Downloaded 117 times









![trove/guestagent/strategies
backup/
[…]
replication/
restore/
storage/
trove/guestagent/
[…]
backup/
common/
datastore/
[…]
strategies/
[…]
trove/guestagent/strategies/backup
base.py
base.pyc
couchbase_impl.py
couchbase_impl.pyc
__init__.py
__init__.pyc
mysql_impl.py
mysql_impl.pyc
postgresql_impl.py
grep class guestagent/strategies/backup/mysql_impl.py
class MySQLDump(base.BackupRunner):
class InnoBackupEx(base.BackupRunner):
class InnoBackupExIncremental(InnoBackupEx):
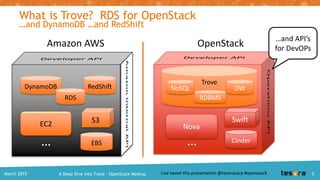
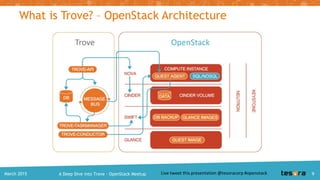
Trove Architecture: Code Modularity
A Deep Dive into Trove – OpenStack MeetupMarch 2015](https://image.slidesharecdn.com/adeepdiveintotrove-150310152932-conversion-gate01/85/A-Deep-Dive-Into-Trove-11-320.jpg)













This document provides an overview of OpenStack Trove, a database as a service (DBaaS) solution for OpenStack. It discusses how Trove enables self-service provisioning and management of relational and non-relational databases. The document also summarizes Trove's architecture, contributions from the community, features added in recent releases, and planned work for upcoming releases.








![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)









![[OpenInfra Days Korea 2018] (Track 3) Zuul v3 - OpenStack 인프라 코드로 CI/CD 살펴보기](https://cdn.slidesharecdn.com/ss_thumbnails/37openinfradays2018-zuul-180628163209-thumbnail.jpg?width=640&height=640&fit=bounds)
















































