






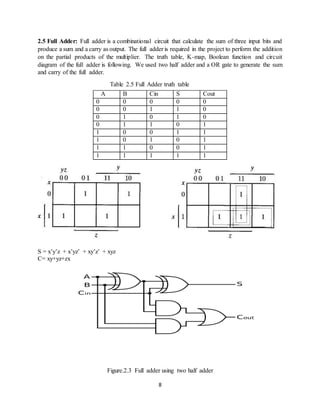


![11
2.7 Ripple carry Adder: The Ripple carry adder is designed by cascading full adders in series.
In, project we required a 25 bit adder to add the final outputs of the multiplier. The design of a n-
bit ripple carry adder is given below.
Figure.2.7 n-bit Ripple carry adder
The delay of a n bit adder is n full adder delay. So, 25 bit adder has a 25 full adder delay which is
very large.
The simulation result of the ripple carry adder is given below.
Figure.2.8 Simulation result of 25 bit Ripple carry adder
2.8 Manchester carry Adder: Manchester carry adder has very small delay and useful to reduce
the delay if the circuit. Carry propagate and generate action is taken place initially and go to the
select line of the multiplexer. The half adder is used to propagate and generate. The Boolean
function for propagate and generate is given below.
Gi = Ai Bi --carry generate of ith stage
Pi = Ai Bi --carry propagate of ith stage
Si = Pi Ci --sum of ith stage
Ci+1 = Gi + PiCi --carry out of ith stage
The design of a 16 bit Manchester carry adder is given below. The 25 bit Manchester carry adder
can be constructed by adding cells in series.
2.9 Multiplexer: Mux is a combinational circuit that select one of the input and forward the input
to the output. Select line is used to select the input. A multiplexer 2^n has [n] select lines. Here, to
design the Manchester adder, we need a 2^1 mux. The Select circuit diagram and truth table and
Boolean function of 2^1 mux is given below.](https://image.slidesharecdn.com/rep-171215110937/85/8-bit-Multiplier-Accumulator-11-320.jpg)

























The project report details the design and simulation of a multiplier accumulator circuit capable of multiplying two 8-bit numbers and storing results in registers. It outlines the components used, including combinational and sequential circuits like adders and registers, along with their respective truth tables and design simulations. The contributions of team members and the overall project methodology are also discussed, highlighting the collaborative efforts in creating and documenting the project.















































































