Download as PDF, PPTX







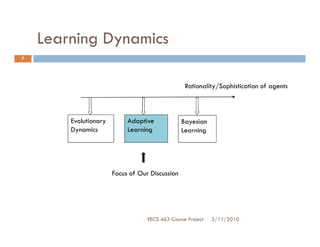

















The document discusses adaptive learning techniques in games. It describes how agents can learn optimal strategies through repeated play rather than computing equilibrium strategies. Specifically, it outlines fictitious play, where agents develop a historical distribution of opponents' strategies based on past play and choose the best response. An example 2x2 game is provided where the agents update their strategy distributions over multiple rounds based on fictitious play learning dynamics. Gradient based learning is also mentioned as an alternative approach where agents perform gradient ascent on their expected payoff function.















































