












![{ $match : { state : "NY" } }
{
city: “SAN FRANCISCO",
loc: [-122.4614, 37.781],
state: ”CA"
}
{
city: "NEW YORK",
loc: [ -73.989, 40.731],
state: "NY"
}
{
city: “PALO ALTO",
loc: [ -122.127, 37.418],
state: ”CA"
}](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-16-320.jpg)
![{ $match : { loc : { $geoWithin:
{$centerSphere : [ [ -122.4, 37.79 ], 20/3959 ] }
{
city: “SAN FRANCISCO",
loc: [-122.4614, 37.781],
state: ”CA"
}
{
city: "NEW YORK",
loc: [ -73.989, 40.731],
state: "NY"
}
{
city: “PALO ALTO",
loc: [ -122.127, 37.418],
state: ”CA"
}](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-17-320.jpg)

![{
loc: [-122.3892, 37.7864],
state: ”CA"
}
{
_id: "94105",
city: “SAN FRANCISCO",
loc: [-122.3892, 37.7864],
state: ”CA"
}
Selecting and Excluding
Fields
$project: { _id: 0, loc: 1, state: 1 }](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-19-320.jpg)
![{
zip: "94105",
cityState: ”SAN FRANCISCO,
CA"
}
{
_id: "94105",
city: “SAN FRANCISCO",
loc: [-122.3892, 37.7864],
state: ”CA"
}
$project:{zip:"$_id",cityState: {$concat:["$city", ", ", "$state" ]},_id:0}
Renaming and Computing
Fields](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-20-320.jpg)
![{
zip: "94105",
cityState: ”SAN FRANCISCO,
CA"
}
{
_id: "94105",
city: “SAN FRANCISCO",
loc: [-122.3892, 37.7864],
state: ”CA"
}
$project:{zip:"$_id",cityState: {$concat:["$city", ", ", "$state" ]},_id:0}
Renaming and Computing
Fields
New Field Operation](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-21-320.jpg)
![{
dt : {
y : 2012,
m : 9,
d : 1
},
totalprice: 123350.97,
status: "F"
}
{
_id : 6694,
cname : "Cust#000060209",
status" : "F",
totalprice : 123350.97,
orderdate : ISODate("2012-09-
01T13:11:31Z"),
lineitems: [
{ ... },
{ ... },
{ ... }
]
}
Renaming and Computing
Fields
$project : { dt: { y : { "$year" : "$orderdate" },
m : { "$month" : "$orderdate" },
d : { "$dayOfMonth" : "$orderdate" } },
totalprice : 1, status : 1, _id : 0 }](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-22-320.jpg)

![Find the smallest cities
within twenty miles of San
Francisco{ _id: "94306",
city: “PALO ALTO",
loc: [ -122.127, 37.418],
pop: 24309 }
{ _id: "10280",
city: "NEW YORK",
loc: [ -74.016, 40.710],
pop: 5574 }
{ _id: "94124",
city: “SAN FRANCISCO",
loc: [-122.388, 37.73],
pop: 27239 }](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-24-320.jpg)
![{
_id: "WOODACRE",
pop: 1524
}
{
_id: "STINSON BEACH",
pop: 630
}
{ _id: "94306",
city: “PALO ALTO",
loc: [ -122.127, 37.418],
pop: 24309 }
{ _id: "10280",
city: "NEW YORK",
loc: [ -74.016, 40.710],
pop: 5574 }
{ _id: "94124",
city: “SAN FRANCISCO",
loc: [-122.388, 37.73],
pop: 27239 }
{
_id: "BOLINAS",
pop: 1555
}
{ $match : { loc :
{ $geoWithin:
{ $centerSphere : [
[ -122.4, 37.79 ],
20/3959
]
} } }
{ $group : {
_id : "$city",
pop : {$sum:
"$pop"}
}
}
{ $sort : { "pop" : 1 } },
{ $limit : 3 }
Find the smallest cities
within twenty miles of San
Francisco](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-25-320.jpg)

![$unwind
{
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "Long Island"
}
{ $unwind: "$subjects" }
{
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "New York"
}
{
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "1920s"
}
{
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: [
"Long Island",
"New York",
"1920s"
]
}](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-27-320.jpg)








![{
_id: 375,
title: "The Great Gatsby",
ISBN: "9781857150193",
available: true,
pages: 218,
chapters: 9,
subjects: [
"Long Island",
"New York",
"1920s"
],
language: "English"
}
Our Example Data](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-37-320.jpg)




![MapReduce
db.books.mapReduce(
map, reduce, {finalize: finalize, out: { inline : 1} } )
"results" : [
{
"_id" : "English",
"value" : 653
},
{
"_id" : "Russian",
"value" : 1440
}
]](https://image.slidesharecdn.com/2014bigdatacampasyakamsky-140623120830-phpapp02/85/2014-bigdatacamp-asya_kamsky-42-320.jpg)





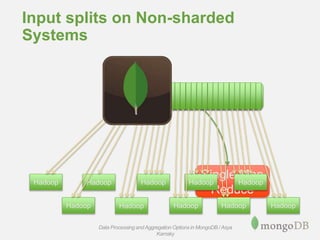


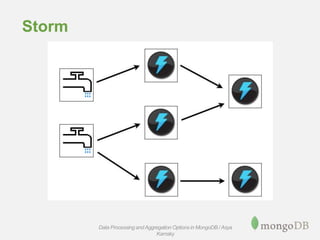







The document discusses various options for processing and aggregating data in MongoDB, including the Aggregation Framework, MapReduce, and connecting MongoDB to external systems like Hadoop. The Aggregation Framework is described as a flexible way to query and transform data in MongoDB using a JSON-like syntax and pipeline stages. MapReduce is presented as more versatile but also more complex to implement. Connecting to external systems like Hadoop allows processing large amounts of data across clusters.











































































































