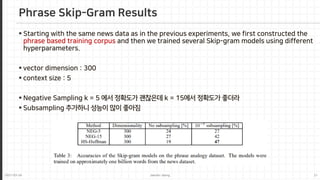
The document proposes several extensions to improve the skip-gram model for learning word embeddings, including negative sampling, subsampling frequent words, and learning phrases. It finds that these extensions lead to faster training speed and higher quality word representations compared to the original skip-gram model and other published word embeddings. The extensions allow meaningful combinations of word vectors through simple addition.









![2021-03-24 Jaemin-Jeong 11
𝐿𝐿(𝑤𝑤) : length of this path
n(w, 1) = root
n(w, L(w)) = w
[[𝑥𝑥]] : 1 if 𝑥𝑥 is true and -1 otherwise
𝜎𝜎 : 1 / (1 + exp(-x))
𝑛𝑛(𝑤𝑤, 𝐿𝐿(𝑤𝑤)) = 𝑤𝑤
𝑐𝑐𝑐(𝑛𝑛) : arbitrary fixed child of 𝑛𝑛
(항상 왼쪽 노드라고 가정해야 이해하기 쉬움)
∇ log 𝑝𝑝(𝑤𝑤𝑂𝑂|𝑤𝑤𝐼𝐼) is propotional to 𝐿𝐿(𝑤𝑤𝑂𝑂)
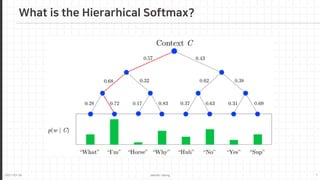
Hierarchical Softmax
𝑊𝑊
sigmoid(x) + sigmoid(-x) = 1](https://image.slidesharecdn.com/2021-03-02-distributedrepresentationsofwordsandphrases-210324140529/85/2021-03-02-distributed-representations-of_words_and_phrases-11-320.jpg)