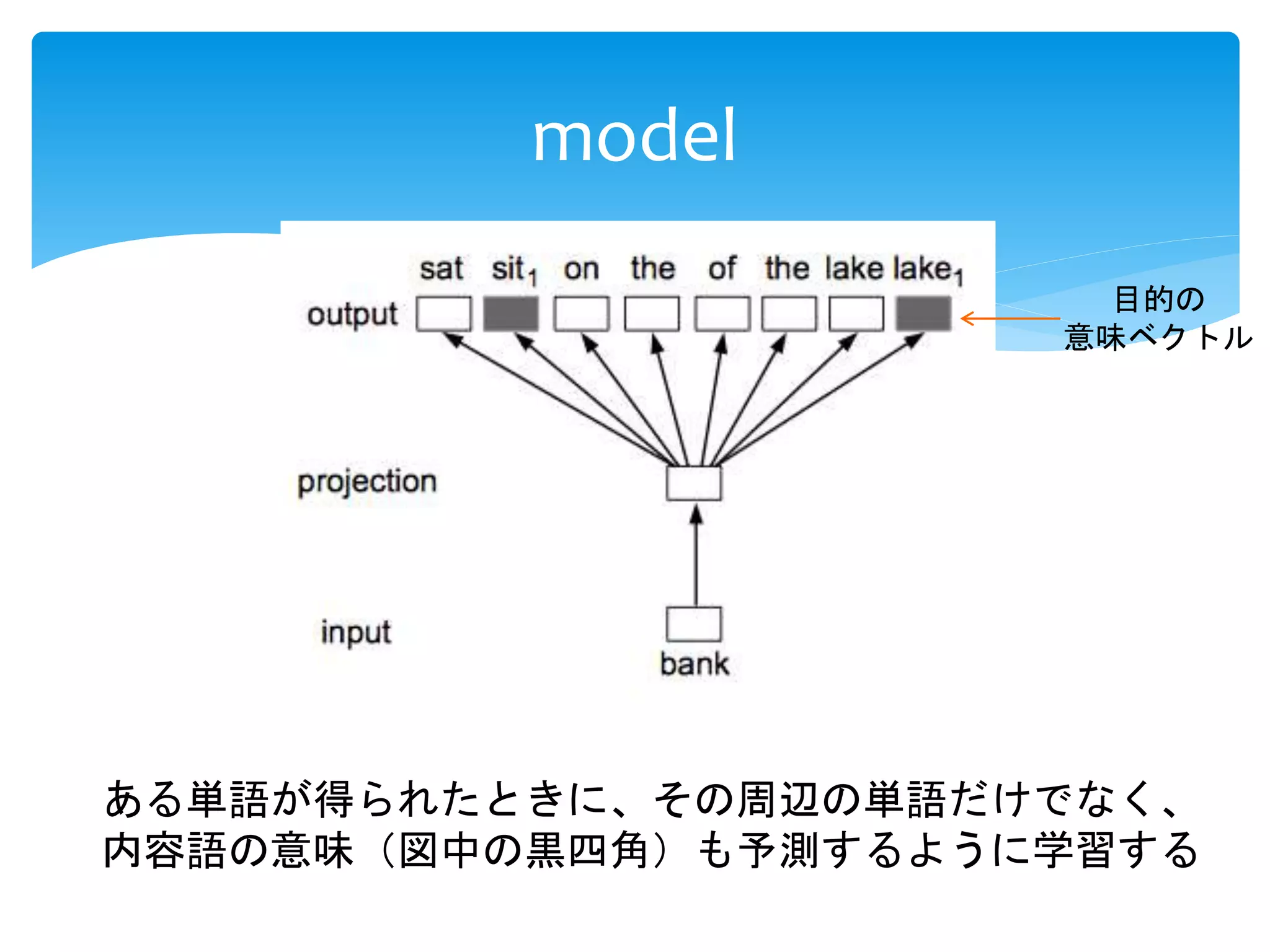
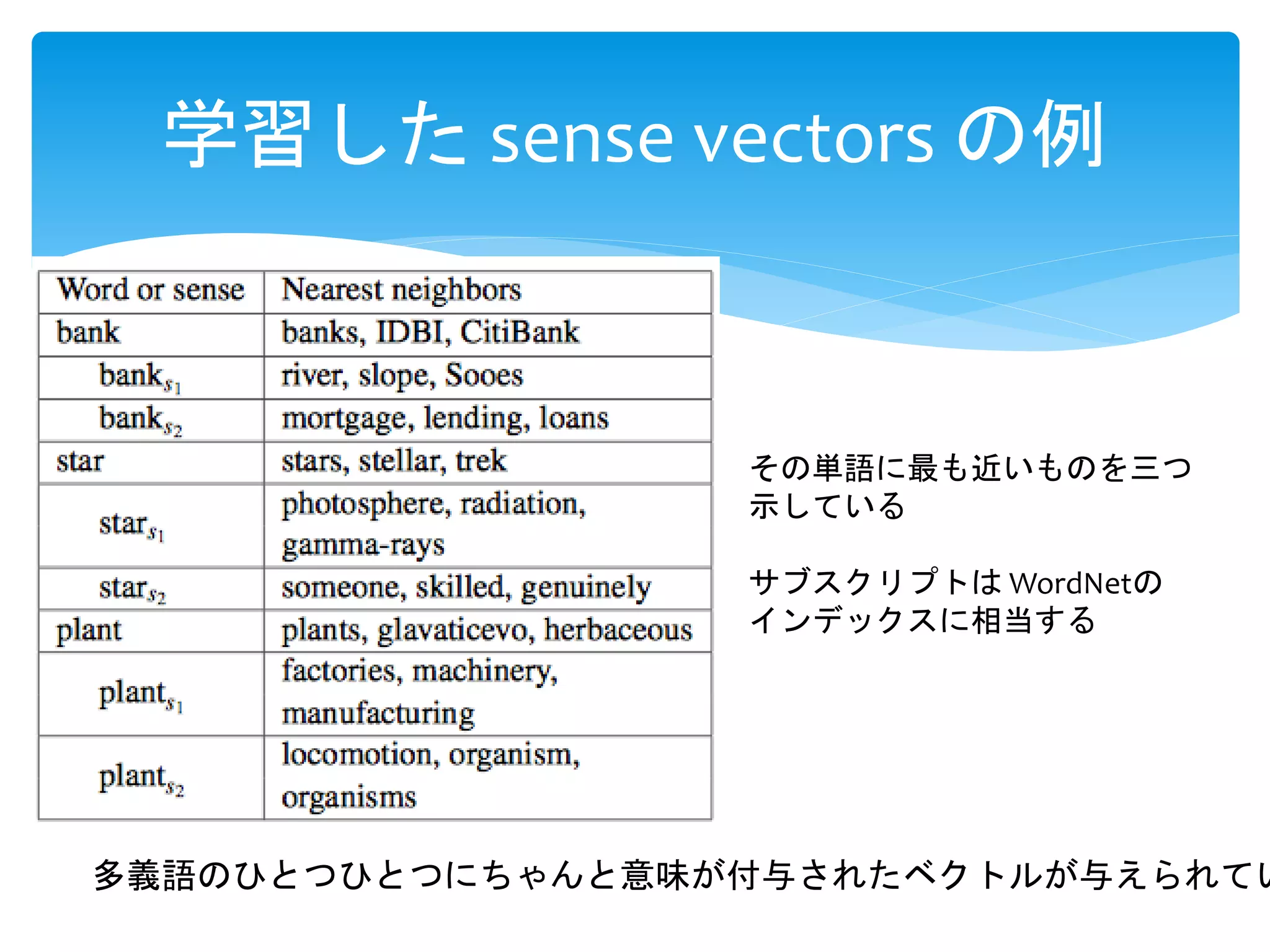
多義語の各意味をベクトル化
WordNet を使用
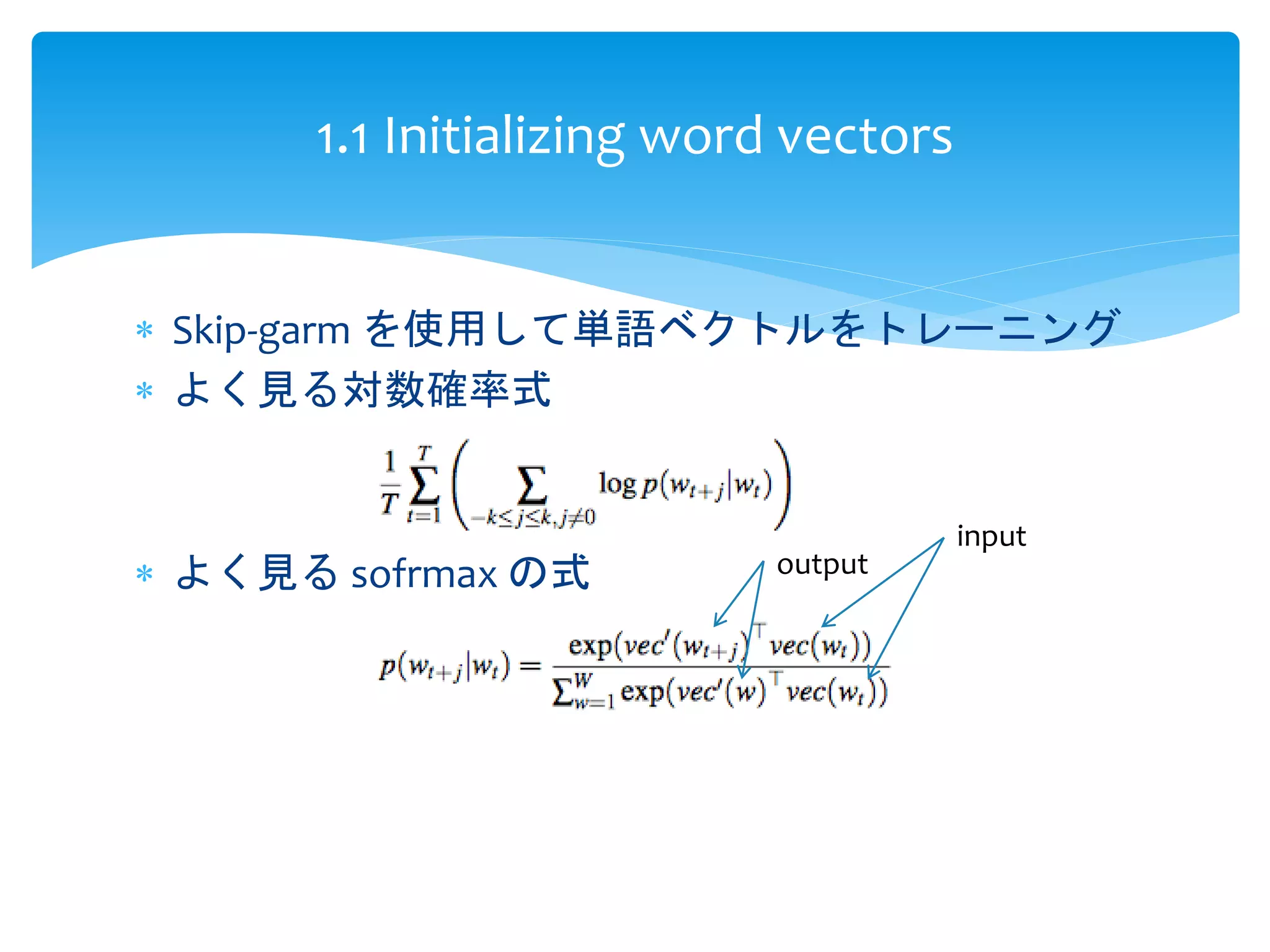
これからの説明で出てくる変数
R : ラベルなしテキスト
W: テキストの語彙
wsi:W中の単語wのWordnet のi 番目の意味
gloss(wsi): wsi の語釈文
vec(w): 単語w のベクトル
vec(wsi): I 番目の意味wsi のベクトル
6.
モデル生成の3ステップ
1.Initializing word vectors and sense vectors
2. Performing word sense disambiguation
3. Learning sense vectors from relevant occurrences
1.2 Initializing sensevectors
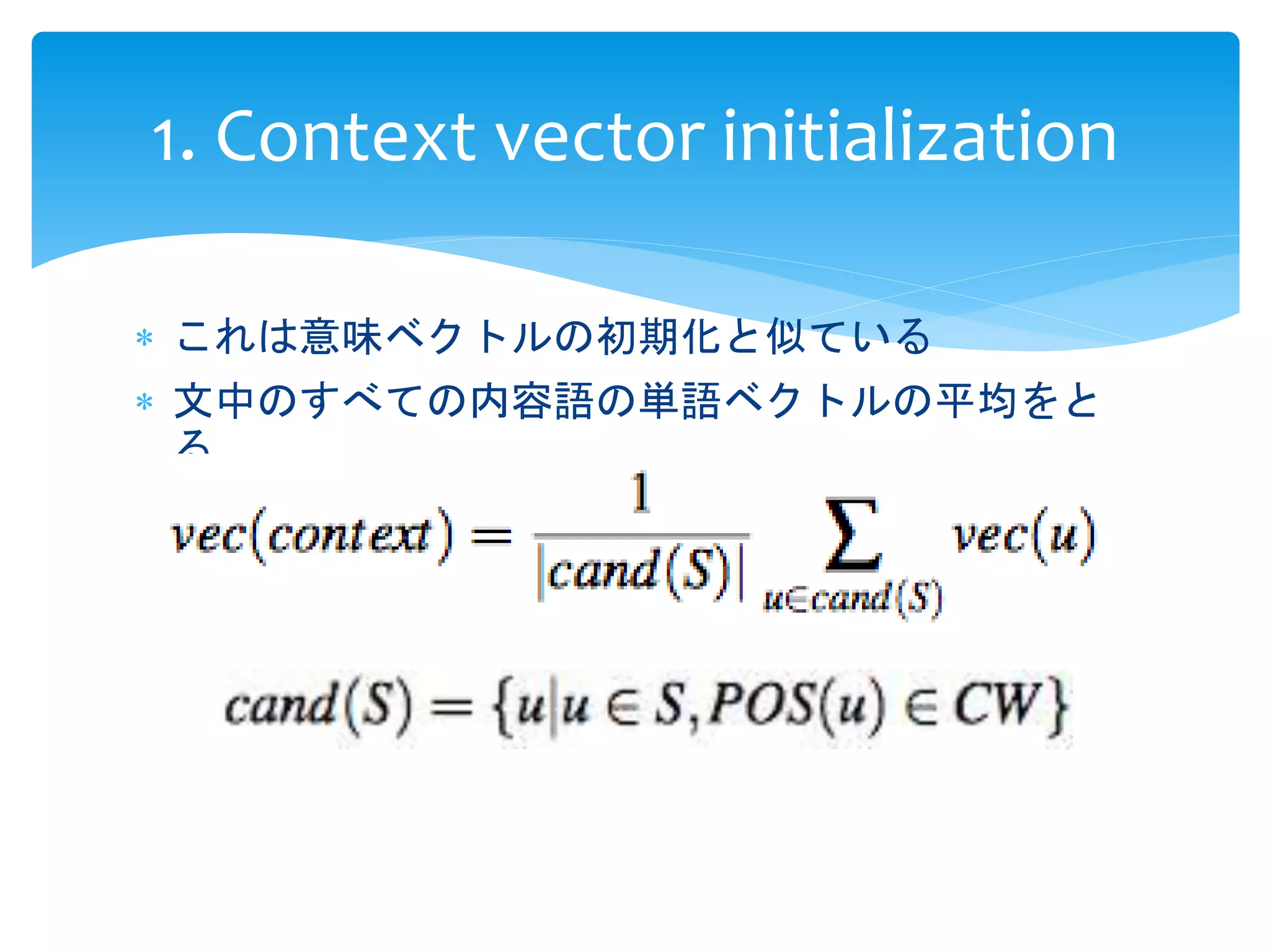
語釈文中の類似単語を使用して意味を表すことで
初期化する
banks1 の語釈文:
“sloping land (especially the slope beside a body of water))
they pulled the canoe up on the bank; he sat on the bank of
the river and watched the currents”
類似単語候補: (単語, cos類似度)
(sloping, 0.12), (land, 0.21), (slope, 0.17), (body, 0.01),
(water, 0.10), (pulled, 0.01), (canoe, 0.09), (sat, 0.06), (river,
0.43), (watch, -0.11), (currents, 0.01)
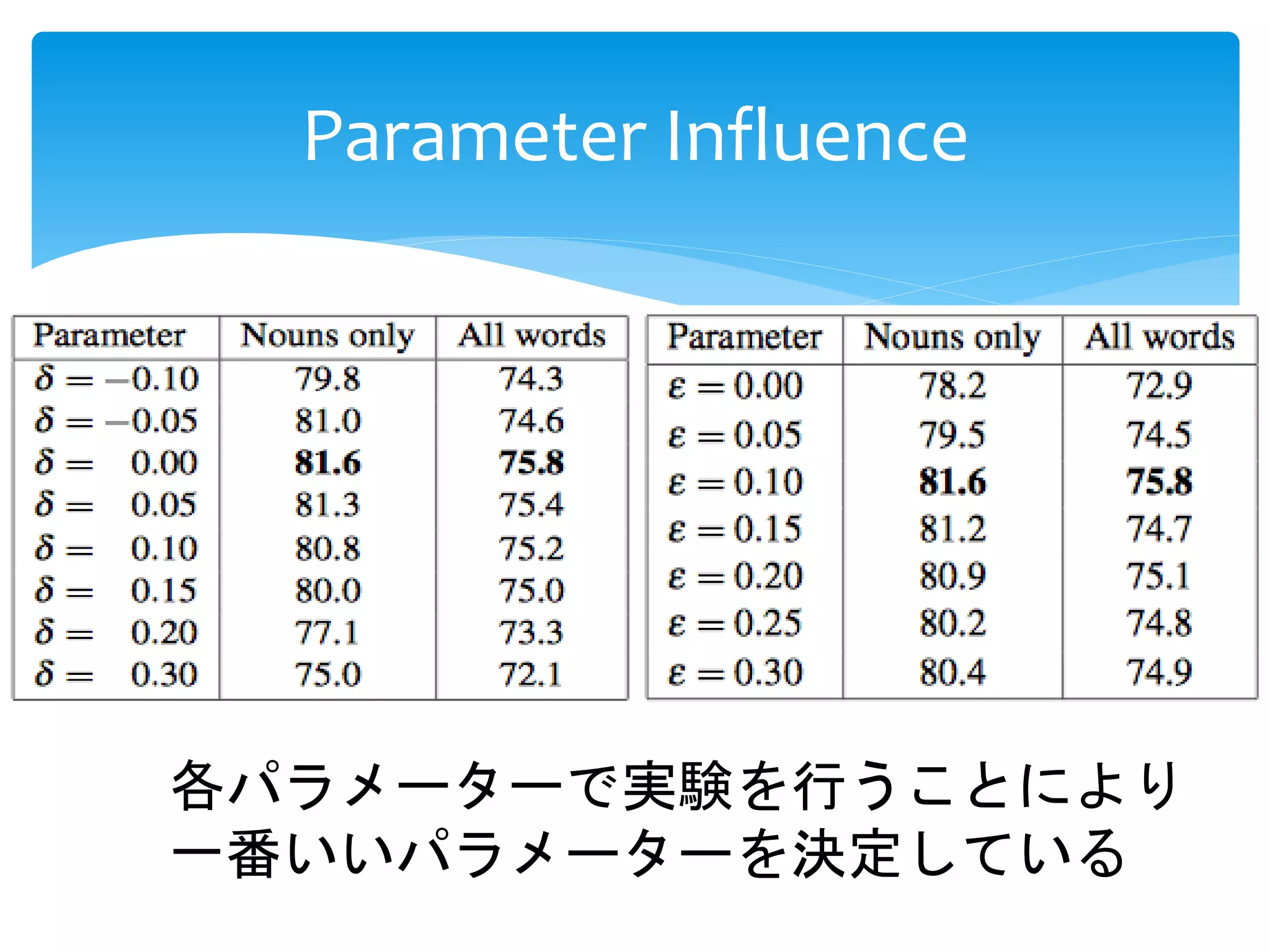
フィルタリング: 閾値δ = 0.05
cand(wsi) = {sloping, land, slope, water, canoe, sat, river}
cand(wsi) の単語ベクトルの平均が…意味ベクトル!!
vec(banksi)