Download as PDF, PPTX


![MLP (Multi Layer Perceptron: 多層パーセプトロン)
∑
x[j]
w[j][k]
n[k] u[k]
②活性関数
b1
入力x 出力u 出力y
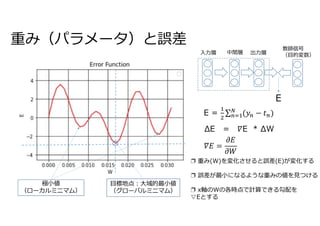
入力層(x) 中間層(u) 出力層
(y)
教師信号t
誤差E
教師信号(目的変数)
E =
③ 損失(誤差)関数
=
b2
① 総入力(加重総和)関数
多層パーセプトロンは、3つの層、3つの関数から構成される。
① 総入力(加重総和)関数
② 活性関数
③ 損失(誤差)関数
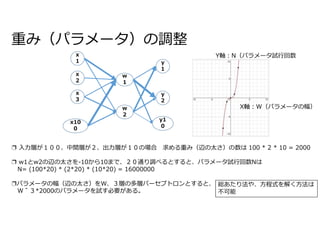
重みW1 重みW2
ステップ関数の話
パーセプトロンの内部構造](https://image.slidesharecdn.com/78backpropagation-220102044419/85/78-3-320.jpg)
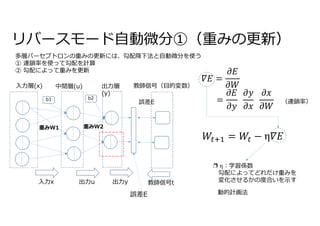
![リバースモード自動微分②(勾配の計算)
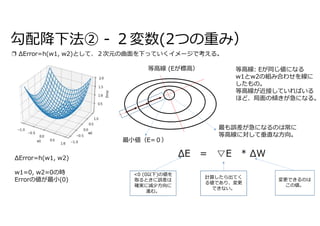
E = y
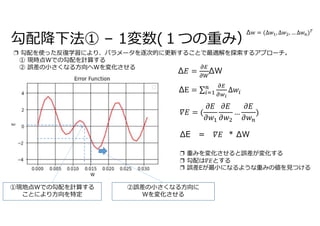
勾配
加重総和関数の微分
損失関数の微分
=
活性関数の微分
∑
x[j]
w[j][k]
u[k] y[k]
重みの更新式
勾配𝛻𝐸は、損失関数、活性関数、加重総和関数をそれぞれ偏微分をしたものをまとめたものになる。](https://image.slidesharecdn.com/78backpropagation-220102044419/85/78-9-320.jpg)
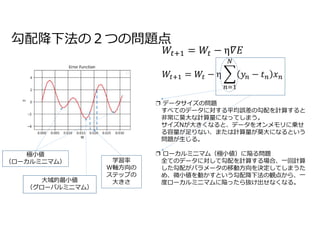
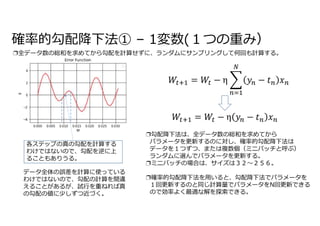
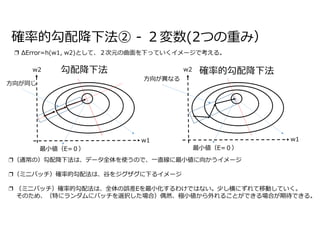
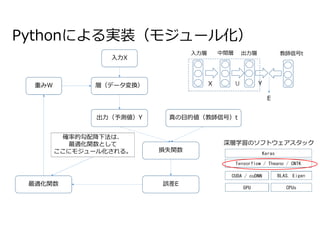


鉄板トピックの誤差逆伝播について40分ほど話しました。 ❏ 多層パーセプトロン ❏ 勾配降下法 ❏ リバースモード自動微分 ❏ 確率的勾配降下法 ❏ 実装(モジュール化) Rumelhart, David E.; Hinton, Geoffrey E., Williams, Ronald J. (8 October 1986). “Learning representations by back-propagating errors”. Nature 323 (6088): 533–536. doi:10.1038/323533a0.




![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)









![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-181212011918-thumbnail.jpg?width=640&height=640&fit=bounds)






![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)
























