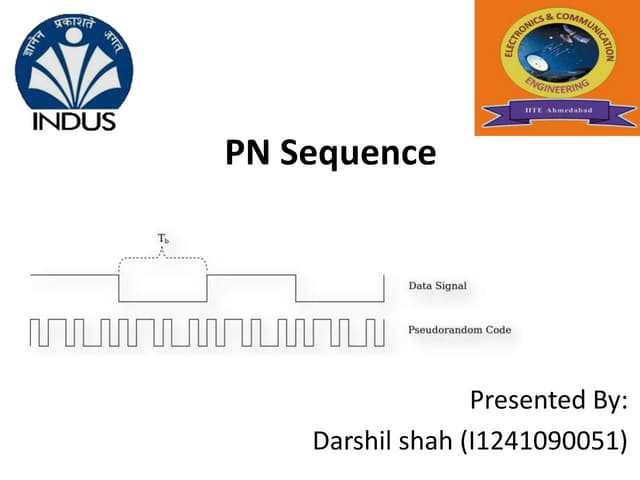
Downloaded 182 times



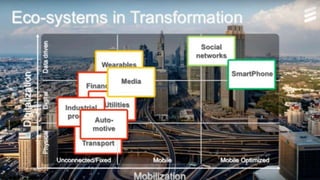
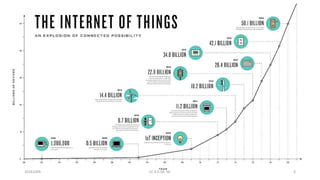

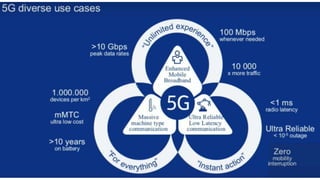
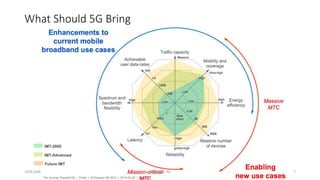
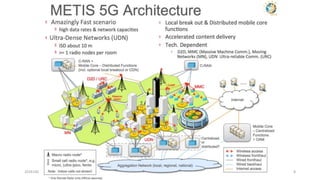
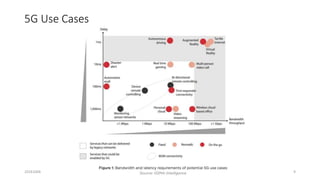



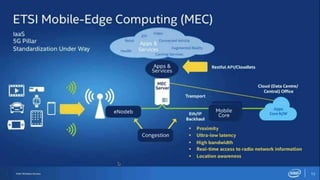
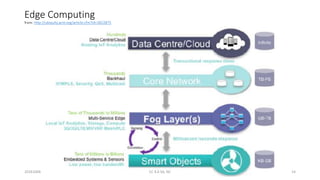

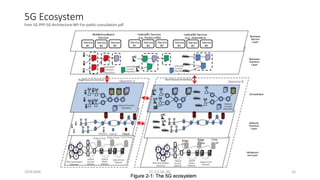
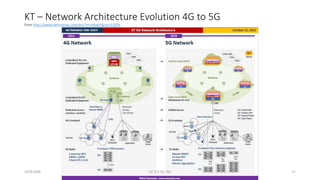
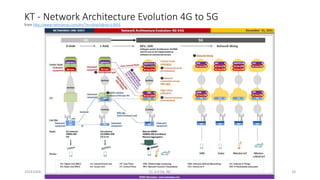
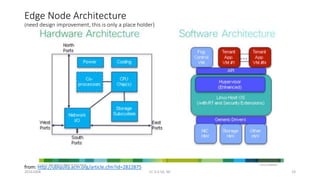
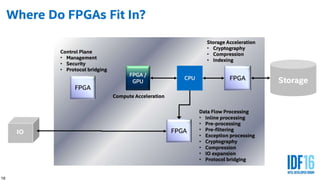


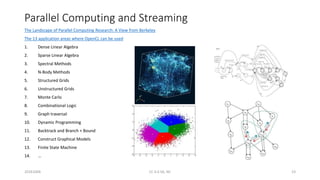
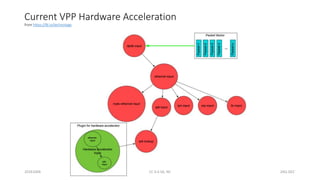
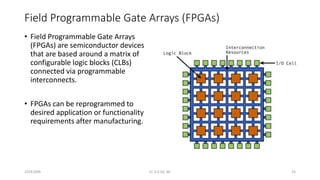




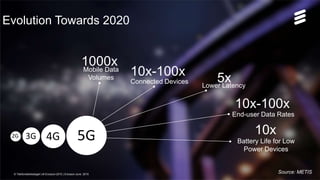

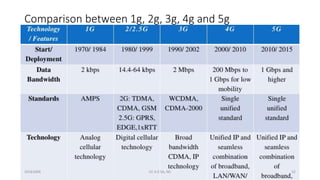
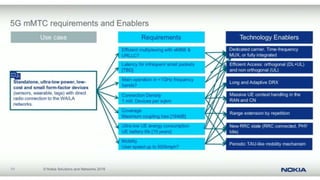
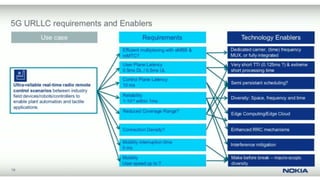


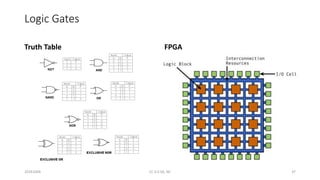
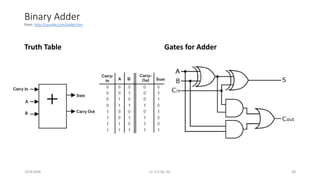



The document discusses trends in telecom infrastructure including digitalization, virtualization, and mobility that are increasing data volumes and requiring more advanced data processing. It highlights edge computing, graphics processing units (GPUs), and field programmable gate arrays (FPGAs) as technologies that can help meet these demands. Edge computing distributes computing power and data storage closer to end users to reduce latency and network loads. GPUs and FPGAs can provide increased computing power for tasks like machine learning and help customize network nodes. The document also examines how these technologies may support the evolution to 5G networks through features like network slicing and distributed analytics.