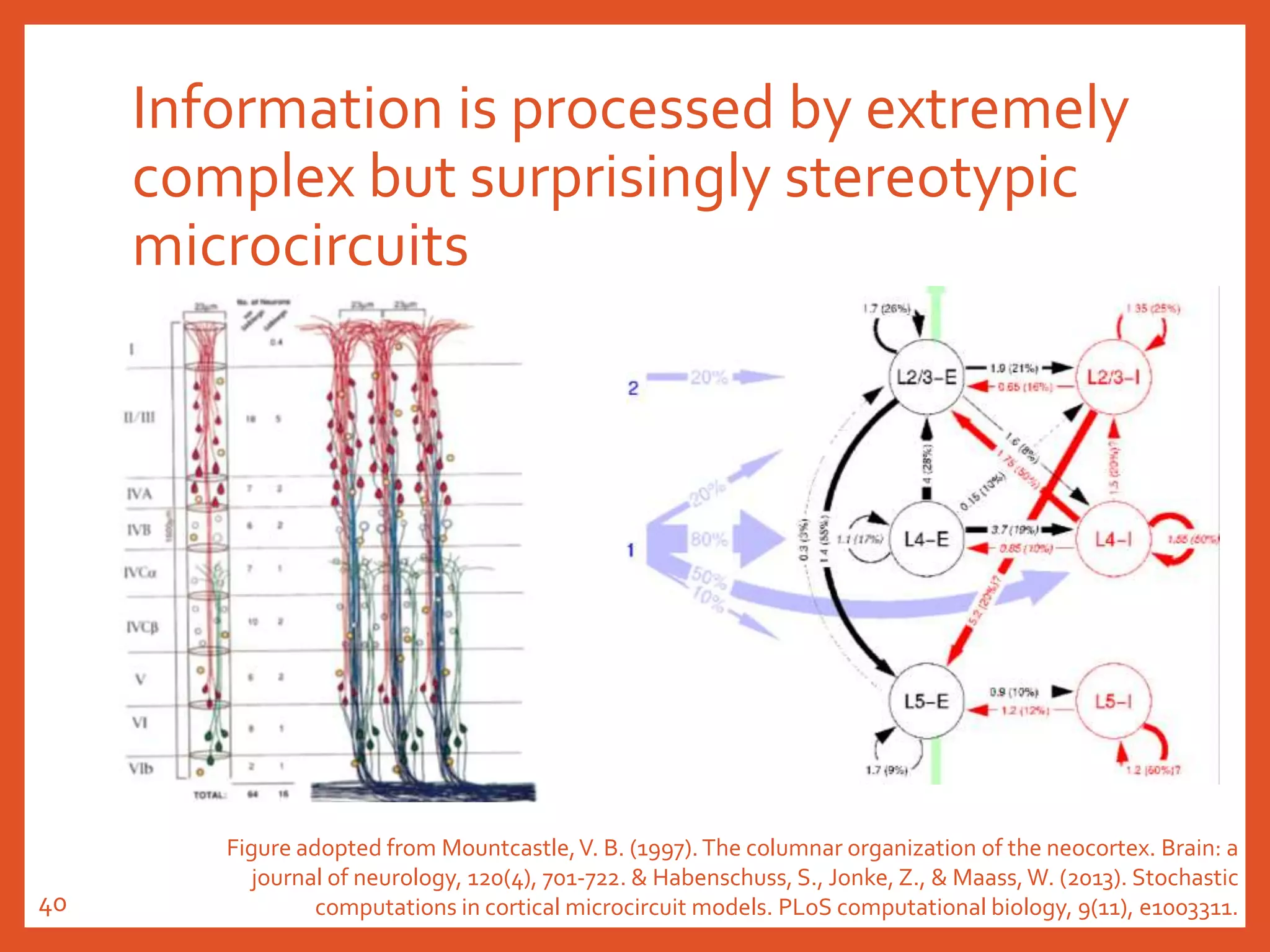
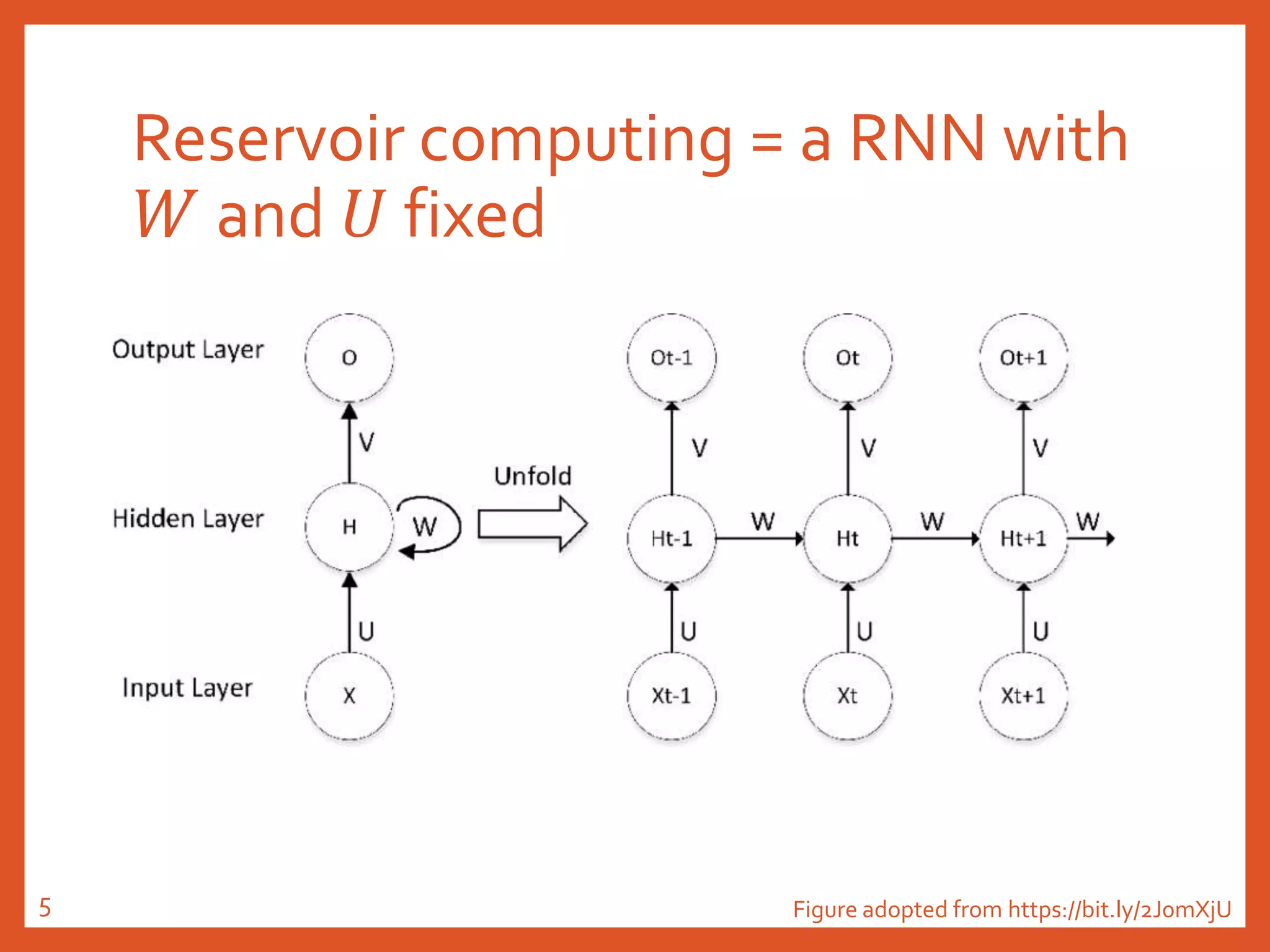
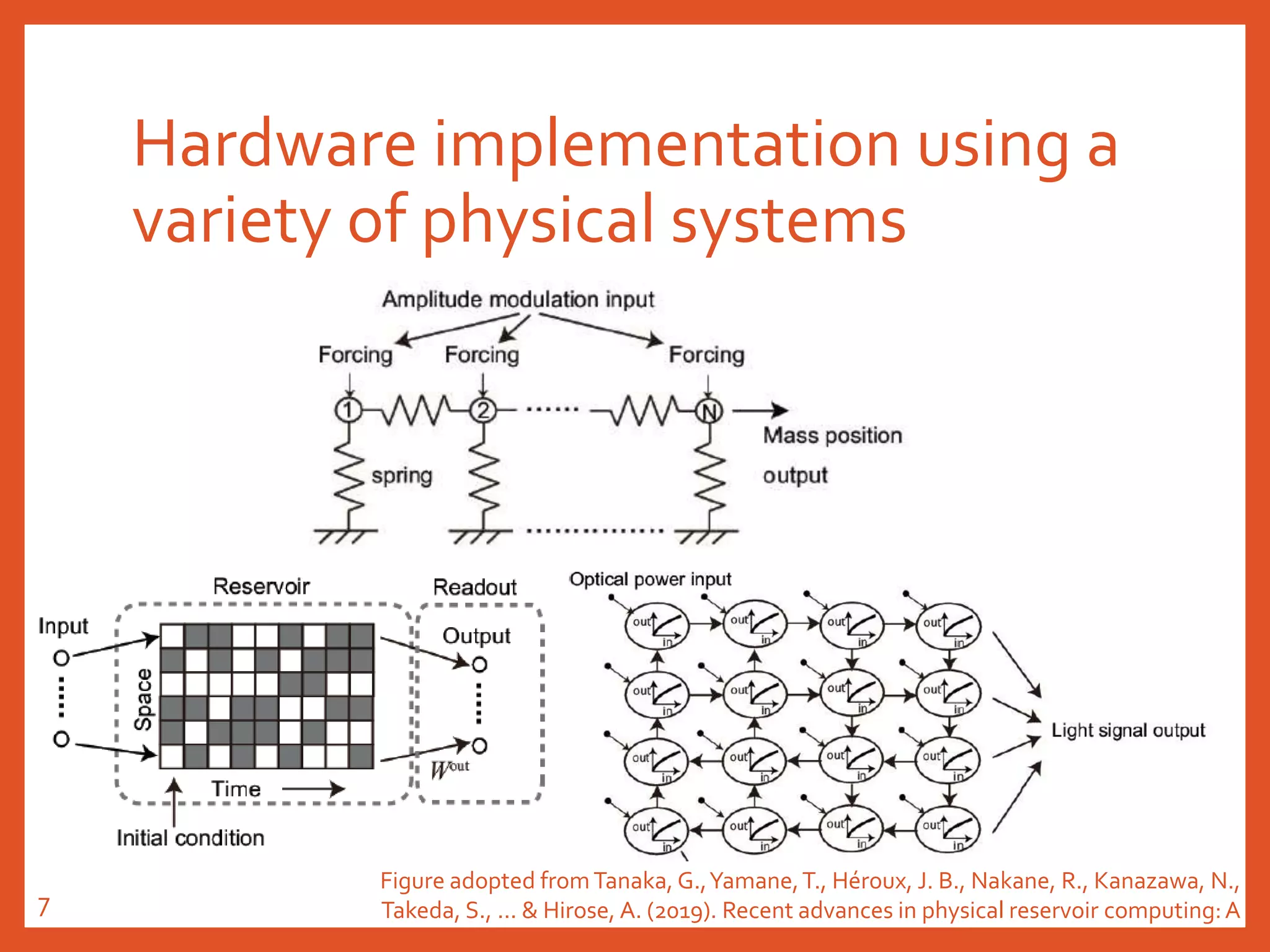
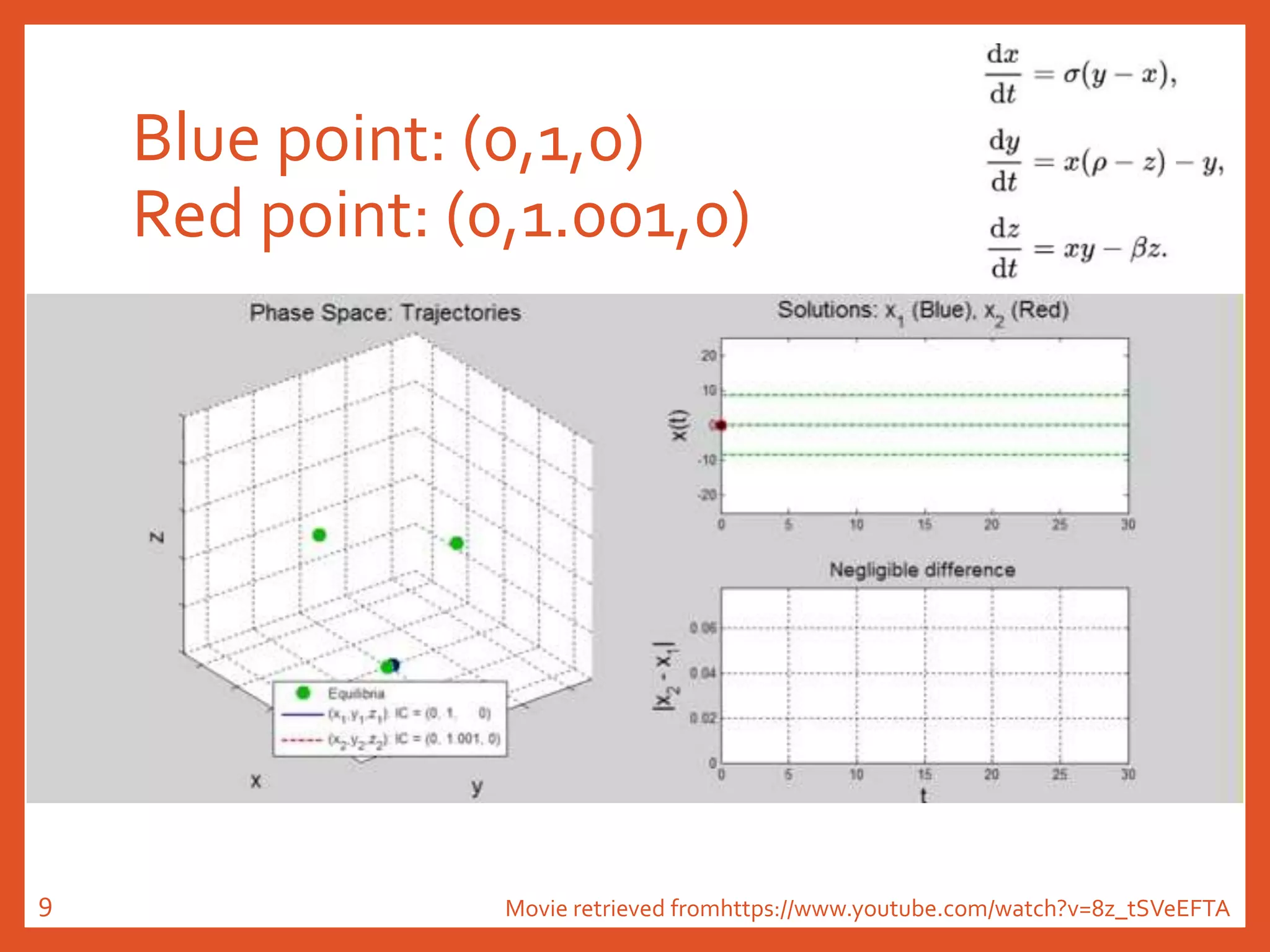
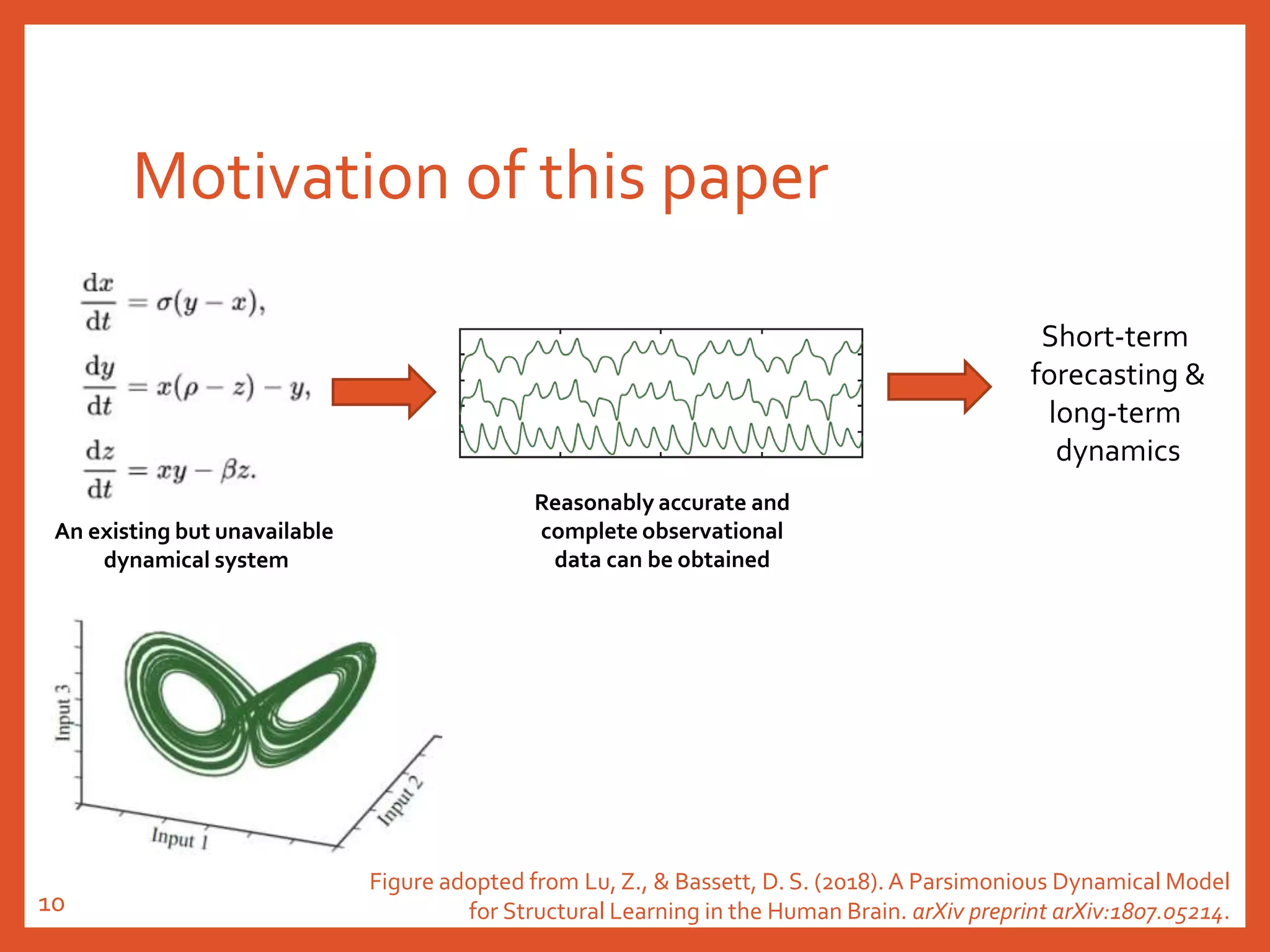
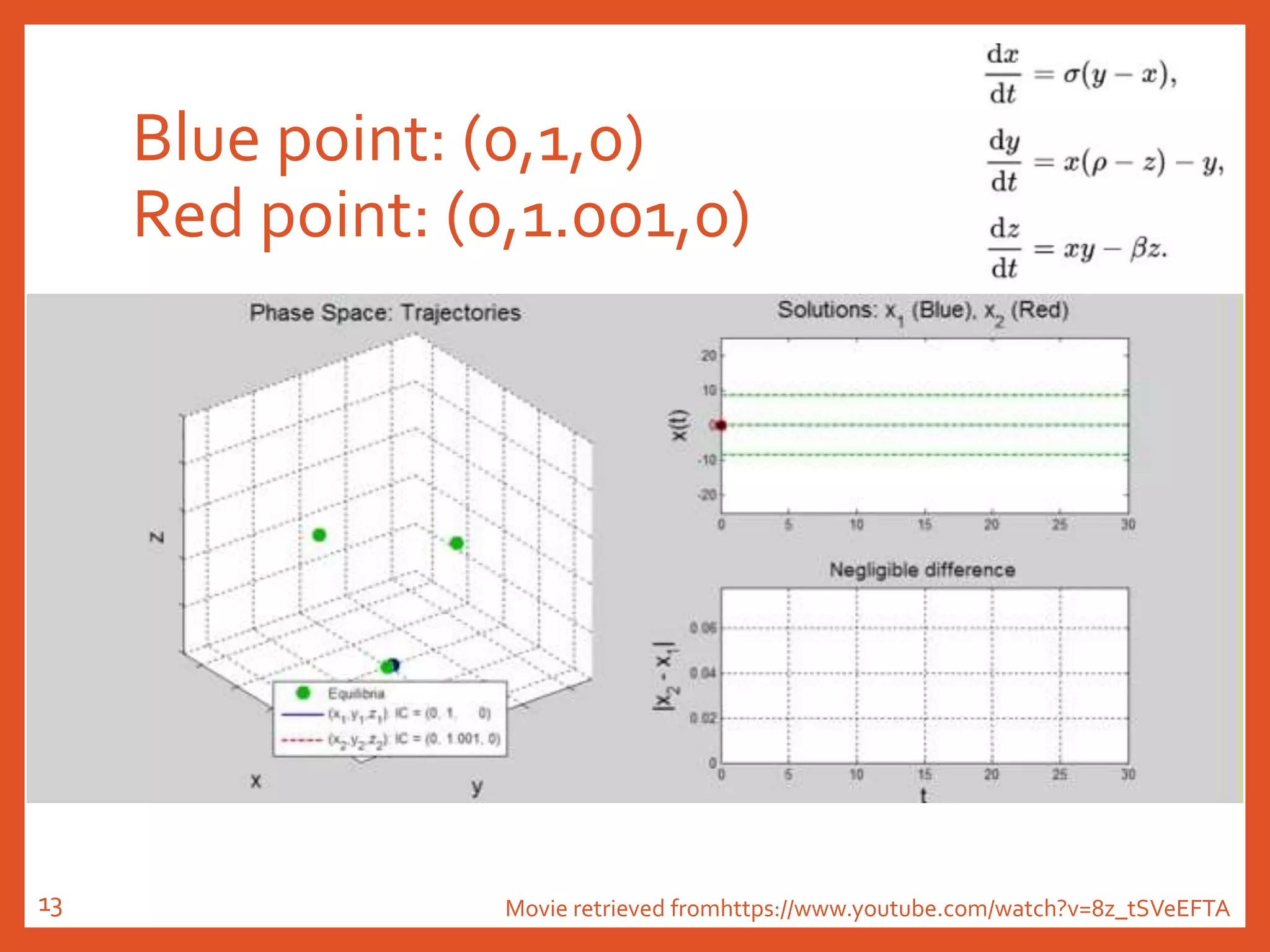
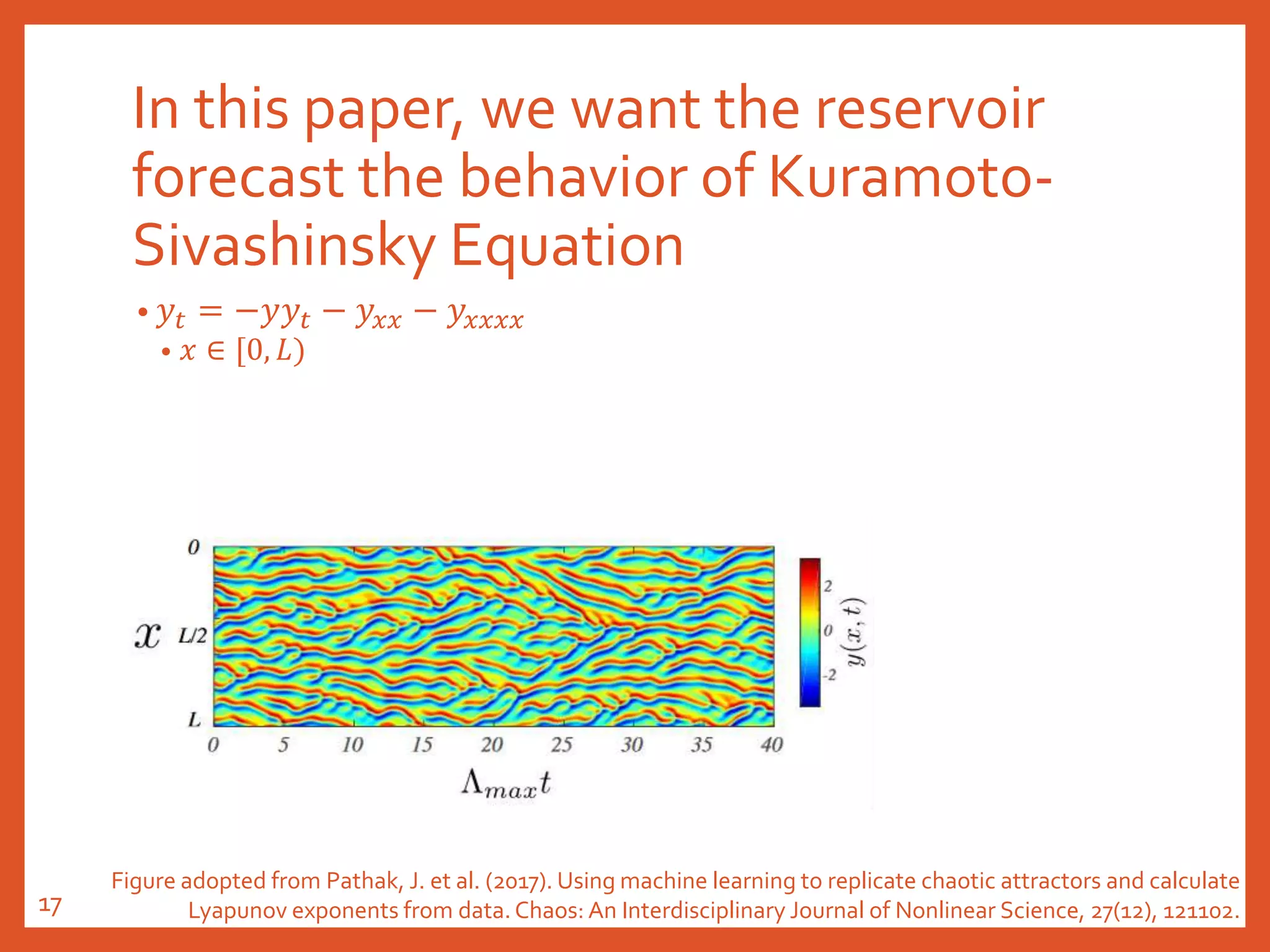
The document provides an introduction to reservoir computing from a dynamical system perspective, detailing the configuration of reservoirs, chaotic systems, and prediction mechanisms. It discusses the forecasting capabilities of reservoir computing specifically with the Kuramoto-Sivashinsky equation and highlights the fixed nature of certain parameters within the reservoir. The paper emphasizes the ability of reservoir computing to learn complex dynamical structures and make predictions based on chaotic data.




![Configuration of the Reservoir
Input: 𝑢(𝑡)
Output: u(𝑡)
State of reservoir: r(𝑡)
𝒖(𝒕)
v(𝒕)
𝒓(𝒕)
𝑾 𝒓𝒓
𝑊𝑖𝑛 and 𝑊𝑟𝑟 are fixed.
𝑊𝑜𝑢𝑡 is trainable!
Wrr: large, low-degree, directed,
random adjacent matrix
Update 𝑟(𝑡):
r t + Δt = tanh[𝐖𝐫𝐫r t + 𝐖𝐢𝐧u(t)] ,r(t)我會稱之為「reservoir的狀態」
Refer to Skibinsky-Gitlin et al. (2018, June). Cyclic Reservoir Computing with FPGA Devices for Efficient Channel
Equalization. In InternationalConference on Artificial Intelligence andSoftComputing (pp. 226-234). Springer, Cham.6](https://image.slidesharecdn.com/20191018reservoircomputing-191019030640/75/20191018-reservoir-computing-6-2048.jpg)







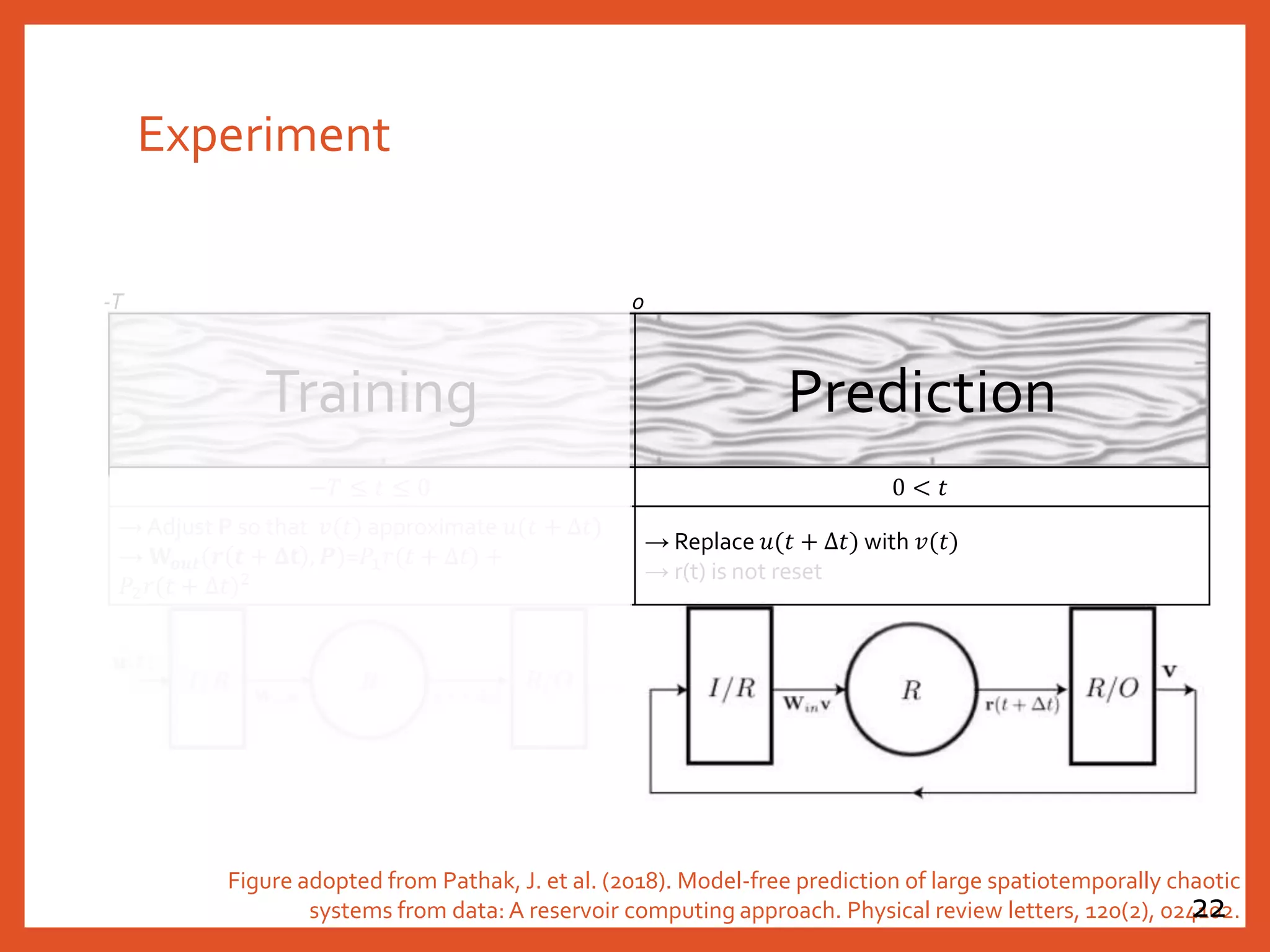
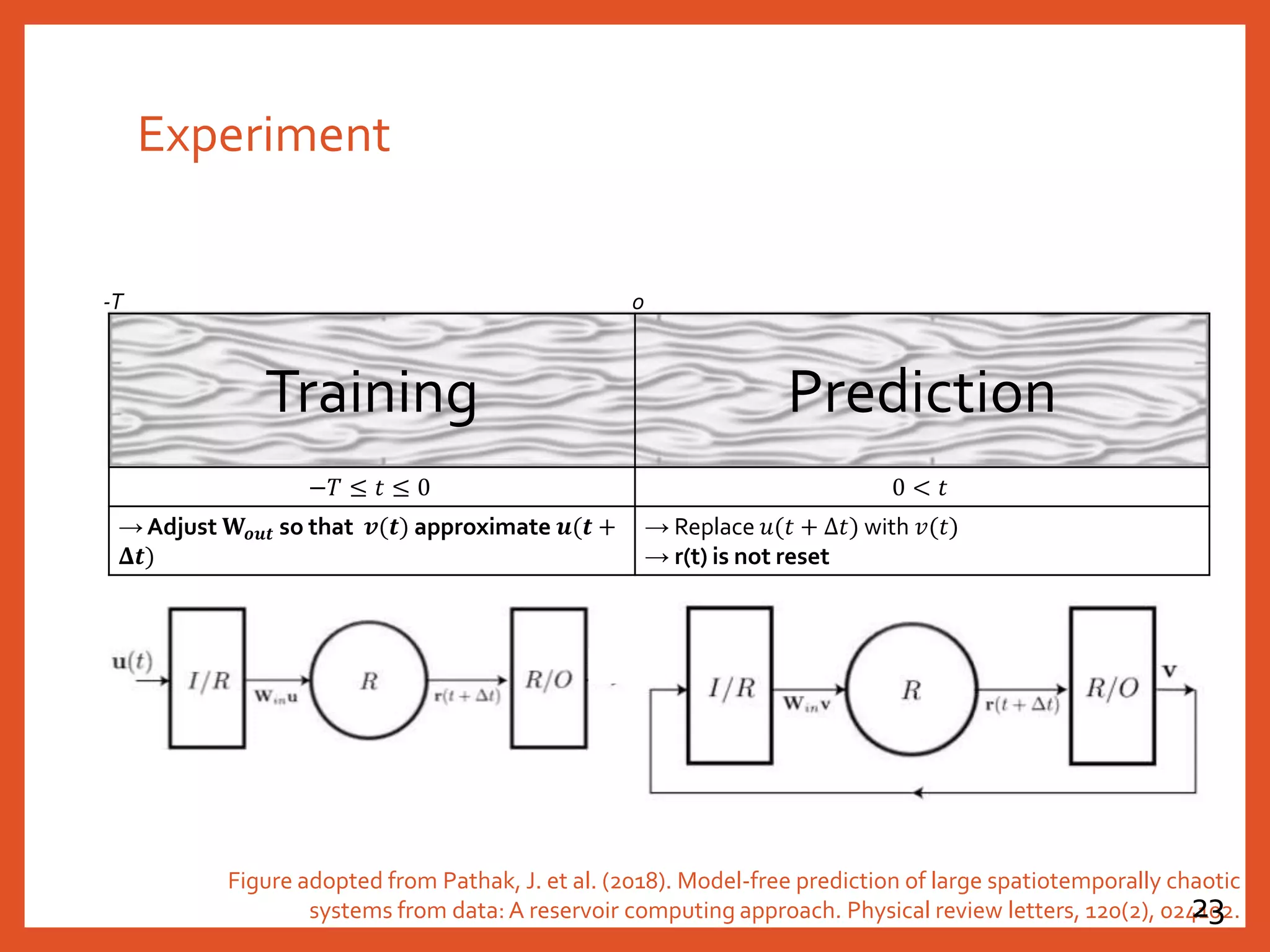
![Configuration of the Reservoir in the Paper
𝐫 𝒕
r t + Δt = tanh[𝐖𝐫𝐫 ⋅ r t + 𝐖𝐢𝐧 ⋅ u(t)] ,
v t = 𝐖𝐨𝐮𝐭 ⋅ r t
𝐖𝐢𝐧
𝐖𝒐𝒖𝒕𝐖𝐫𝐫
v 𝑡
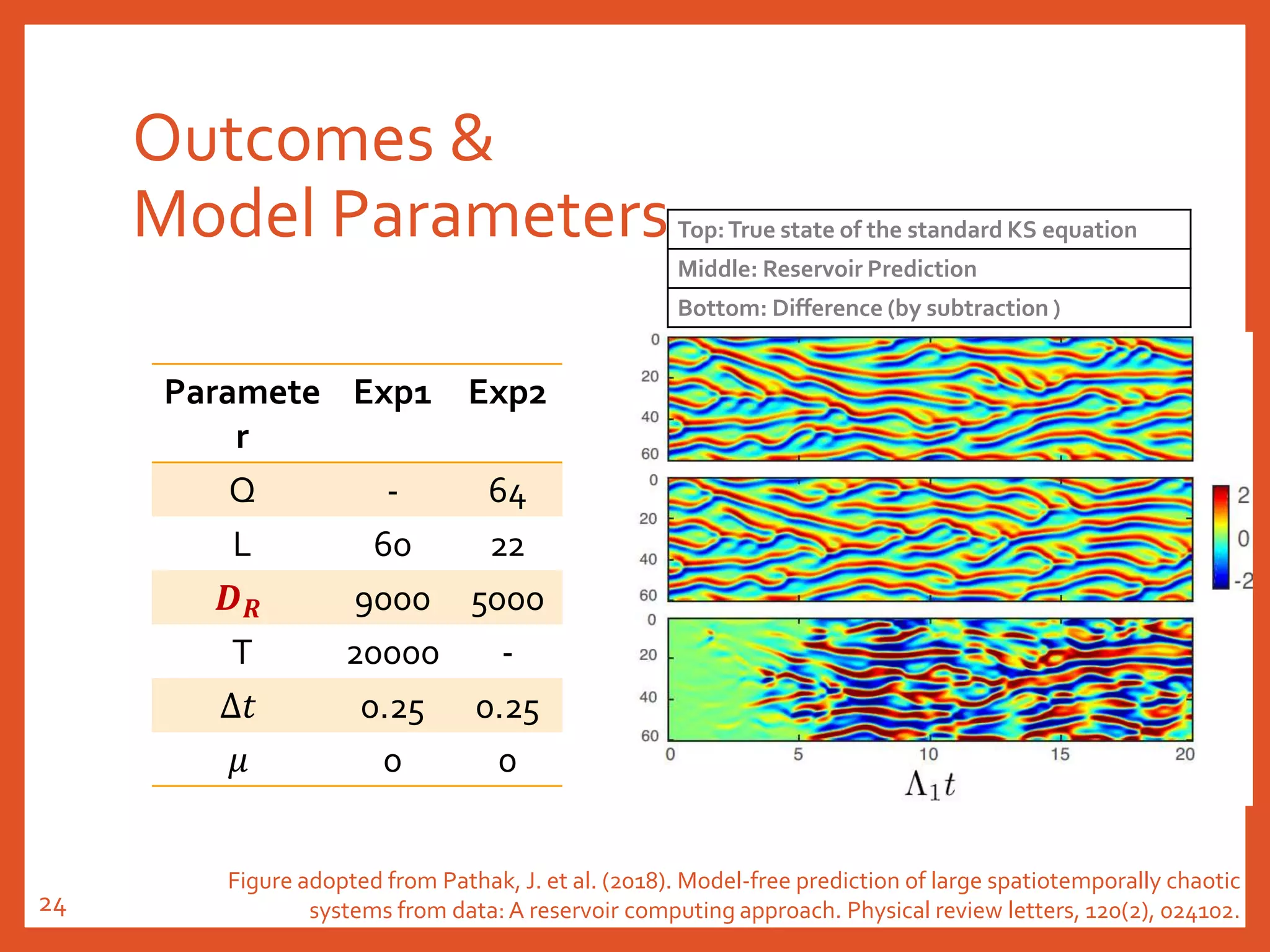
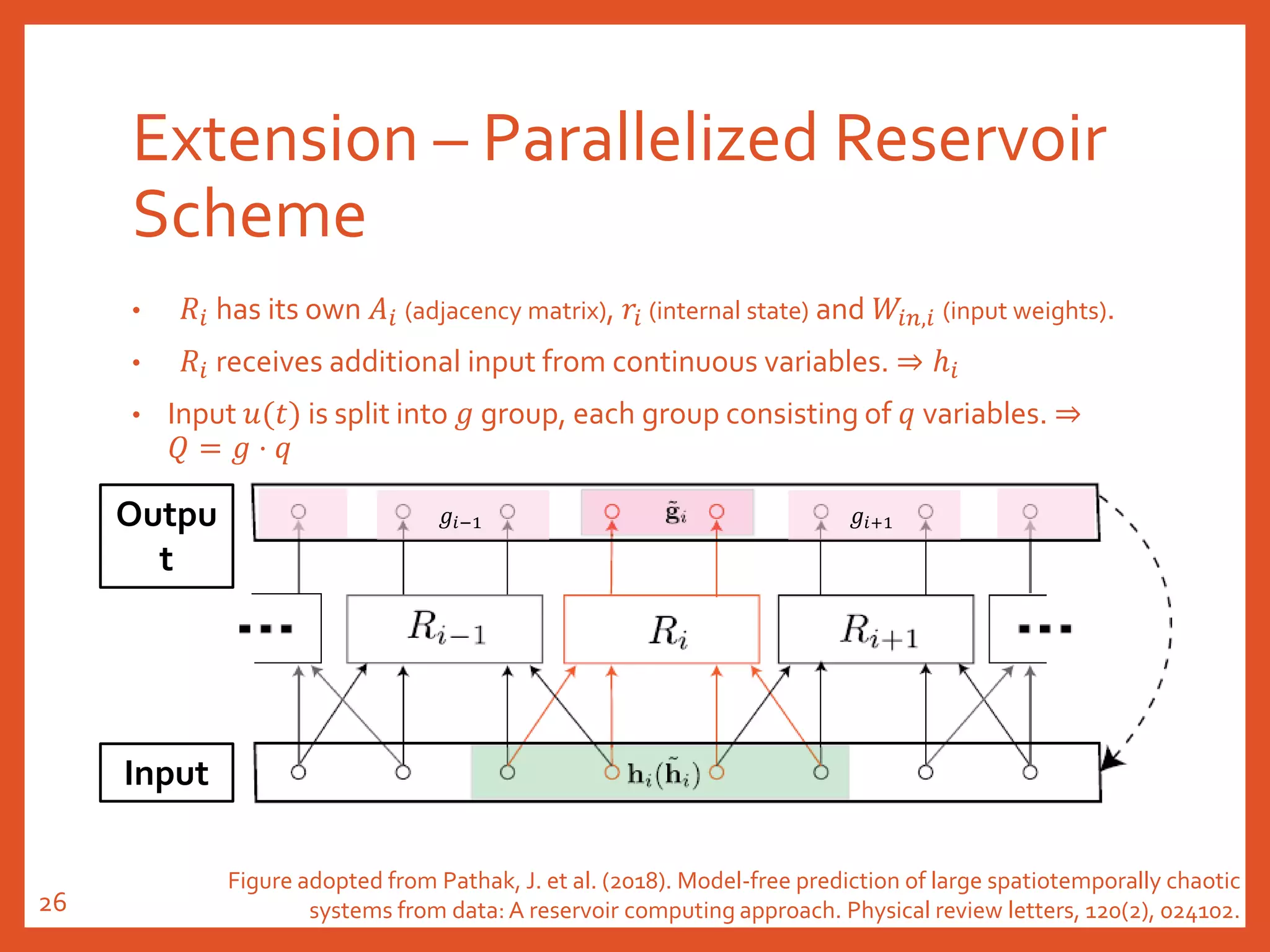
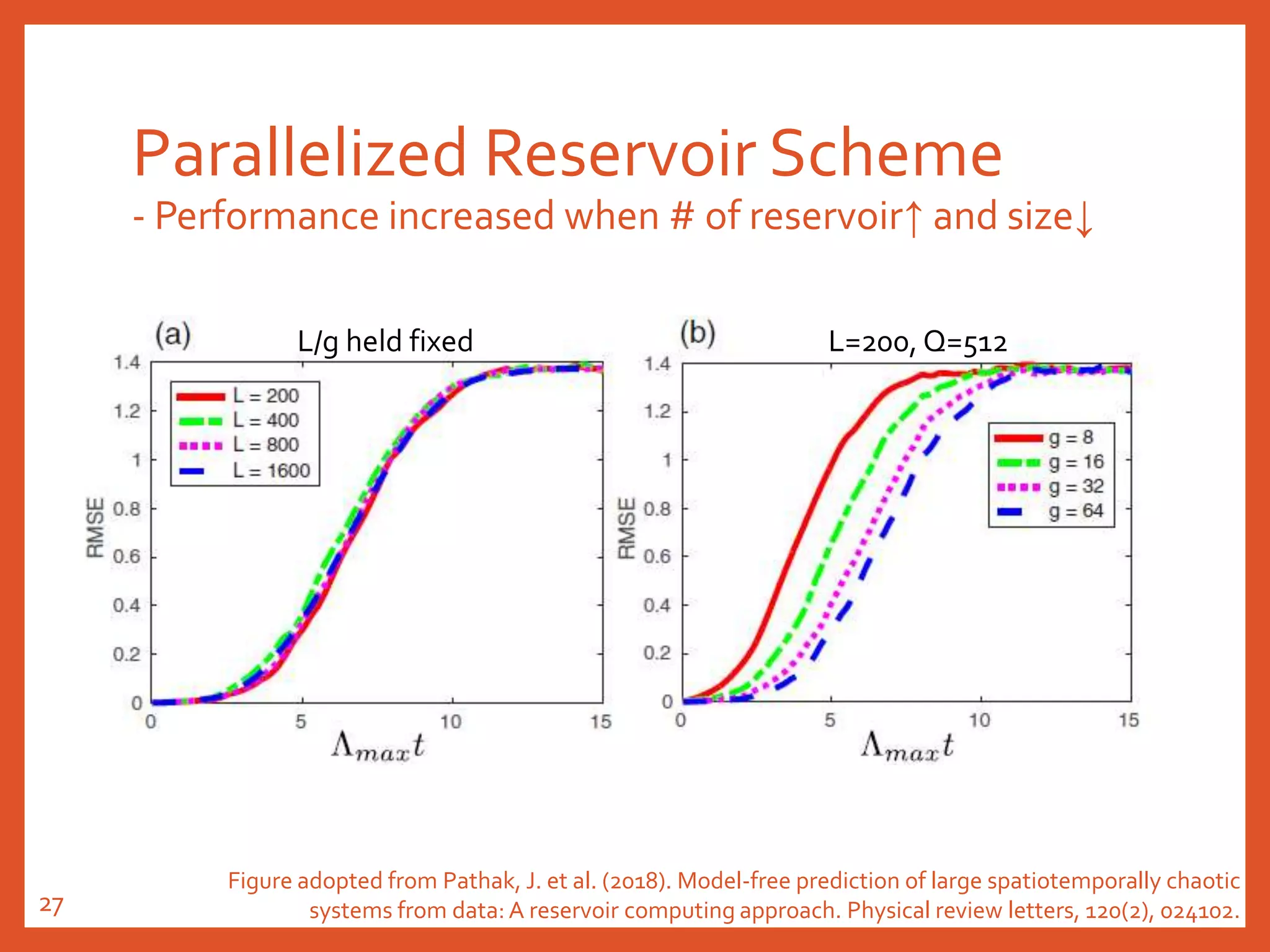
Figure adopted from Pathak, J. et al. (2018). Model-free prediction of large spatiotemporally chaotic
systems from data: A reservoir computing approach. Physical review letters, 120(2), 024102.21](https://image.slidesharecdn.com/20191018reservoircomputing-191019030640/75/20191018-reservoir-computing-21-2048.jpg)
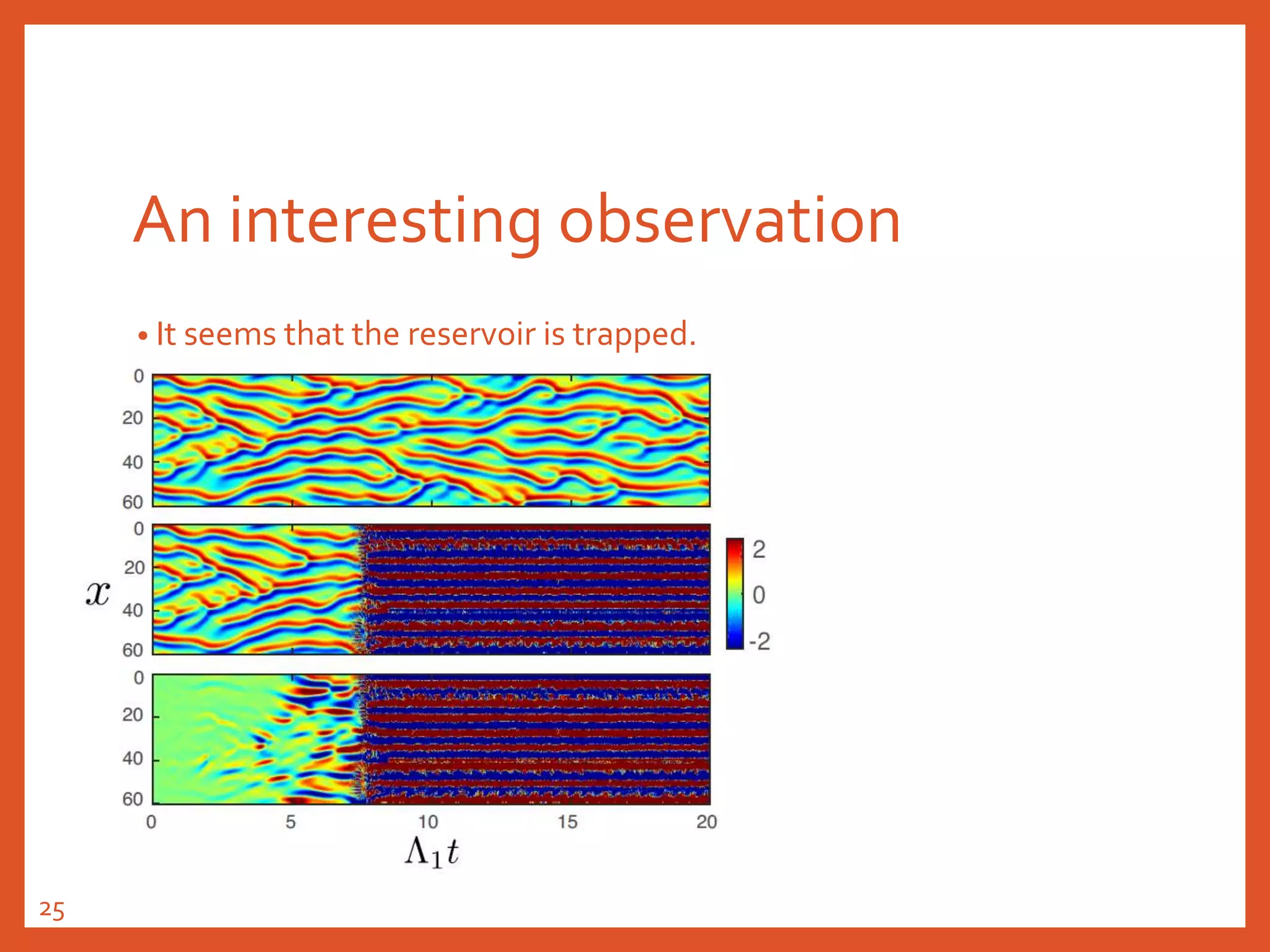


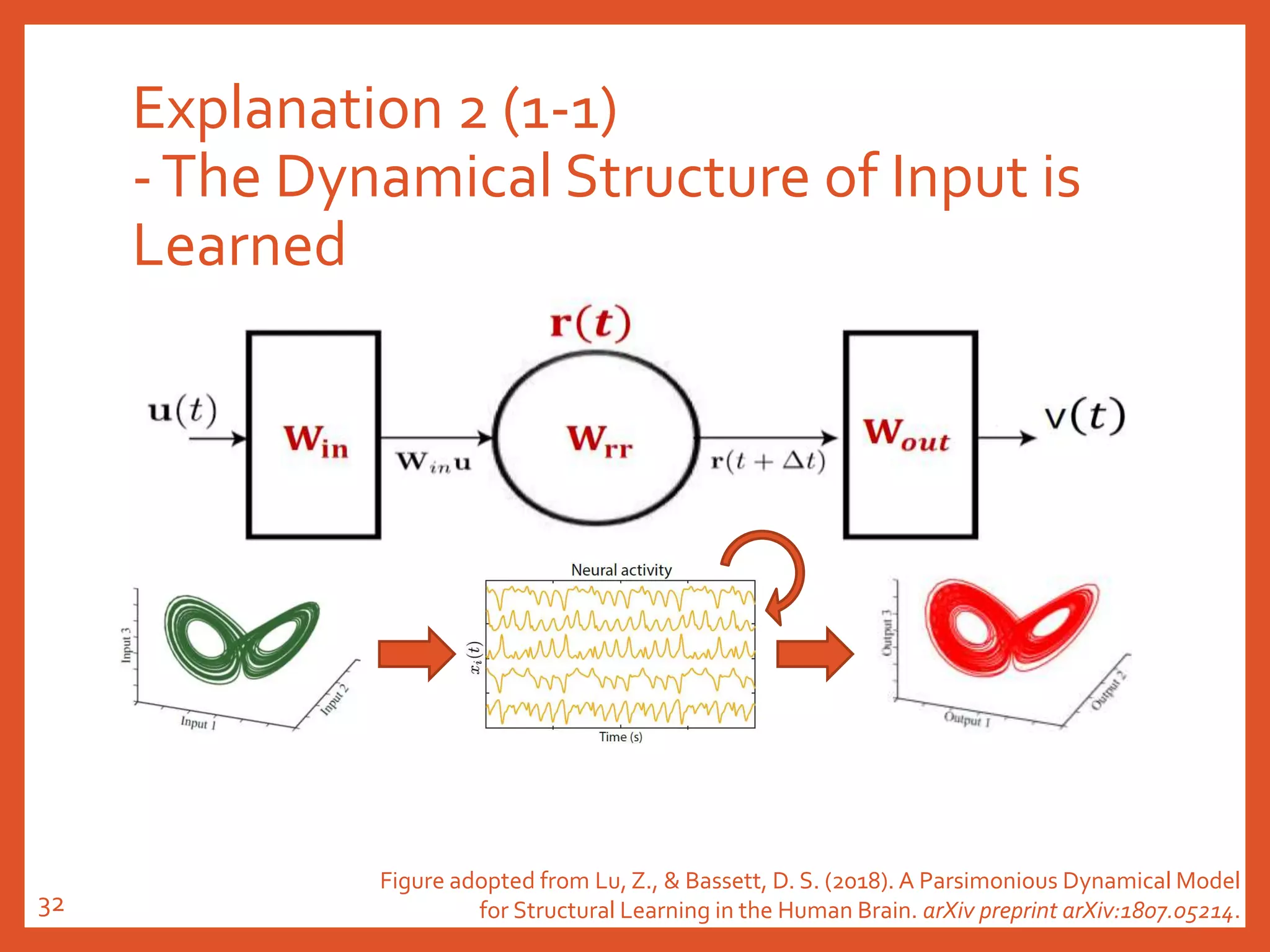
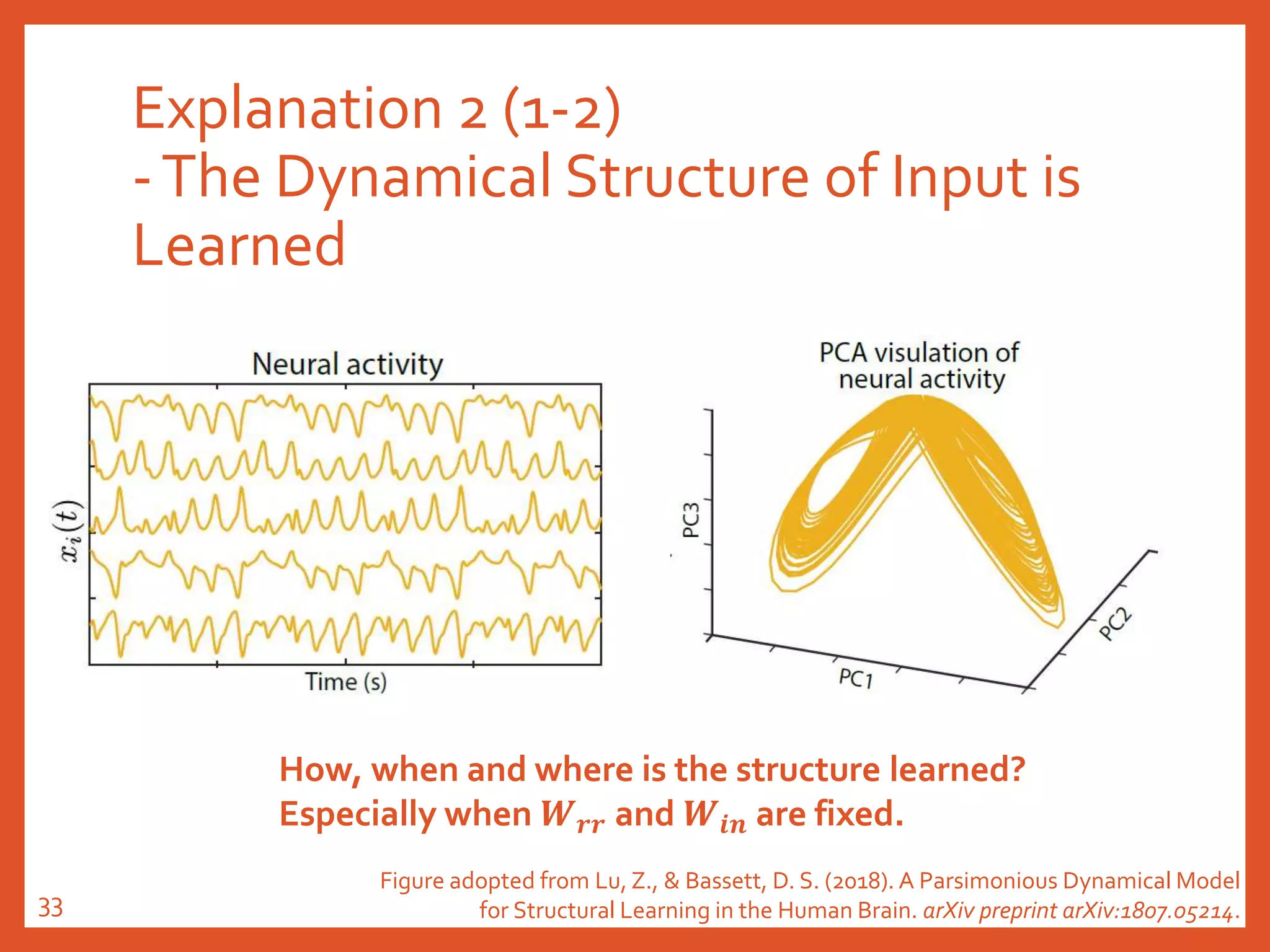
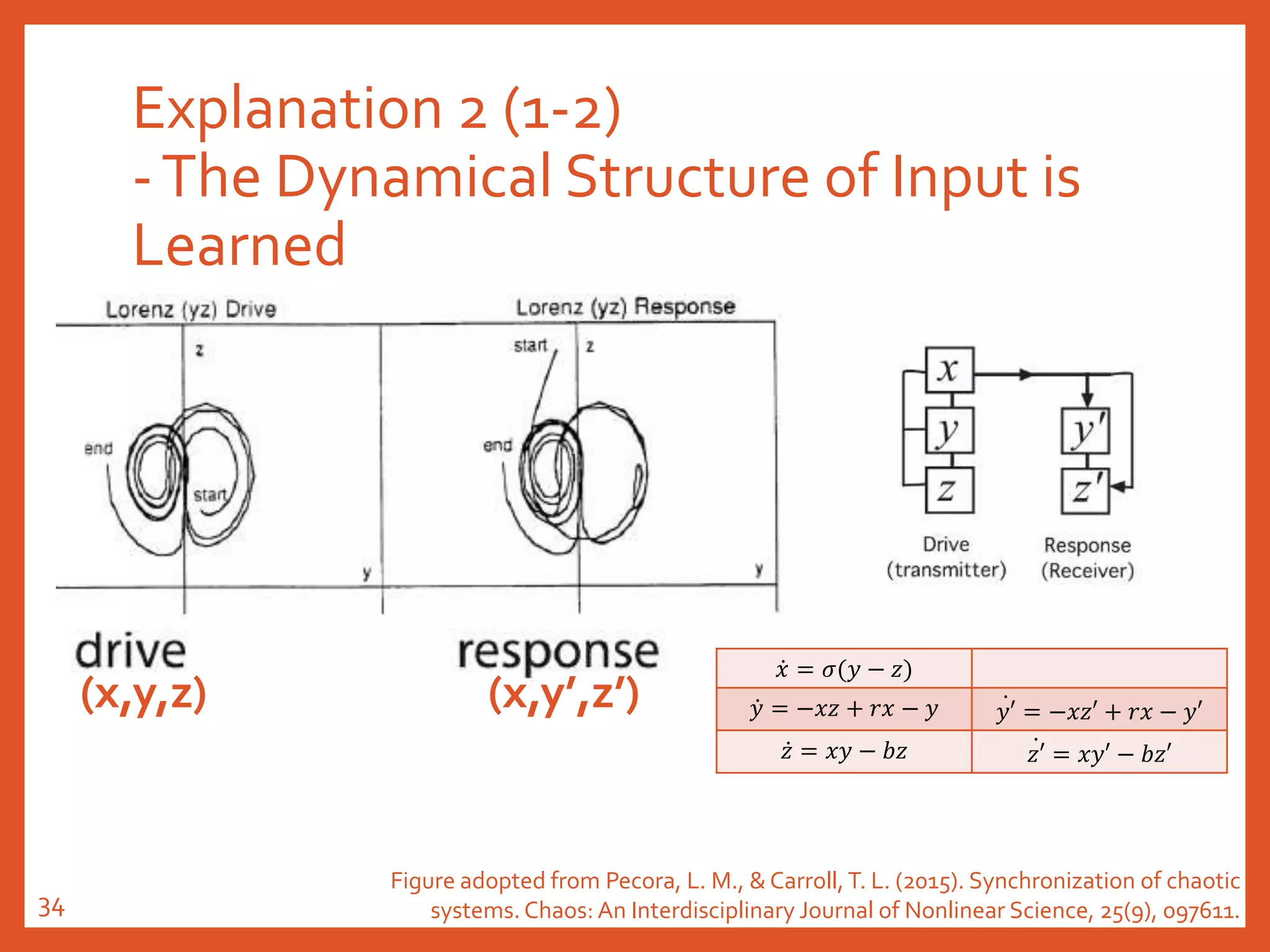
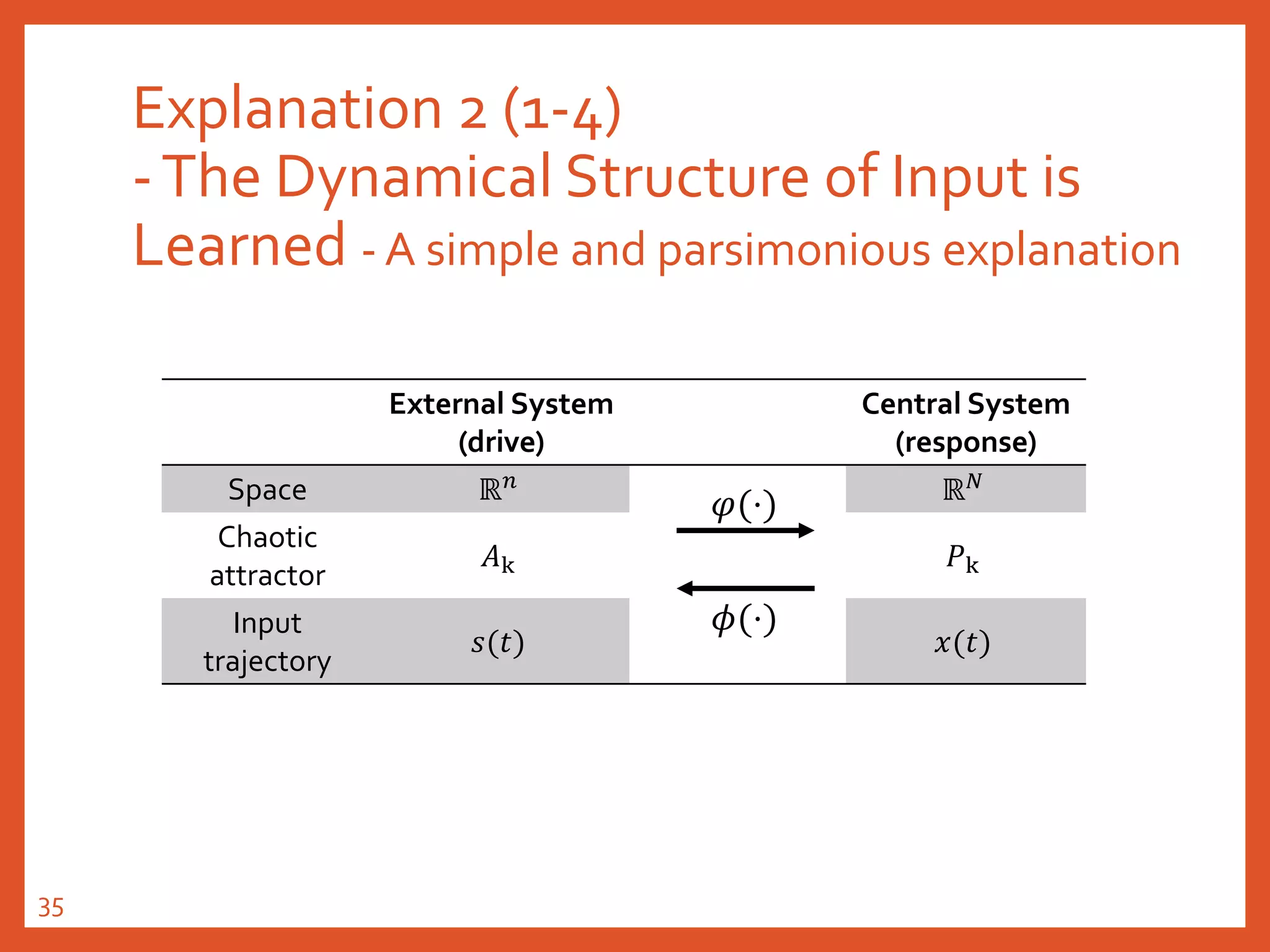

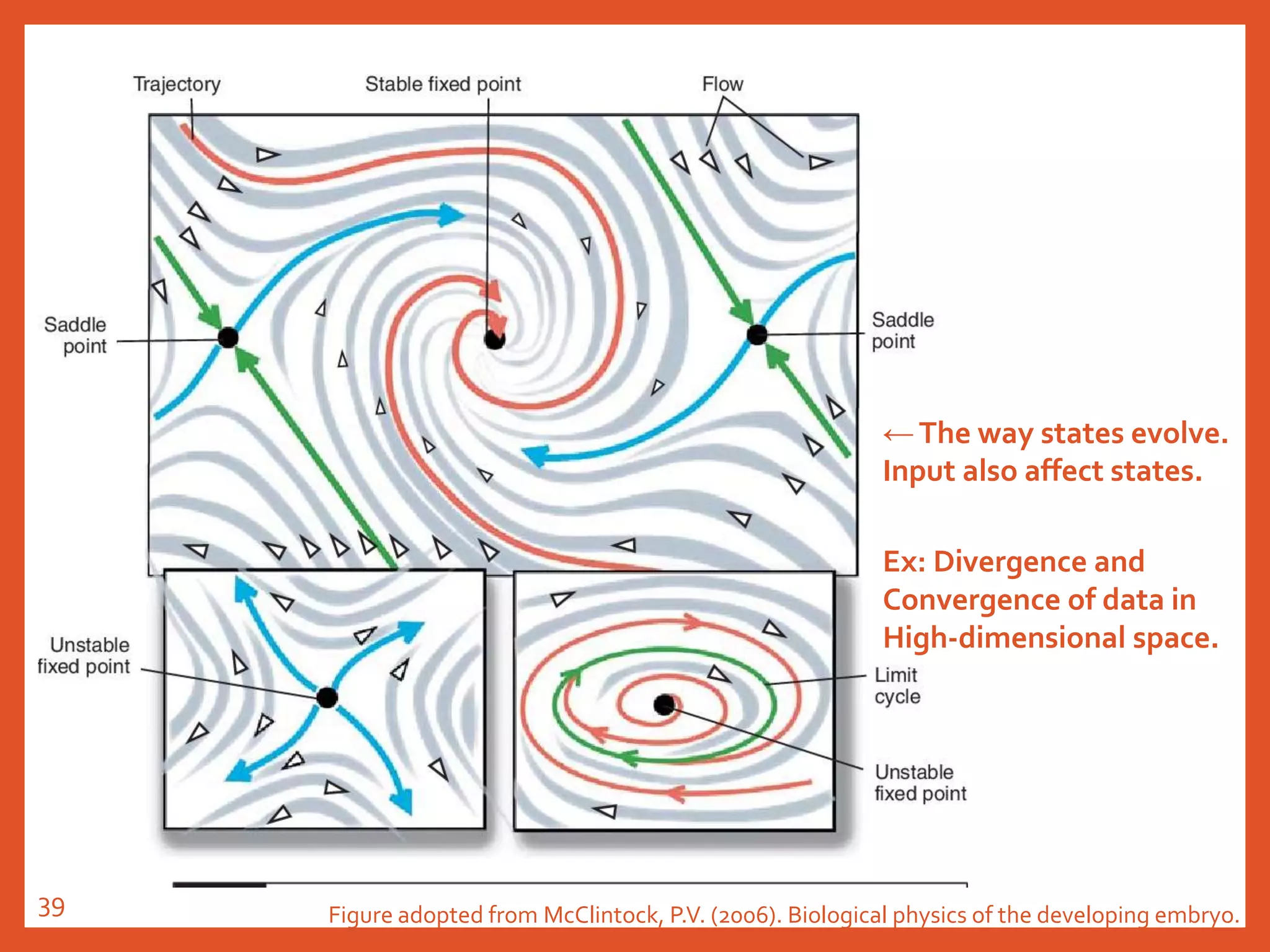
![Explanation 2 (2-2)
-The Dynamical Structure of Input is
Learned
• 在各类复杂的动力学形式里, 我们看到,无论是稳定定点, 极限环,
鞍点,还是线性吸引子,事实上都是对世界普遍存在的信息流动形式
的通用表达。
• 可以用它表达信息的提取和加工, 甚至某种程度的逻辑推理(决策),
那么只要我们能够掌握一种学习形式有效的改变这个随机网络的连接,
我们就有可能得到我们所需要的任何一种信息加工过程。
• 用几何语言说就是,在随机网络的周围, 存在着从毫无意义的运动到
通用智能的几乎所有可能性, 打开这些可能的过程如同[外在环境]对
随机网络进行一个微扰, 而这个微扰通常代表了某种网络和外在环境
的耦合过程(学习), 当网络的动力学在低维映射里包含了真实世界
的动力学本身, 通常学习就成功了。
作者:许铁-巡洋舰科技
網址:https://www.zhihu.com/question/265476523/answer/74765341538](https://image.slidesharecdn.com/20191018reservoircomputing-191019030640/75/20191018-reservoir-computing-35-2048.jpg)