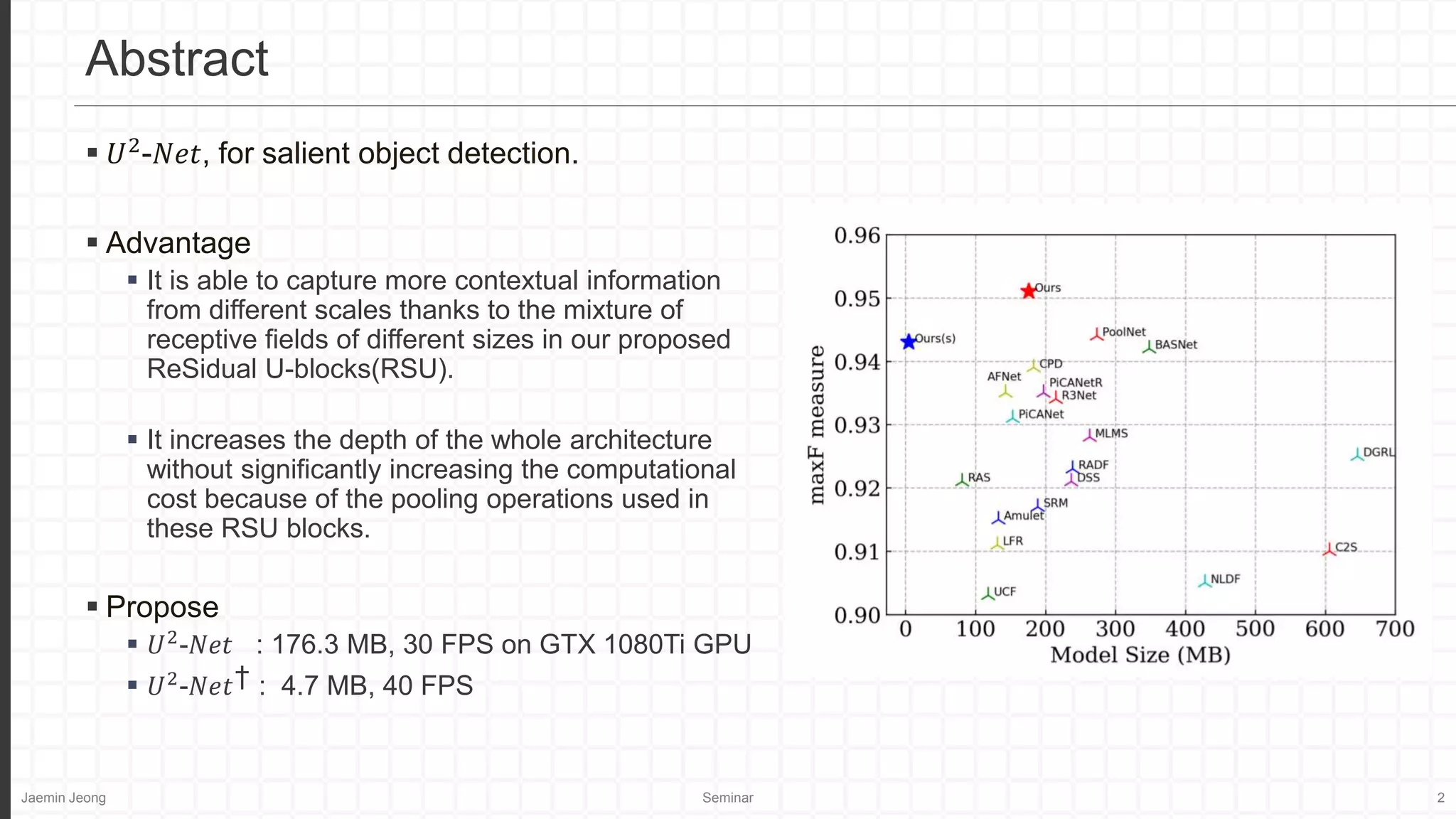
U2-Net is a novel deep network for salient object detection that uses a two-level nested U-structure with newly designed residual U-blocks (RSU) to capture multi-scale contextual information with increased depth but limited computational cost. The proposed U2-Net achieves competitive results against state-of-the-art methods on various datasets while providing a full-size model (176.3 MB, 30 FPS) and a smaller model (4.7 MB, 40 FPS) for constrained devices.





![Jaemin Jeong Seminar 11
𝑈2
-𝑁𝑒𝑡
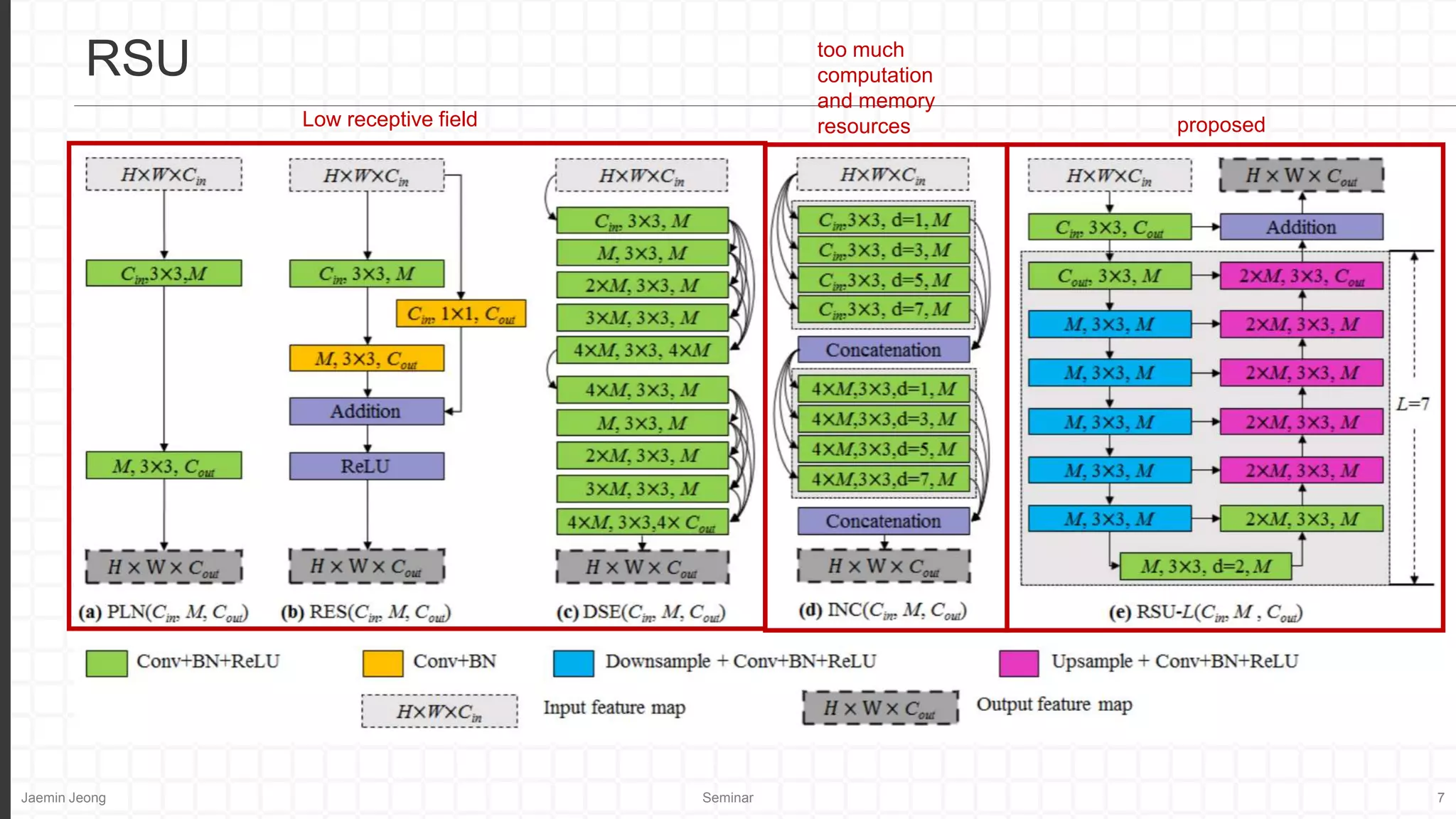
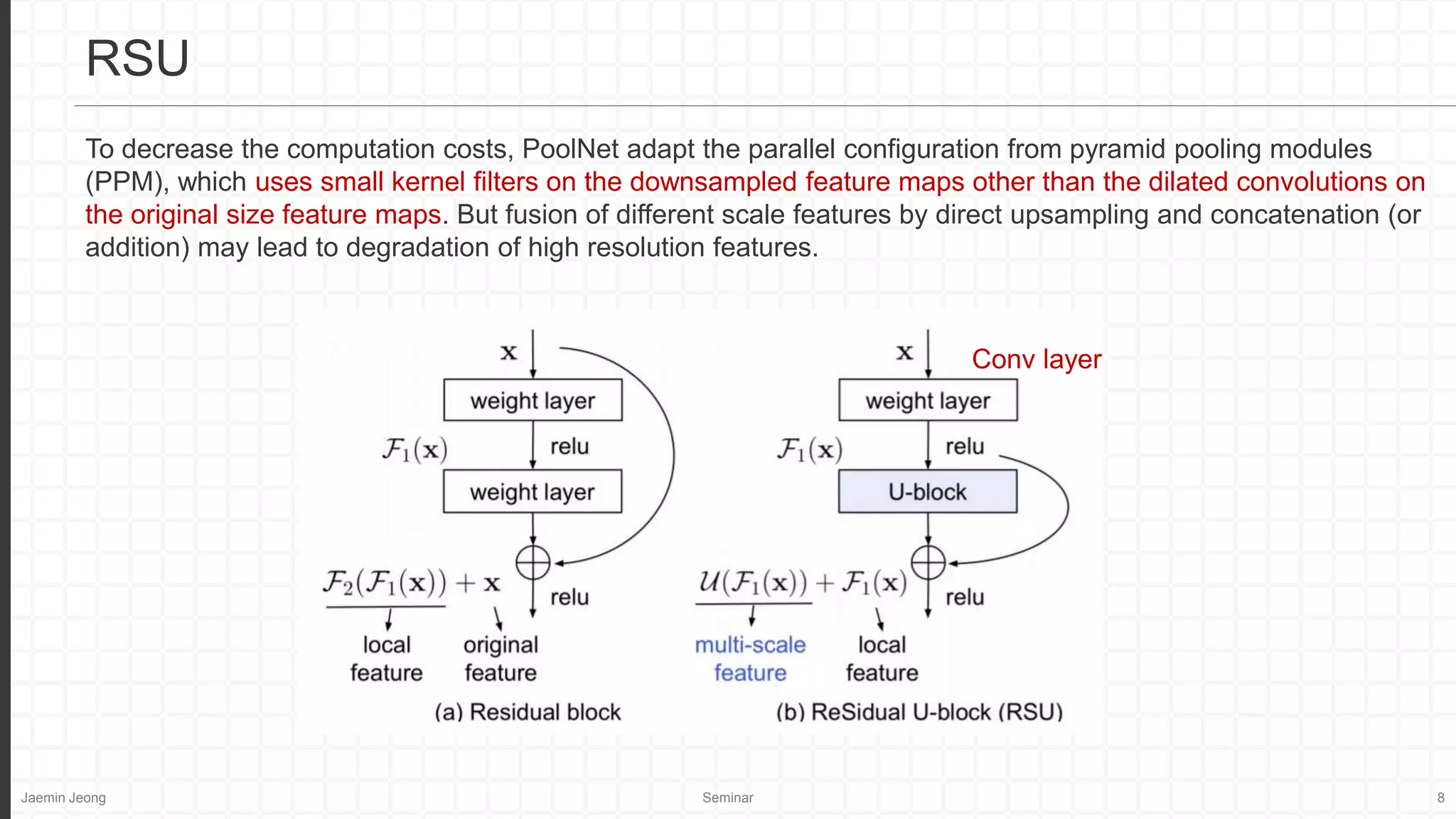
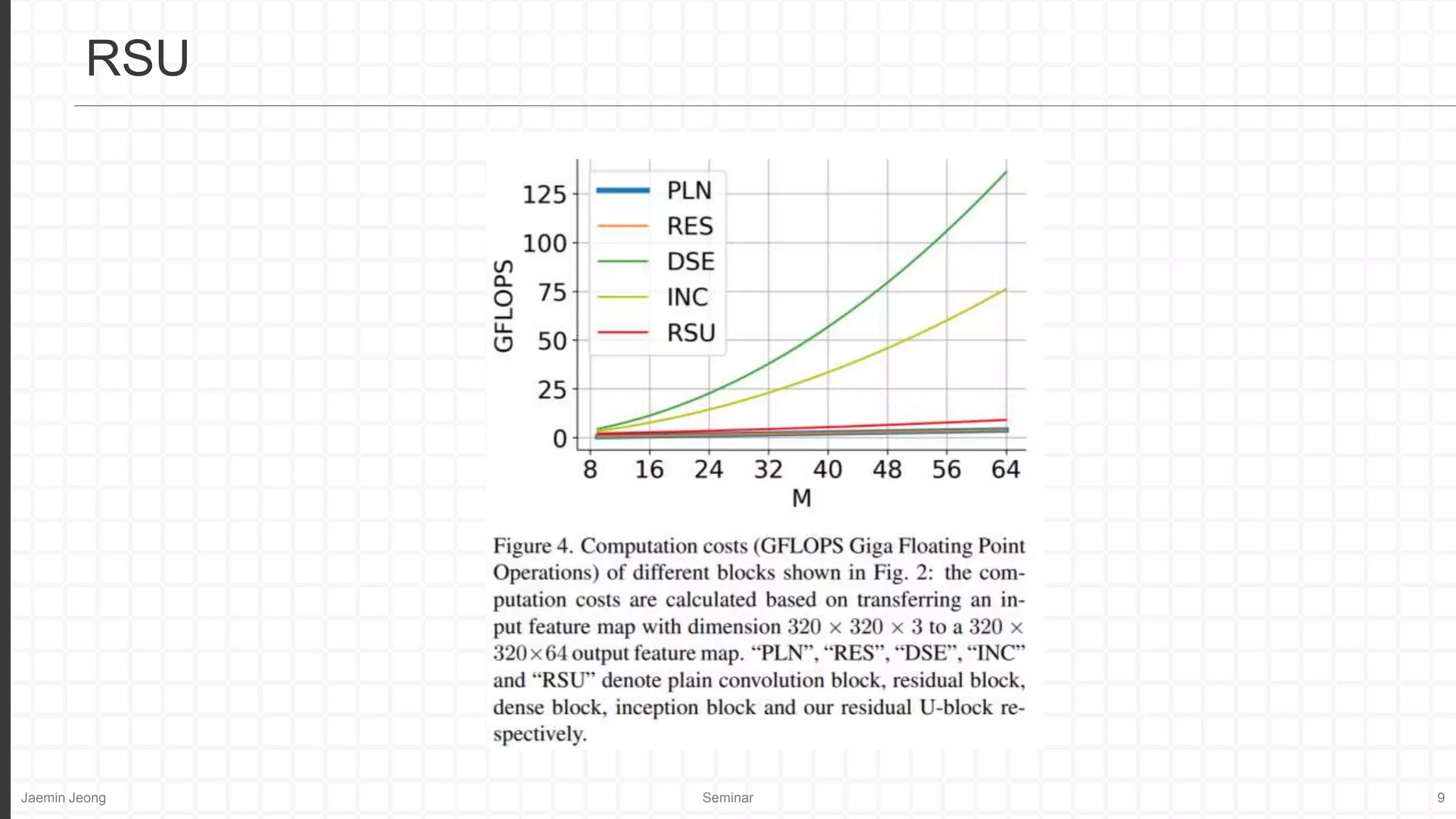
Relatively low resolution.
RSU-
4F
𝐿 =
𝑚=1
𝑀
𝑤𝑠𝑖𝑑𝑒
𝑚
ℓ𝑠𝑖𝑑𝑒
(𝑚)
+ 𝑤𝑓𝑢𝑠𝑒ℓ𝑓𝑢𝑠𝑒
ℓ𝑠𝑖𝑑𝑒
(𝑚)
: loss of the side output saliency
map
ℓ𝑓𝑢𝑠𝑒 : loss of the final output saliency
map
ℓ = −
(𝑟,𝑐)
(𝐻,𝑊)
[𝑃𝐺 𝑟,𝑐 log 𝑃𝑆(𝑟,𝑐) + 1 − 𝑃𝐺 𝑟,𝑐 log(1 − 𝑃𝑆(𝑟,𝑐))]
Binary Cross Entropy
𝑃𝐺(𝑟,𝑐) = Ground Truth
𝑃𝑆(𝑟,𝑐) = Predicted
𝑤
𝑚
, 𝑤 are all set to 1.](https://image.slidesharecdn.com/2021-05-04-u2-net-210528083509/75/2021-05-04-u2-net-11-2048.jpg)





























![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)












![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)










![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)









































