Downloaded 62 times




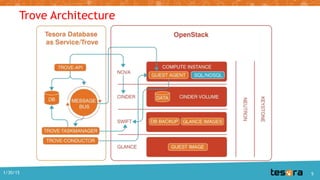
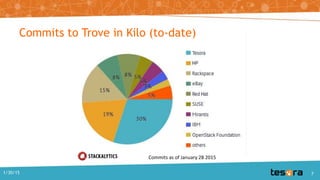












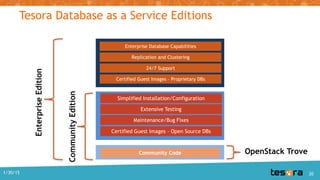
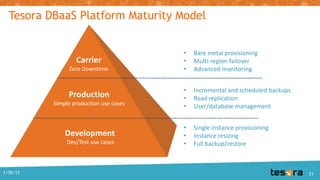


The document details the Kilo release of OpenStack Trove, a database-as-a-service project aimed at providing scalable cloud database functionality for both relational and non-relational databases. It outlines updates, architecture, and improvements, including enhanced replication and clustering frameworks, as well as plans for better documentation and technical debt resolution. The document also mentions the Tesora database service built on Trove, emphasizing self-service provisioning and data protection.




















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)


