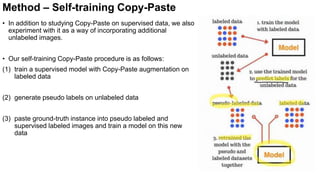
- The document presents a method called Copy-Paste for augmenting instance segmentation datasets by pasting object instances from one image into another.
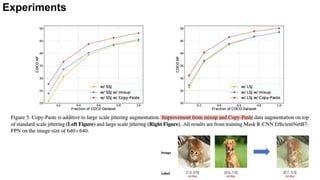
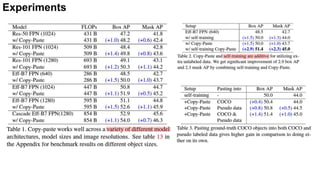
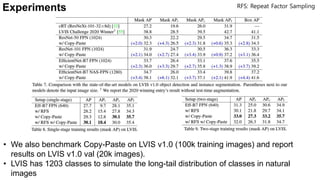
- Copy-Paste improves mask AP on COCO by +0.6 and box AP by +1.5 over previous state-of-the-art. It also improves mask AP on rare categories in LVIS by +3.6 when added to the winning entry.
- The Copy-Paste method is simple, involving randomly selecting and pasting objects between images while adjusting annotations, and provides significant gains with minimal increased training cost or inference time.











![[CVPR2020] Simple but effective image enhancement techniques](https://cdn.slidesharecdn.com/ss_thumbnails/simplebuteffectiveimageenhancementtechniques-200617034047-thumbnail.jpg?width=640&height=640&fit=bounds)

![[論文紹介] BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/blendedmvsslideshare-200630044345-thumbnail.jpg?width=640&height=640&fit=bounds)





![[NS][Lab_Seminar_250106]SAM-Aware Graph Prompt Reasoning Network for Cross-Do...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250106gprn-250106075150-b64c5cde-thumbnail.jpg?width=640&height=640&fit=bounds)





![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_241111]Patch-Wise Graph Contrastive Learning for Image Trans...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241111patch-wisegraphcontrastivelearningforimagetranslation-241118111607-5d2d1621-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)








