Downloaded 24 times



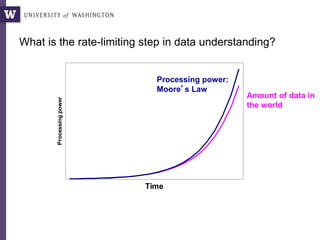
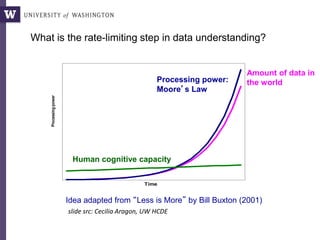




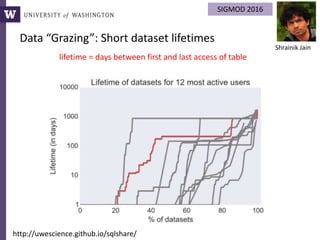

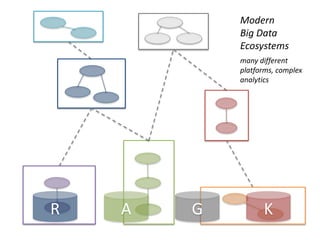
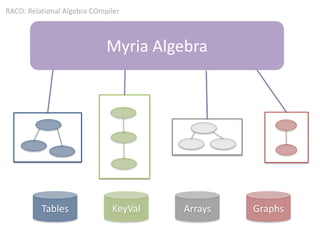
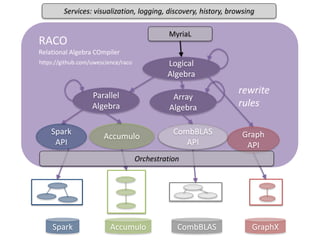

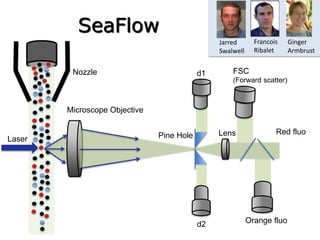




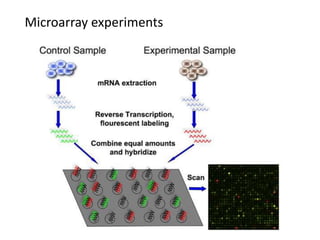
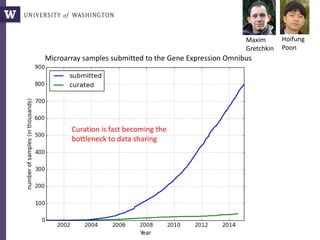
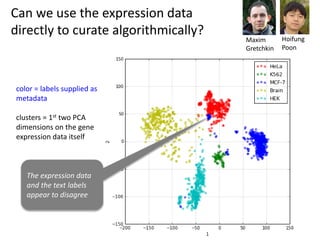

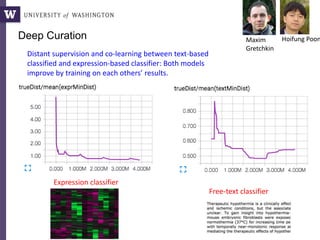

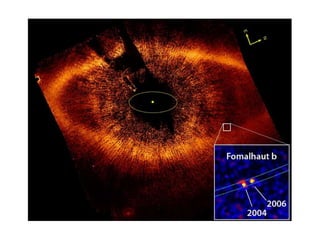



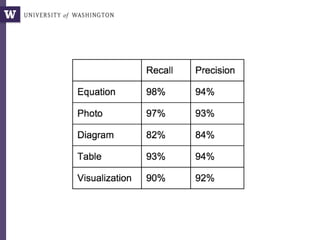
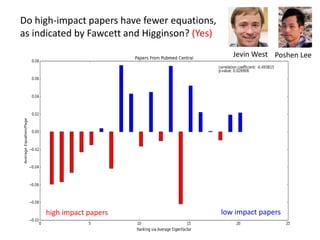
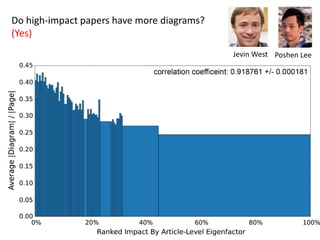
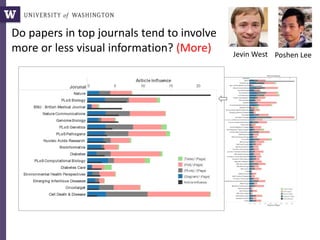


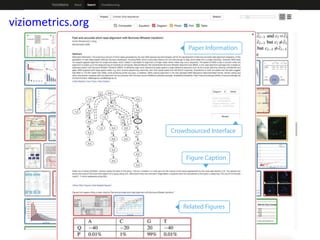
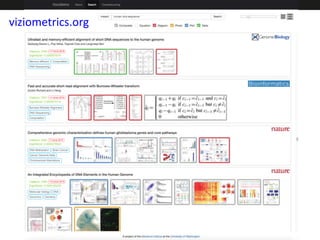

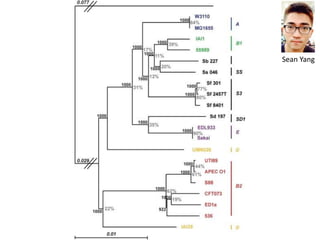
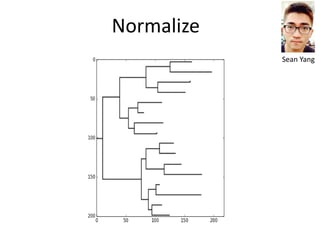
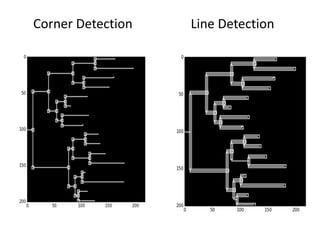
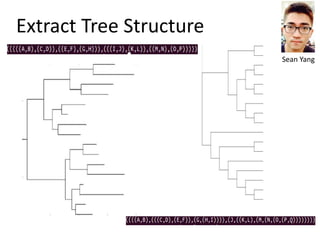

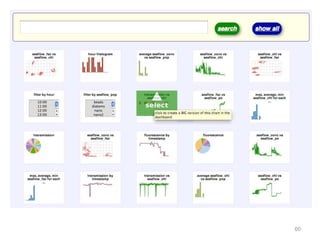










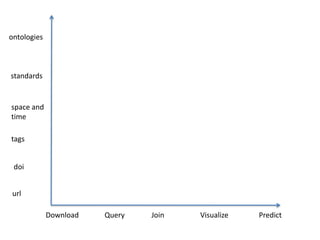



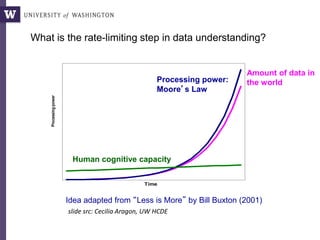



The document discusses various aspects of data science, particularly focusing on human-data interaction, data curation, and the complexity of modern data ecosystems. It highlights the challenges faced by researchers in handling large amounts of data, emphasizing how data processing and curation can become bottlenecks in scientific workflows. Several projects, including SQLShare, Myria, and Viziometrics, are mentioned as efforts to optimize data usage and improve access to scientific information.






















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
