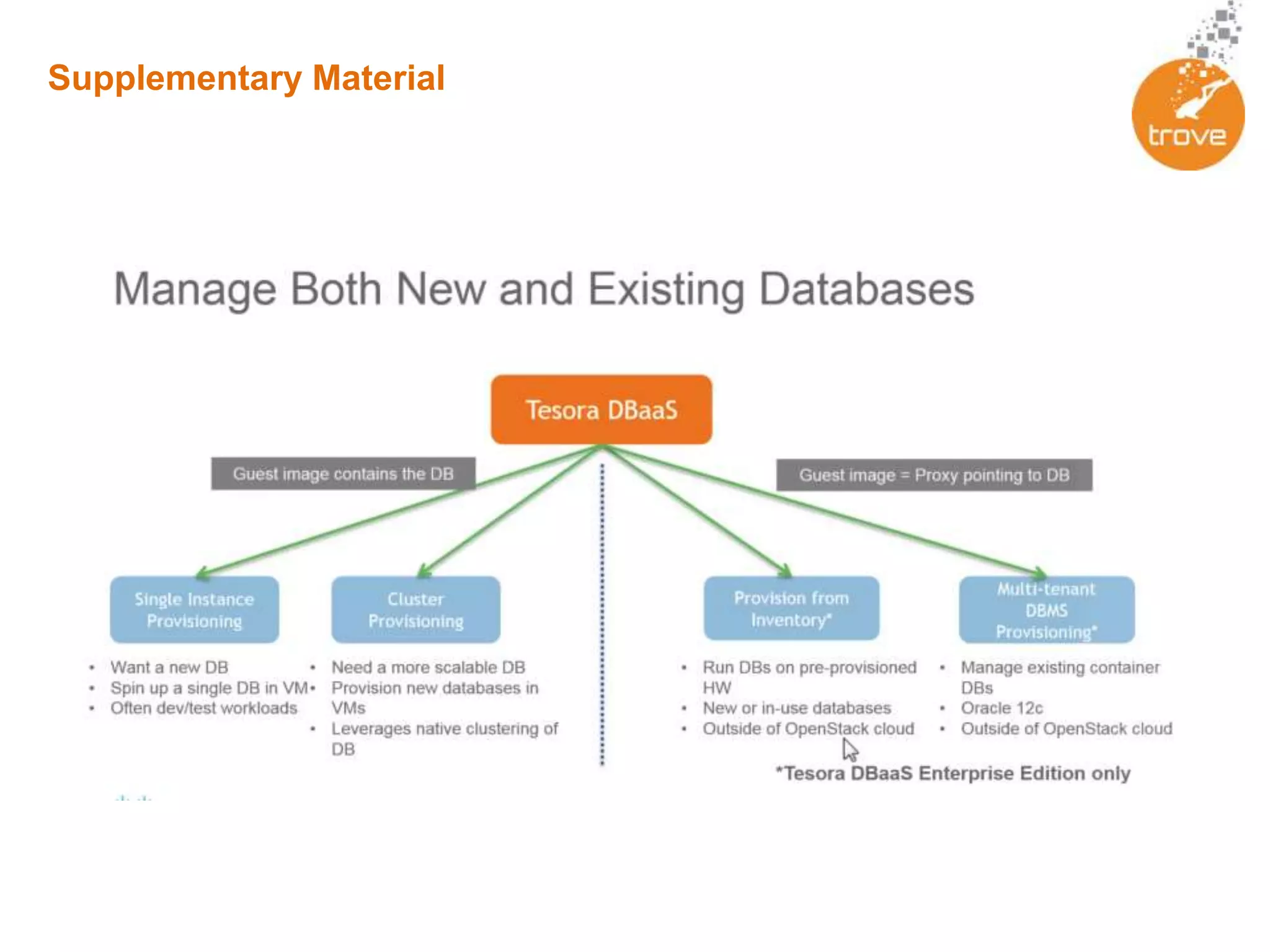
Achieving Cost and Resource efficiency within OpenStack through Trove Database-As-A-Service (DBaaS)
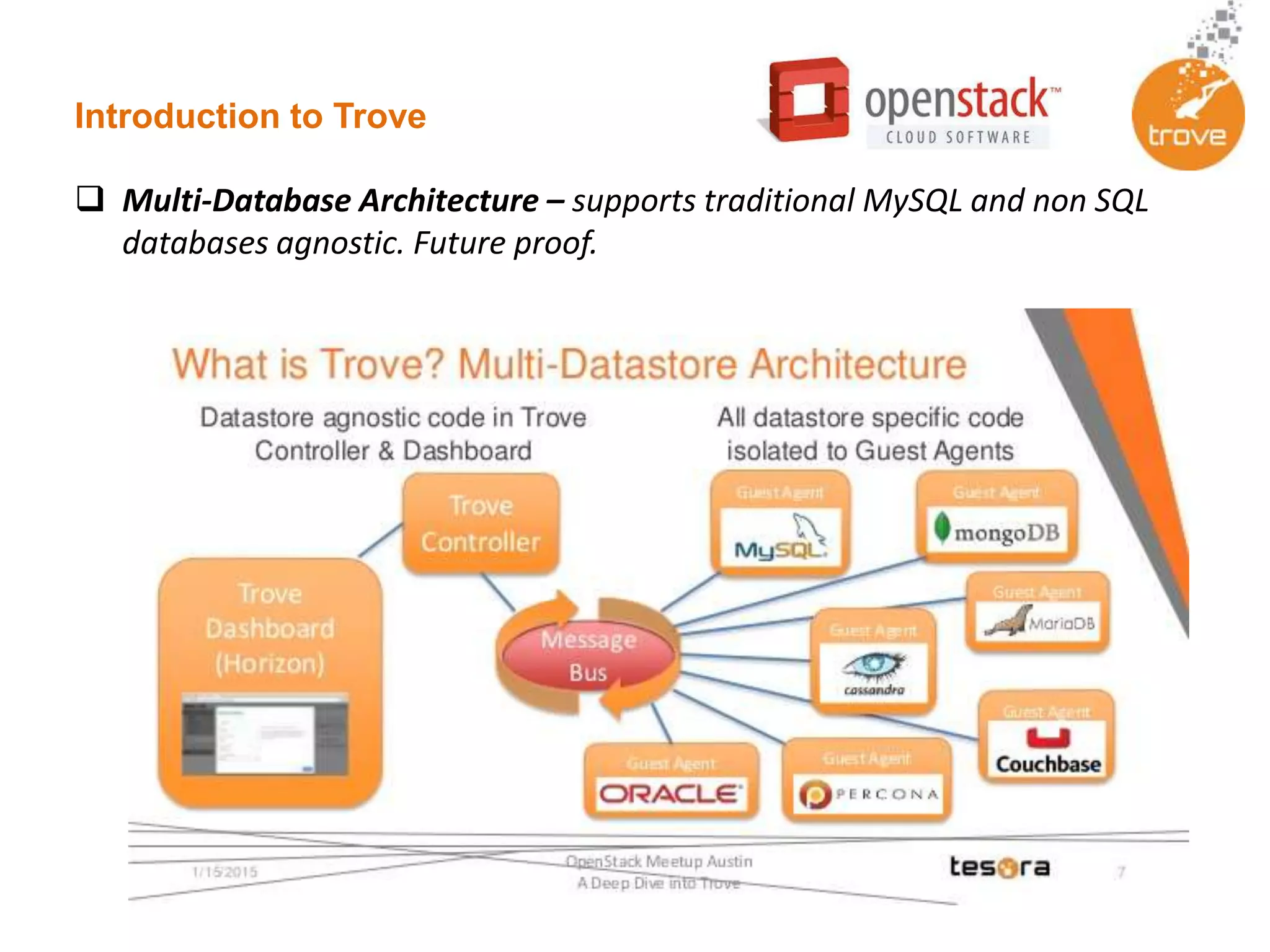
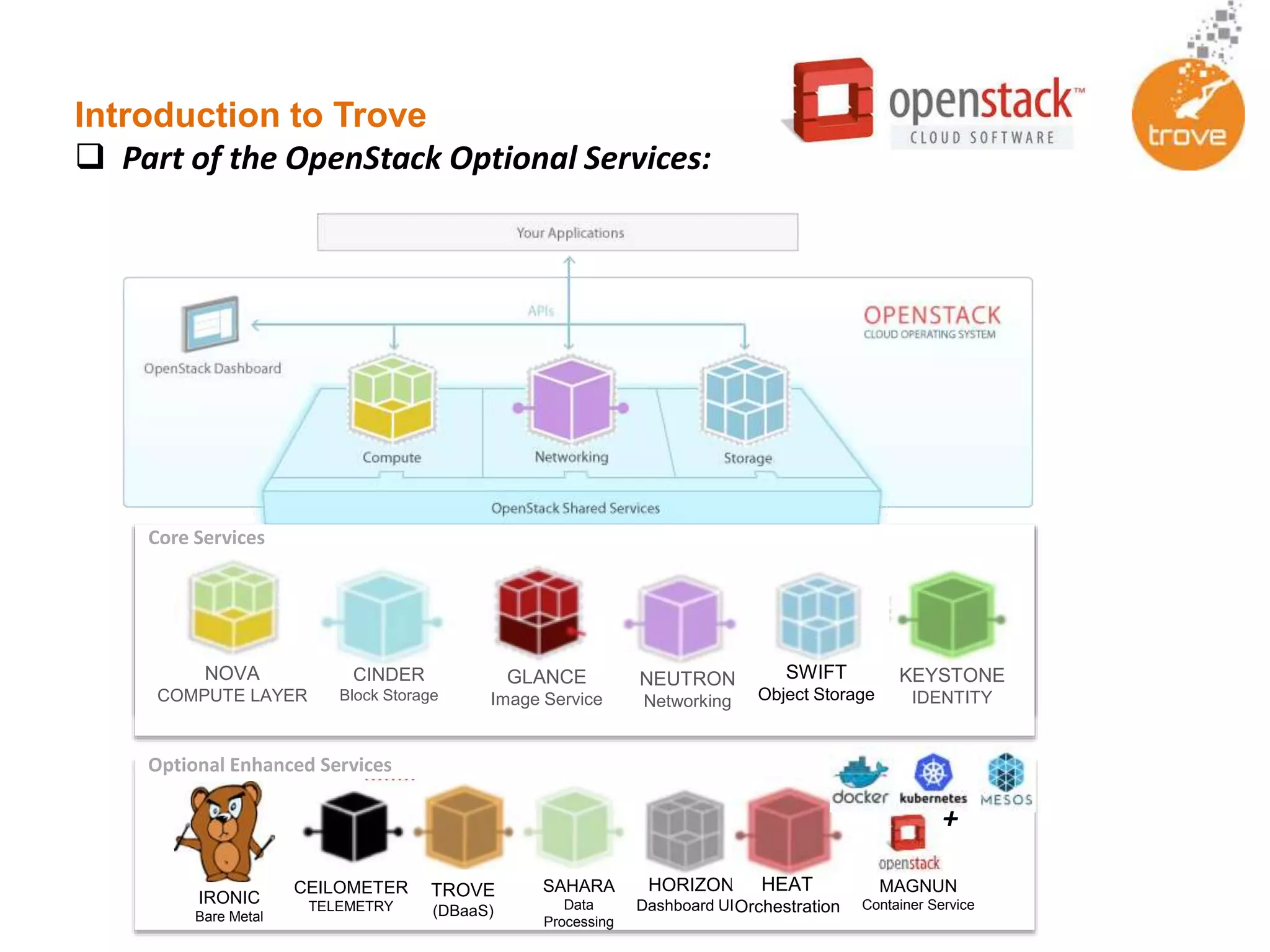
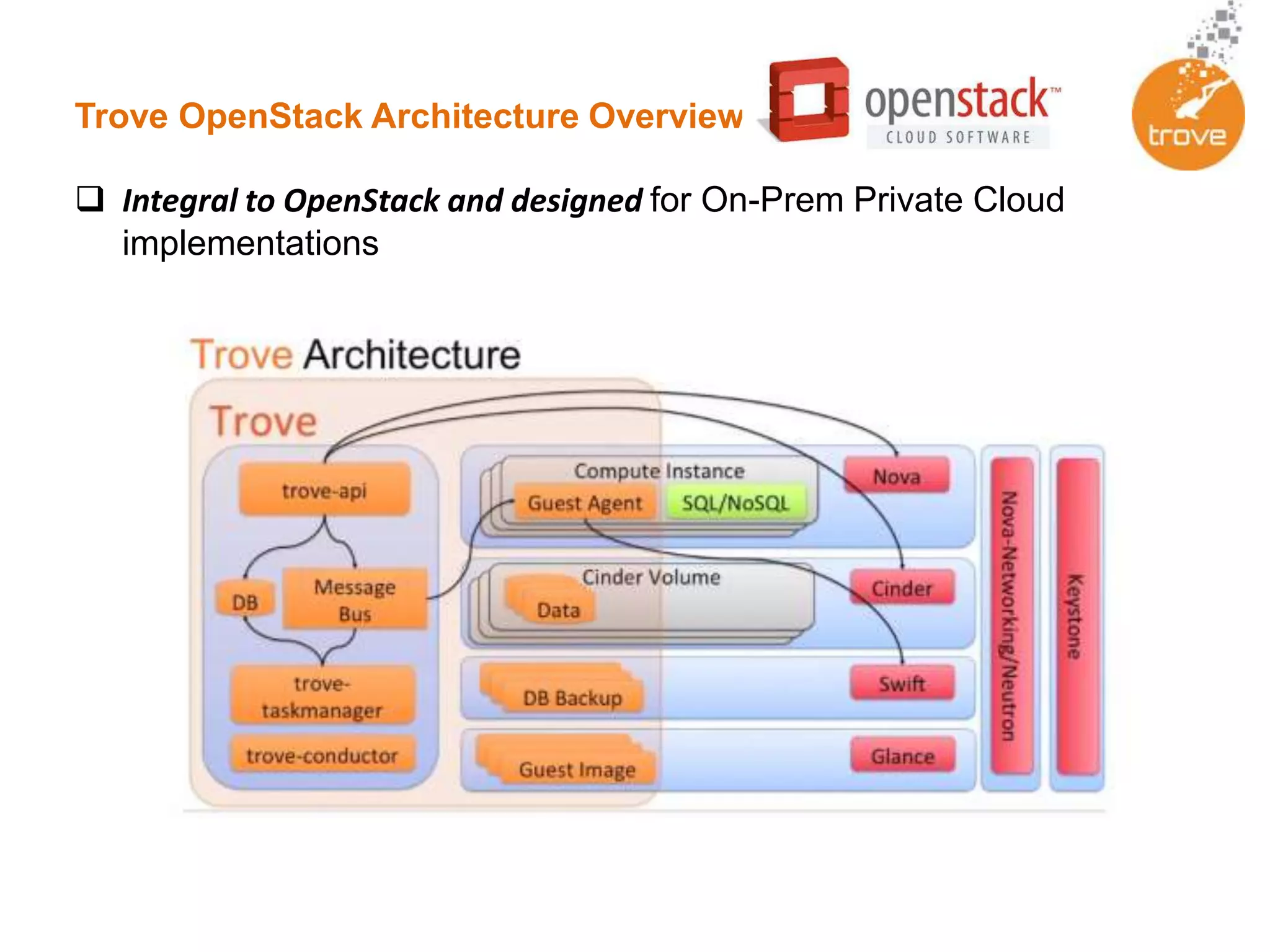
Trove is an OpenStack DBaaS that allows organizations to leverage their OpenStack infrastructure in a cost-effective way to deploy solutions built upon traditional databases. Trove provides a unified solution for all database types and can provide cost and resource savings through reduced complexity. It allows rapid provisioning of database instances, standardized infrastructure, and self-service capabilities for database management. Trove is integrated with OpenStack and supports both relational and non-relational databases to provide a flexible database solution.