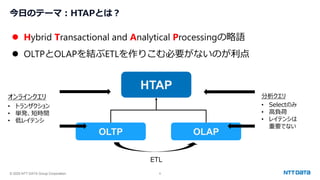
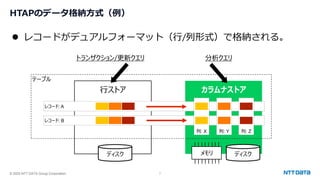
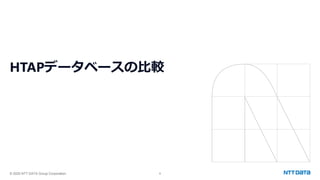
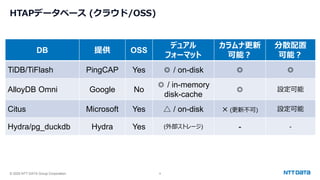
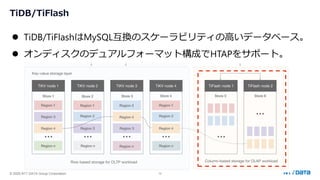
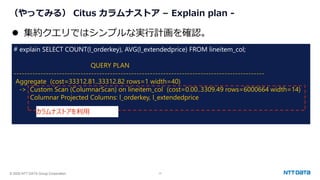
PostgreSQL最新動向 ~カラムナストアから生成AI連携まで~ (Open Source Conference 2025 Tokyo/Spring 発表資料) 2025年2月21日(金) NTTデータグループ Innovation技術部 小林 隆浩、石井 愛弓












![© 2025 NTT DATA Group Corporation 20
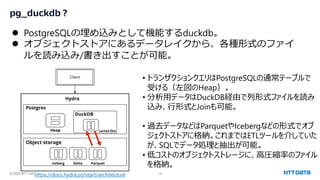
(やってみる)pg_duckdb+オブジェクトストレージ
⚫ Google Cloud Storage上のParquetのファイルを読み取る例。
⚫ PostgreSQLへのファイルロードは不要、処理も高速。
# SELECT COUNT(r[‘id']),AVG(r['price']) FROM
read_parquet('gs://htap-test/items.parquet') r;
⚫ クエリの結果をS3にファイルで格納する例。
⚫ 使い慣れたSQL関数やCOPY句で、データ加工等も行いながら
データレイクへの書出しが完了。
# COPY (SELECT * FROM items ) TO 'gs://htap-test/items.parquet';](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-20-320.jpg)









![© 2025 NTT DATA Group Corporation 33
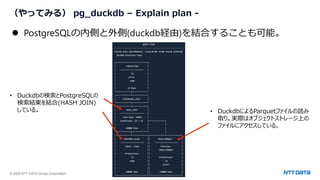
1.ベクトル検索+スカラー属性フィルタリング
例)商品名:意味的に似ている(ベクトル検索) & カテゴリ:5(スカラーフィルタリング)
SELECT * FROM items WHERE category_id = 5 ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
☆高速に検索するためには?
• 一致する行の割合が小さいとき…
• フィルタ列に対するインデックスを作成する
• CREATE INDEX ON items (category_id);
• 近似インデックスは使わないので、抜け漏れが発生しない
• 一致する行の割合が大きいとき…
• ベクトル列に対する近似インデックスを作成する
• CREATE INDEX ON items USING hnsw (embedding vector_l2_ops);
• 近似インデックスなので、完全に正確ではない
• 取得される結果が少なくなる可能性あり →後述](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-33-320.jpg)


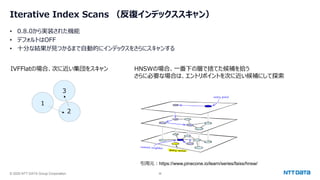
![© 2025 NTT DATA Group Corporation 37
Iterative Index Scansの結果順序のオプション
iterative_scanオプション
• off: 反復インデックススキャンを利用しない。デフォルト。
• strict_order:取得結果が厳密に距離順になる。HNSWのみ。 IVFFlatは選択できない。
• relaxed_order:取得結果が厳密に距離順でない。ただし、取りこぼしがない。IVFFlatはこっちだけ。
⇒近い集団からまずスキャンするので、基本的に見つかるベクトルとの距離は徐々に遠くなっていく
が、前のスキャンよりも短い距離のベクトルが見つかることもある。
relaxed_orderは、これをそのまま出力するので、距離順が一部入れ替わっている箇所が発生しうる
strict_orderは、短い距離のベクトルが見つかったら、結果を破棄するので、必ず昇順になるが、結果が減る
結果を失わず、順序を厳密にしたいときは?
• relaxed_orderで取得した結果を、マテリアライズドCTEとして、最後に並び替える
例)
WITH nearest_results AS MATERIALIZED (
SELECT id, embedding <-> '[1,2,3]' AS distance FROM items ORDER BY distance LIMIT 5
) SELECT * FROM nearest_results WHERE distance < 5 ORDER BY distance;](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-37-320.jpg)


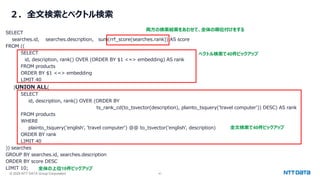
![© 2025 NTT DATA Group Corporation 40
2.全文検索とベクトル検索
例)商品の説明:意味的に似ている(ベクトル検索)& 商品の説明:キーワードが含まれる(全文検索)
商品の説明(vector型)
embedding
商品の説明(text型)
[0.00058671045, -
0.004581401, .......]
世界的デザイナーAyumi Ishiiが
デザインした爽やかなグリーンの
レースをあしらったスカートです。
検索:「Ayumi Ishii 緑 スカート」
意味的な検索
⇒ 文脈や、緑=グリーンなどを捉えられる。
キーワード検索
⇒(Ayumi Ishiiなど必須なキーワードを捉えられる)
ベクトル化](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-40-320.jpg)

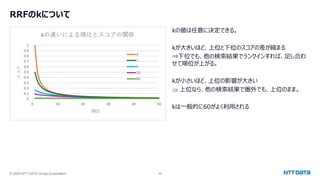
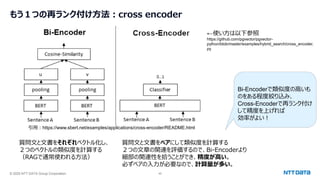

![© 2025 NTT DATA Group Corporation 47
3.ベクトル検索+疎ベクトル検索
疎ベクトルとは(対義語:密ベクトル)
• ほとんどの要素が0のベクトル [0, 0, 1, 0, 0 …]など。
• 圧縮して保存できるので、精度を落とさずサイズを小さくできる
• pgvectorでは0.7.0からsparsevec型が追加された。
CREATE TABLE items (id bigserial PRIMARY KEY, embedding sparsevec(5));
INSERT INTO items (embedding) VALUES ('{1:1,3:2,5:3}/5'), ('{1:4,3:5,5:6}/5’);
表記方法
• {インデックス:値, インデックス:値,…}/次元数
• 値が0以外のところだけ書く。あとは0。
• インデックスは1から始まる(0ではないので注意)
{1:1,3:2,5:3}/5 は、[1, 0, 2, 0, 3]](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-47-320.jpg)


![© 2025 NTT DATA Group Corporation 50
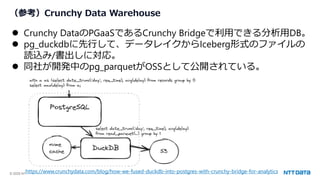
ハイブリッド検索の価値は? BGE-M3で動かしてみる。
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = ["デリシャスパーティプリキュアの主人公は誰ですか。"]
sentences_2 = ["ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。",
"デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプ
レシャスに変身します。" ]
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
print(model.compute_score(
sentence_pairs,
max_passage_length=128,
weights_for_different_modes=[0.4, 0.4, 0.2]))
密ベクトル、疎ベクトルそれぞれのスコアを計算する
↑密:疎=1:1の重みでスコアを計算
質問①
答え①
答え②
[質問①ー答え①]のペアと、[質問①ー答え②]のペア](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-50-320.jpg)
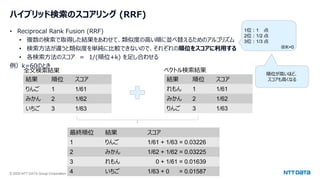
![© 2025 NTT DATA Group Corporation 51
この場合の結果
"dense": [
0.47555941343307495,
0.4559279978275299
],
"sparse": [
0.10498249530792236,
0.13451407849788666
],
"sparse+dense": [
0.29027095437049866,
0.2952210307121277
],
デリシャスパーティプリキュアの主人公は誰ですか。
1. ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。
2. デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプレシャスに変身します。
疎ベクトル(キーワードベース)では2が上。
密ベクトル(意味ベース)では1が上。
疎:密=1:1で結果を合わせると、2が上。
より正解に近いほうが
上位に来た](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-51-320.jpg)