Downloaded 10 times












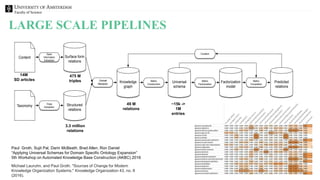



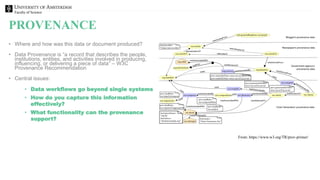

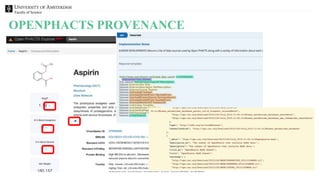
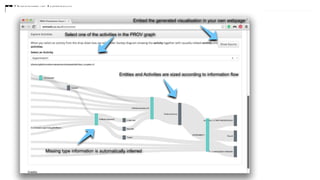




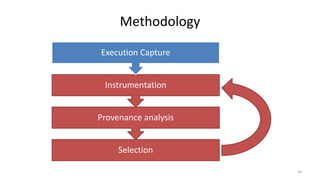

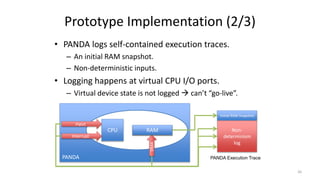
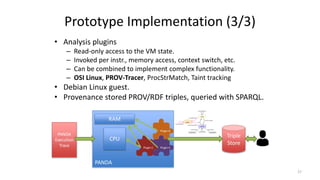
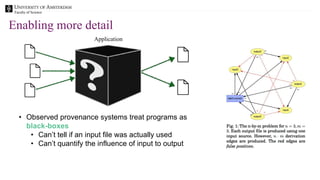
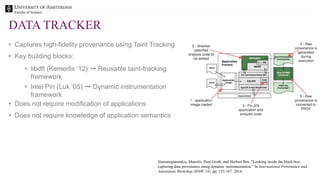
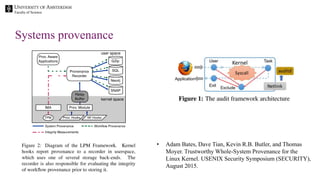












The document discusses the importance of data provenance and knowledge graphs in integrating and assessing data across scientific disciplines to address global challenges. It highlights challenges in data workflows, transparency, and the need for standardized methodologies to capture data provenance effectively. Furthermore, it examines the roles of humans and machines in data assessment and the necessity for transparency in data handling and decision-making processes.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




