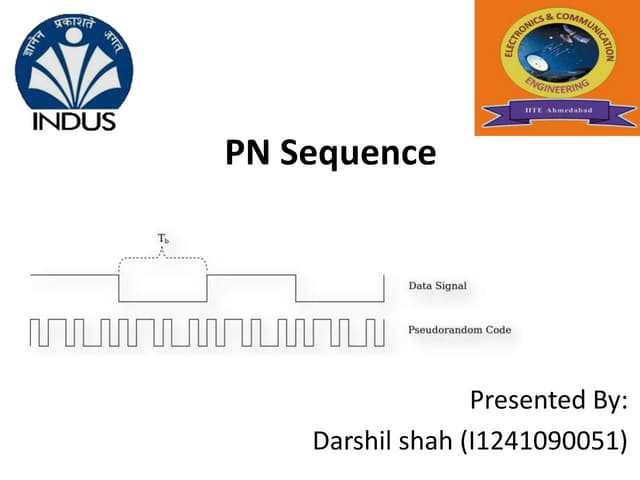
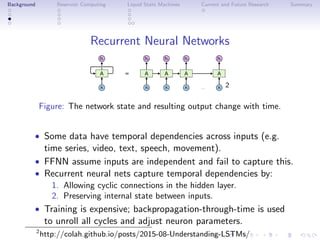
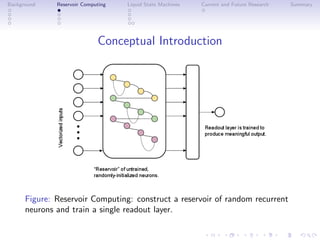
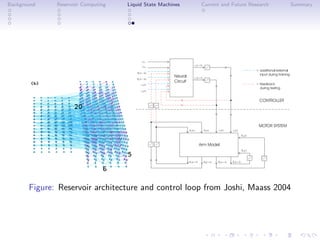
This document discusses reservoir computing with a focus on liquid state machines, highlighting their advantages over traditional artificial neural networks and recurrent neural networks for solving temporal problems. It outlines key concepts, historical developments, and successful applications in various fields while emphasizing the need for further research in hardware implementations and reservoir optimization. Liquid state machines require specific properties for universal computation, making them particularly effective for temporal data tasks.


























![RF Module Design - [Chapter 3] Linearity](https://cdn.slidesharecdn.com/ss_thumbnails/rfch3-150613070345-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![RF Module Design - [Chapter 5] Low Noise Amplifier](https://cdn.slidesharecdn.com/ss_thumbnails/rfch5-150613070346-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)