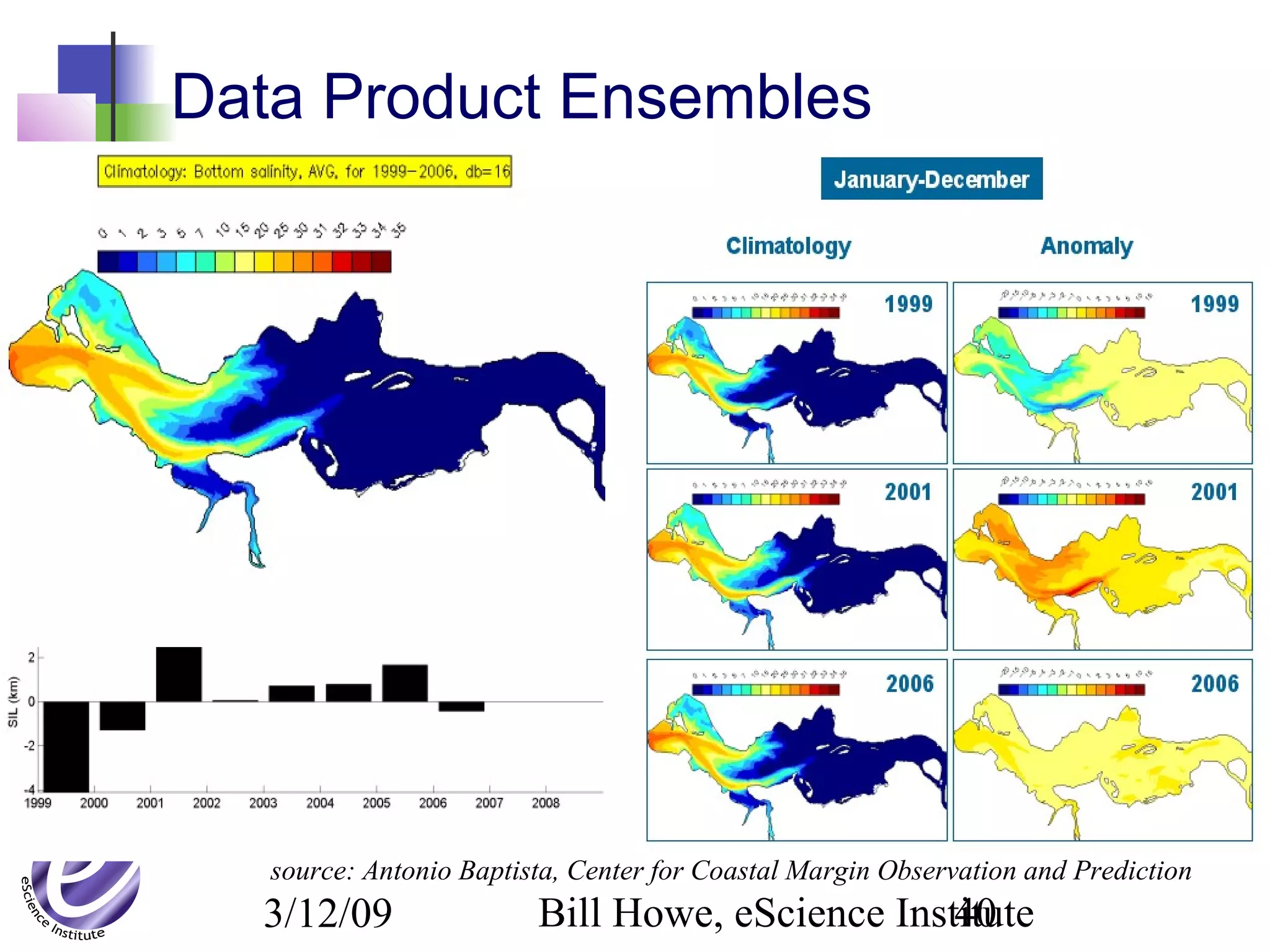

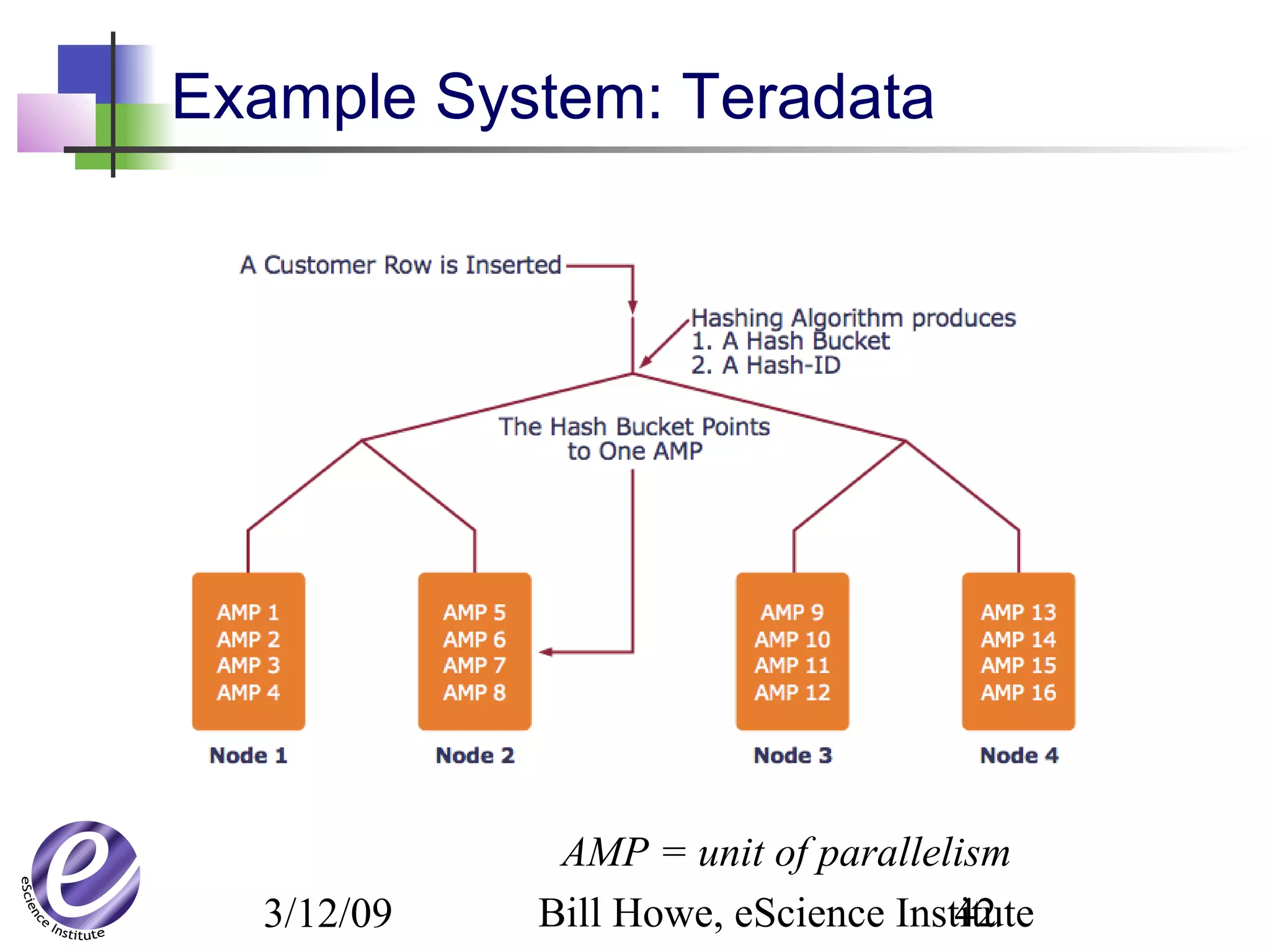
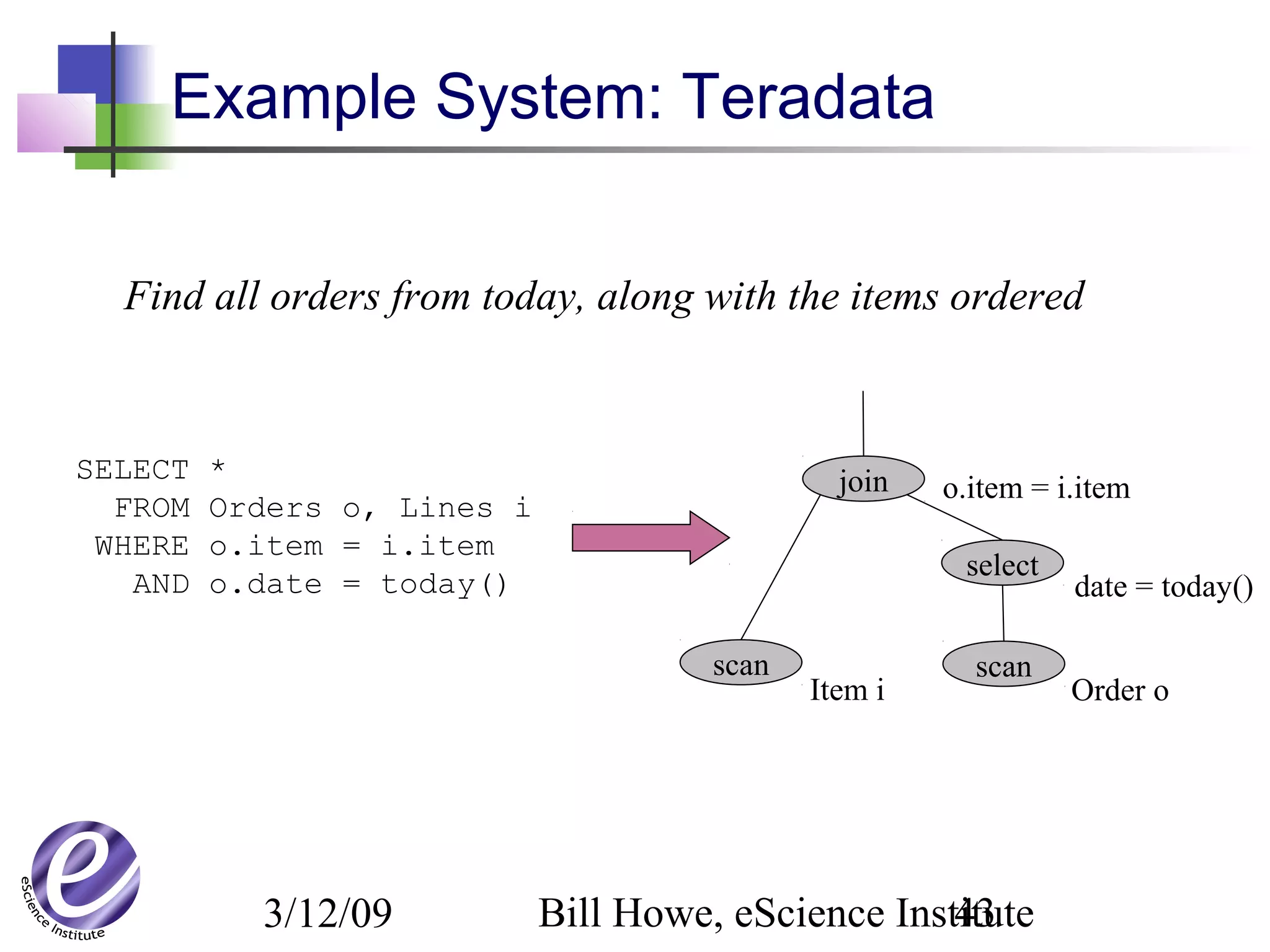
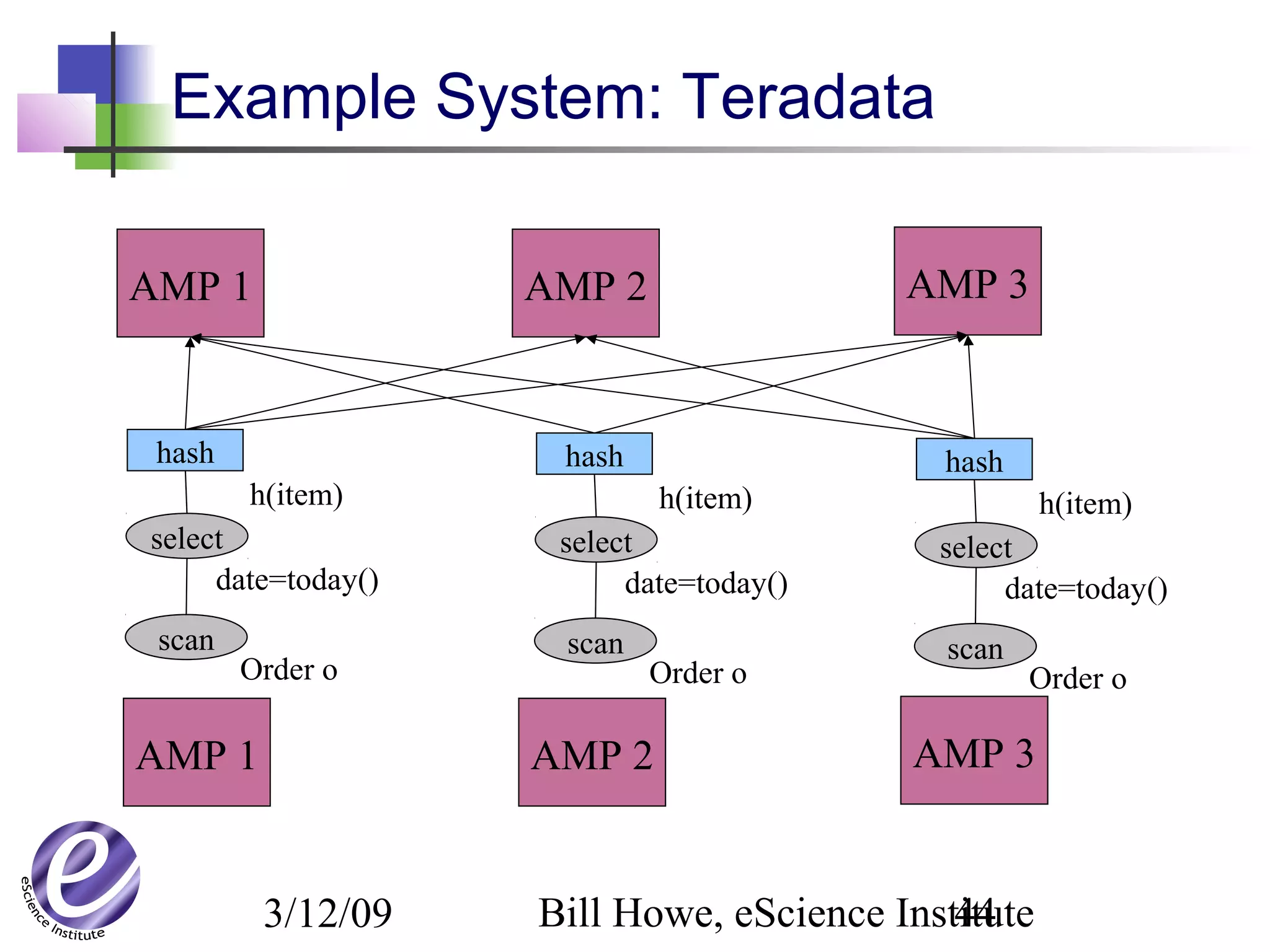
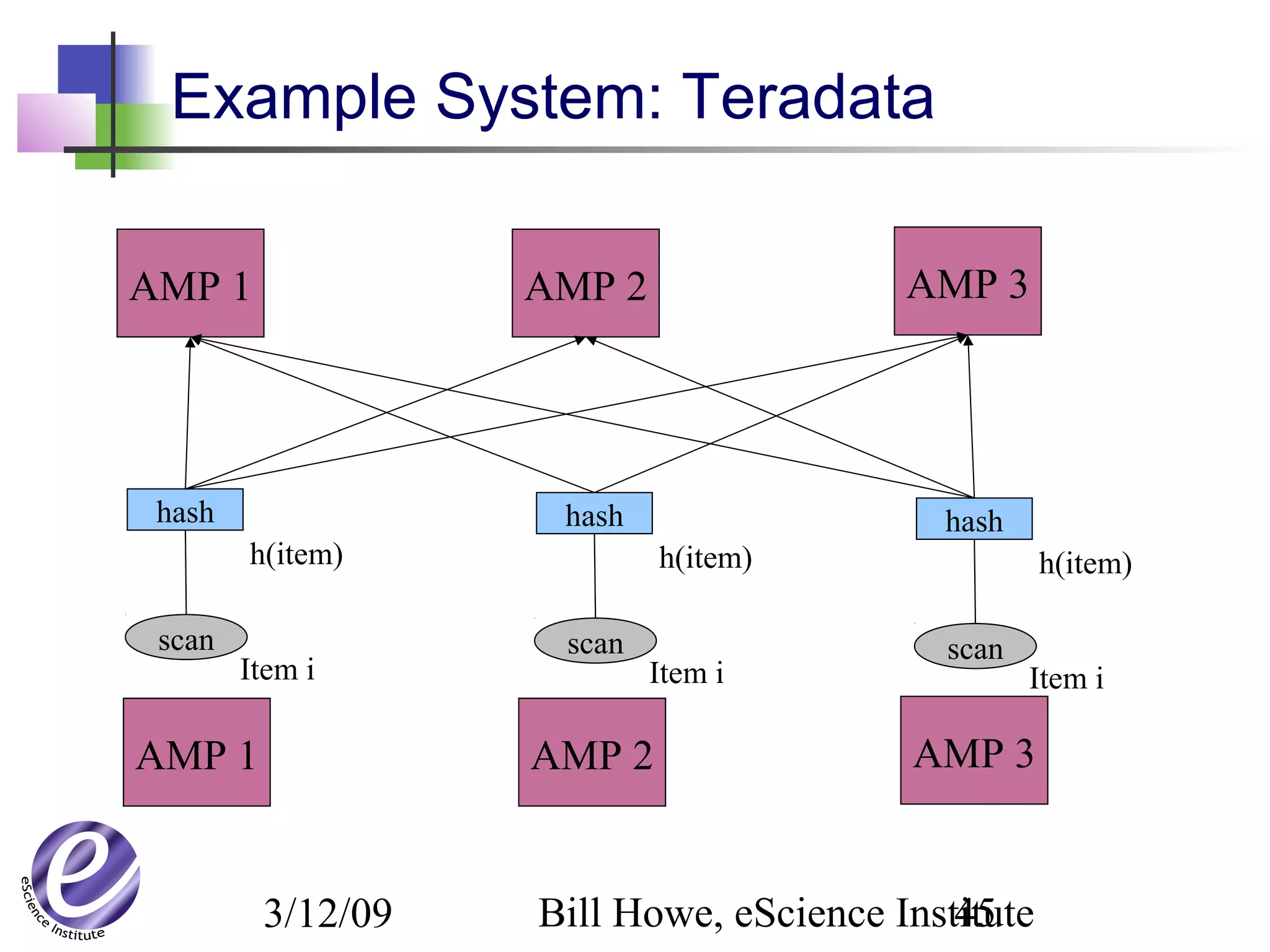
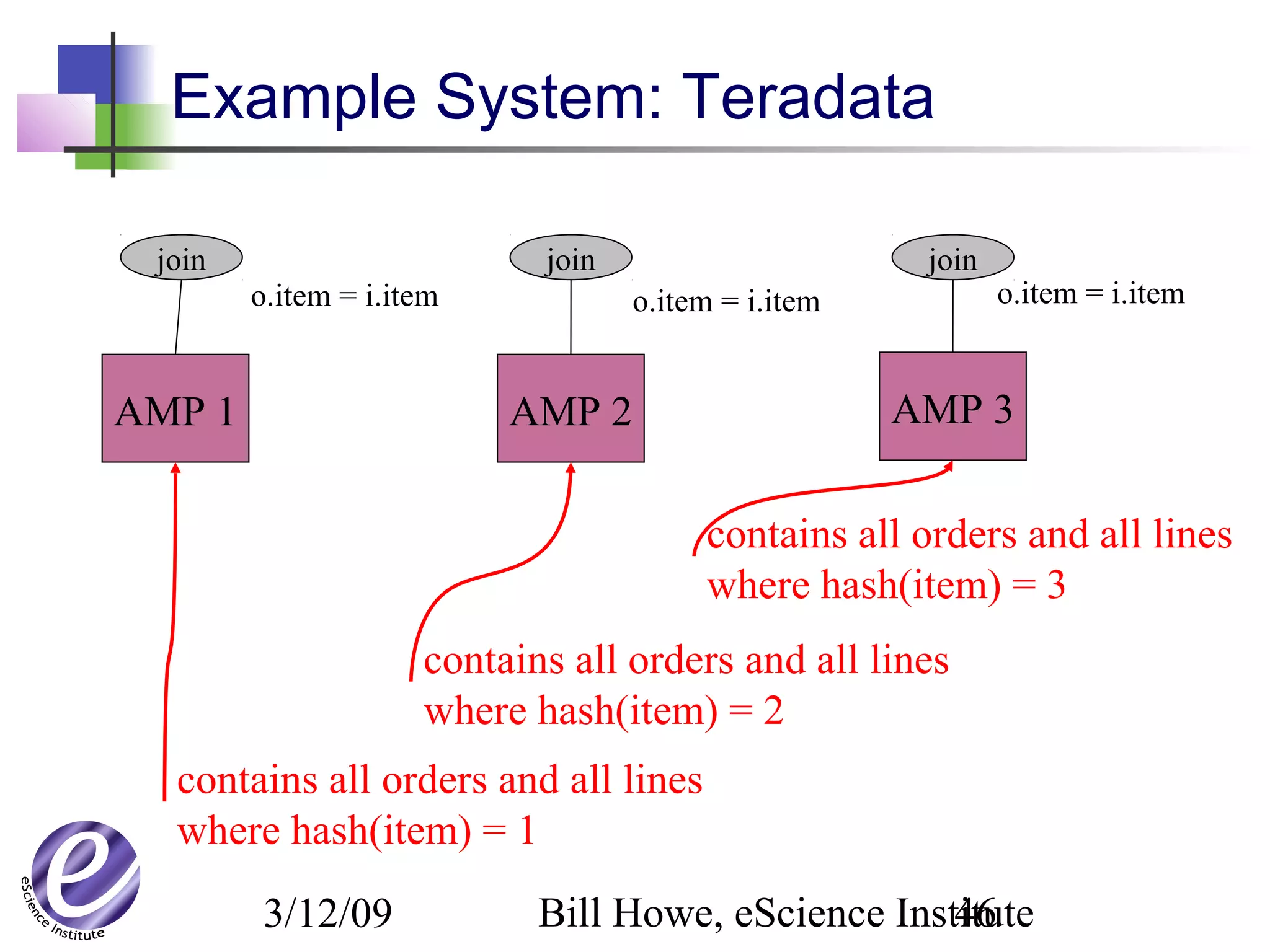

















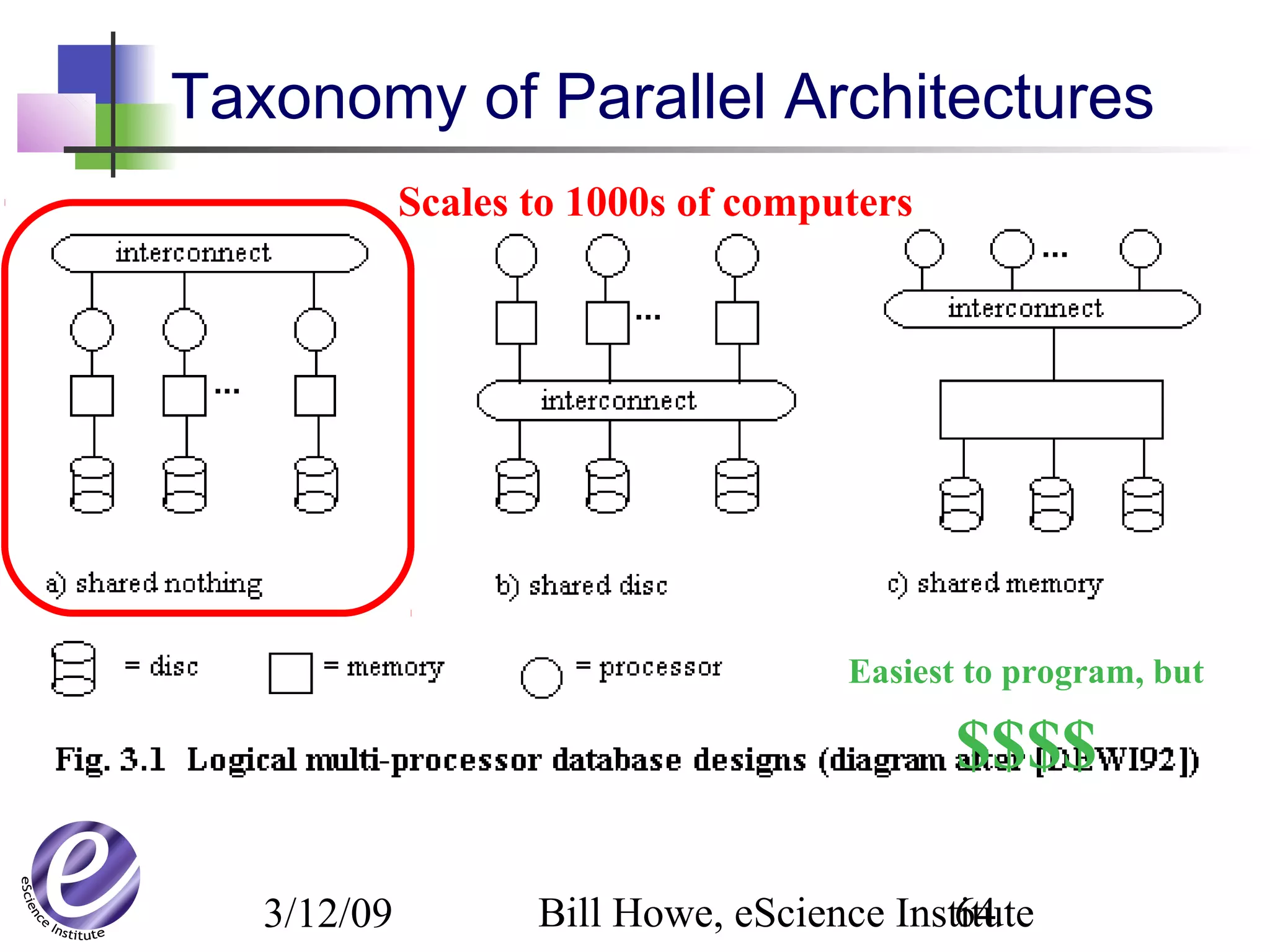

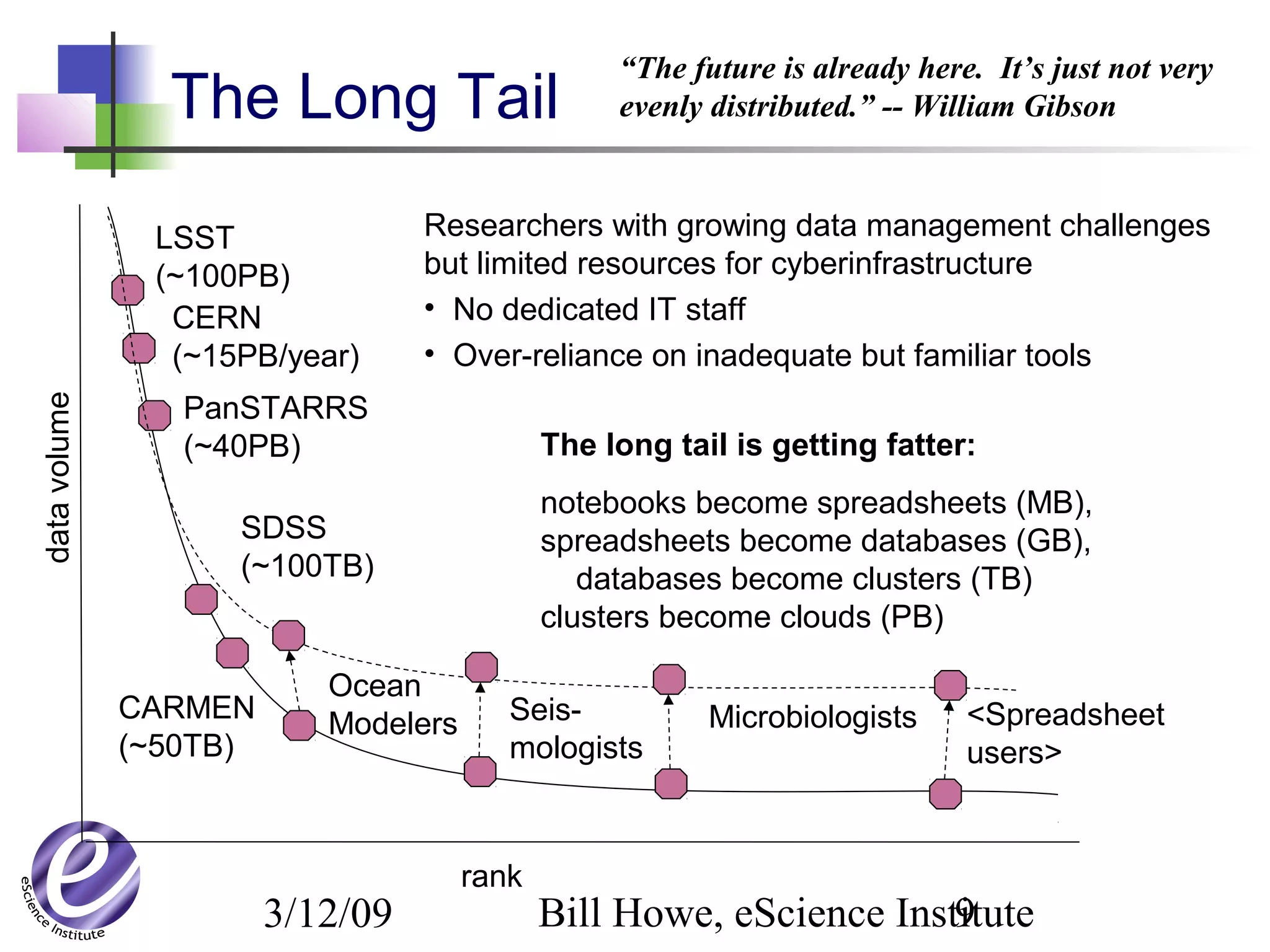
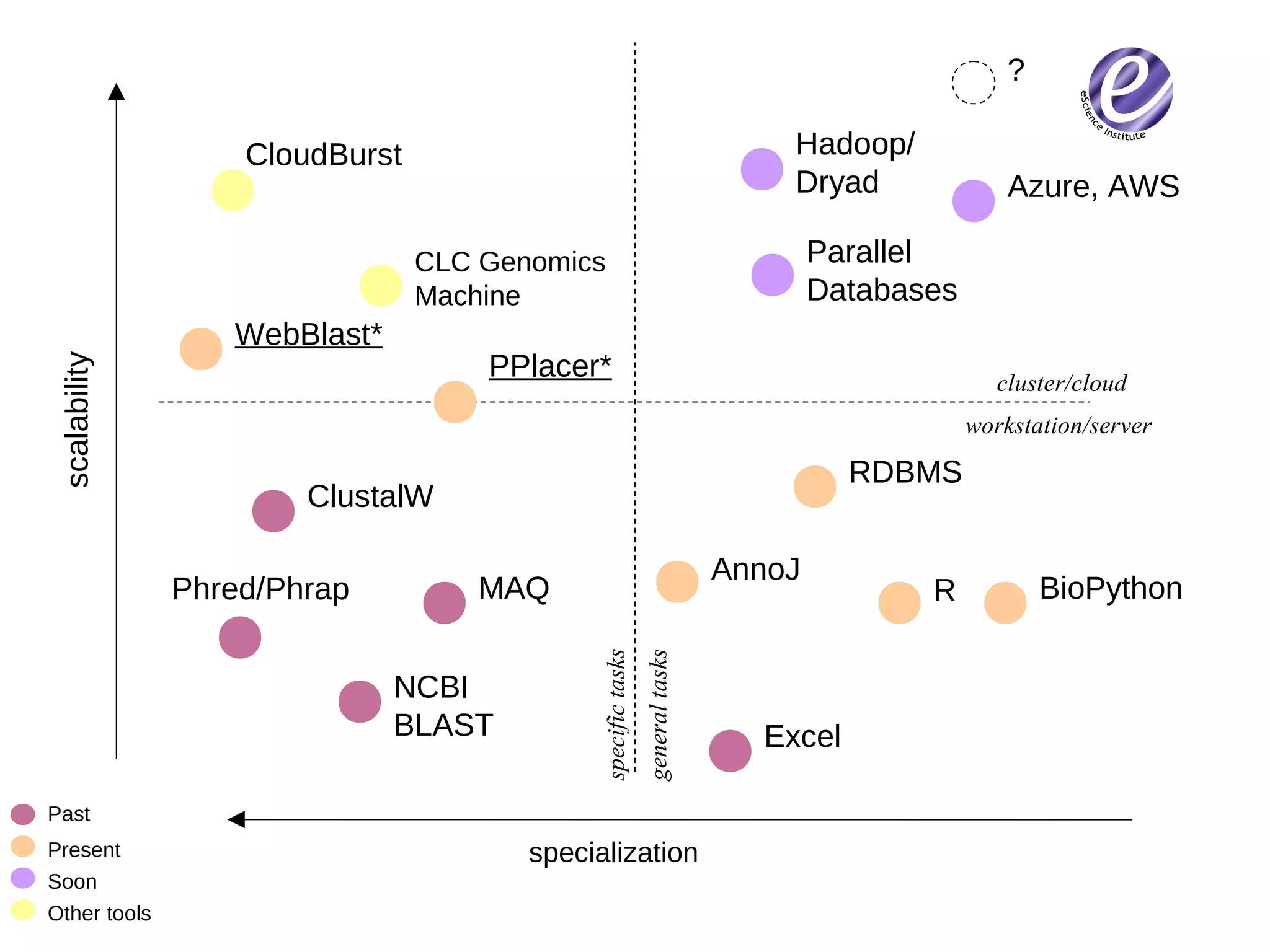
The document discusses the formation of a new partnership between the University of Washington and Carnegie Mellon University called the eScience Institute. The partnership will receive $1 million per year in funding from the state of Washington and $1.5 million from the Gordon and Betty Moore Foundation. The goal of the institute is to help universities stay competitive by positioning them at the forefront of modern techniques in data-intensive science fields like sensors, databases, and data mining.











































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















