



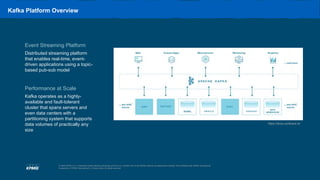
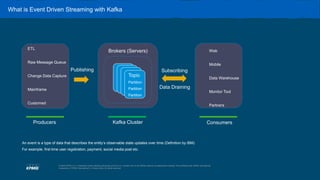

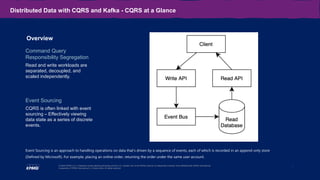
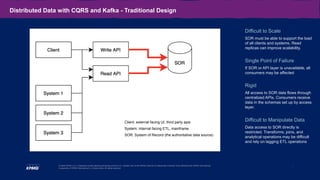
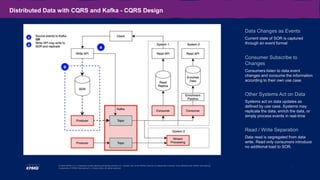













The document outlines the capabilities and use cases of Kafka, an event streaming platform designed for real-time applications, emphasizing its scalability and high availability features. It discusses the integration of Kafka with Command Query Responsibility Segregation (CQRS) for managing distributed data, showcasing its advantages and related challenges. Additionally, it highlights the significance of Kafka in banking for modernizing legacy systems, alongside key takeaways for implementing Kafka effectively in various scenarios.