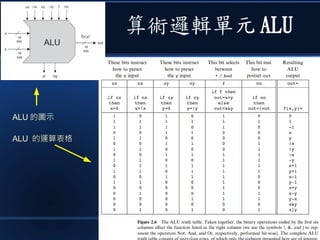
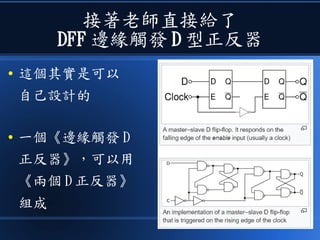
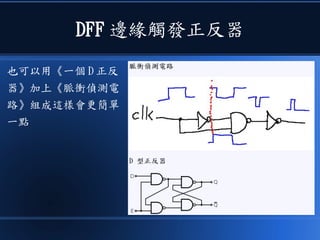
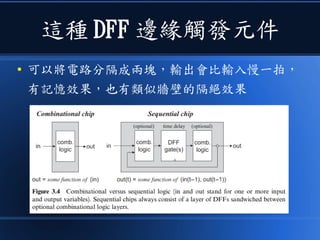
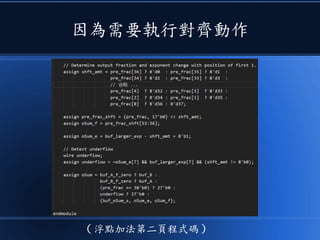
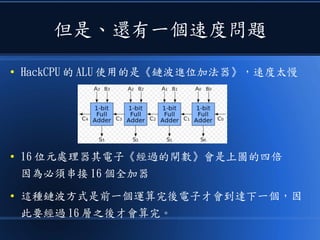
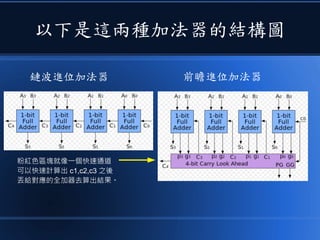
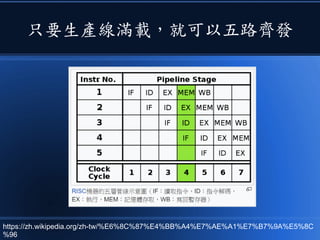
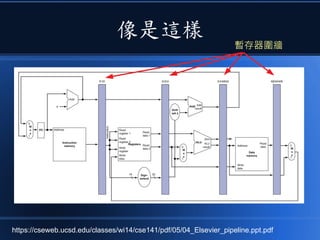
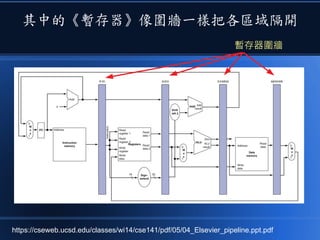
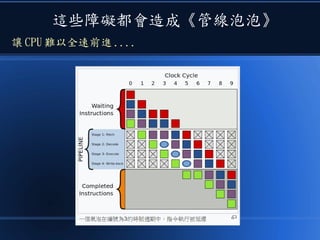
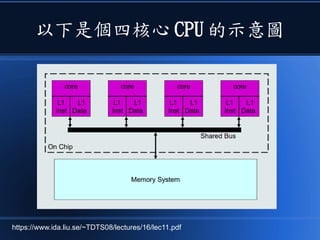
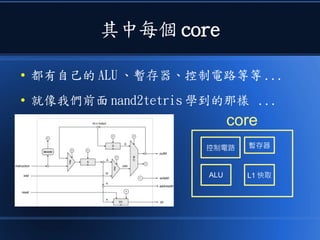
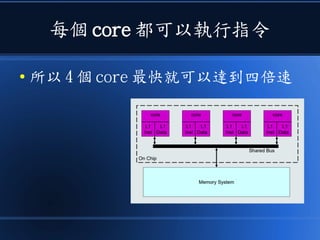
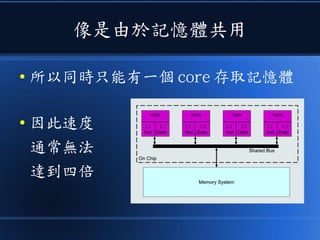
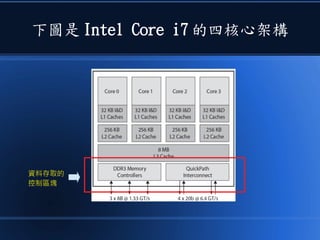
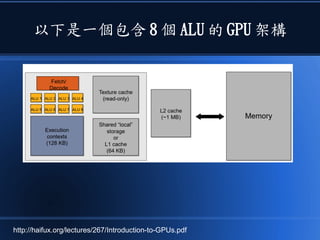
本文讨论了计算机设计与加速的方法,强调了电路基础与逻辑门的组合。介绍了 nand2tetris 课程的内容,涵盖了从硬件设计到 CPU 构建的全过程。此外,文章还涉及了速度提升的策略,如多层次缓存与流水线技术,以解决现代计算机面临的性能瓶颈。




















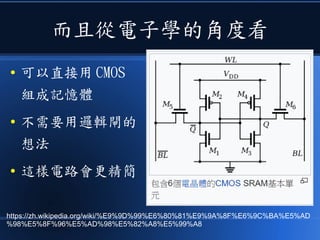




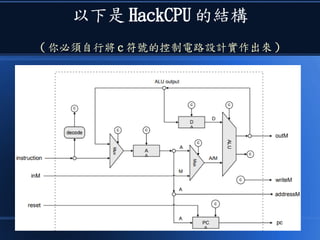


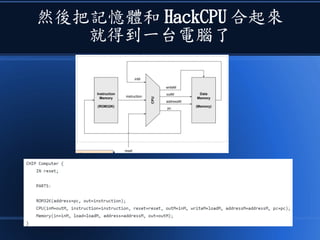







































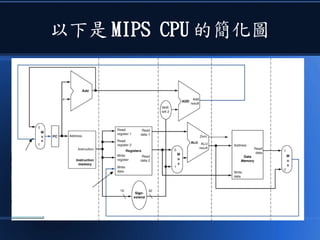
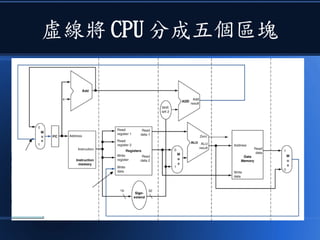
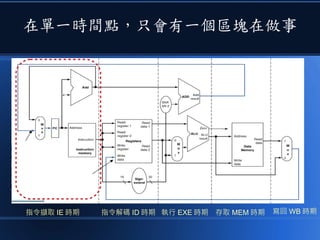



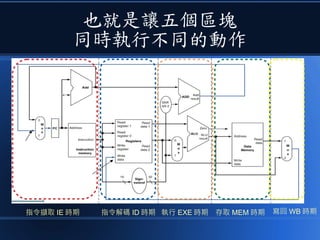























































































![[科科營]電腦概述](https://cdn.slidesharecdn.com/ss_thumbnails/coursecomputer-130707071458-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


























