Downloaded 63 times

![document-oriented database with
dynamic schema
stores data in JSON-like documents:
{
_id : “kosmo kramer”,
age : 42,
location : {
state : ”NY”,
zip : ”10024”
},
favorite_colors : [“red”, “green”]
}
different structure in each document
values can be simple like strings and ints or nested documents](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-3-2048.jpg)



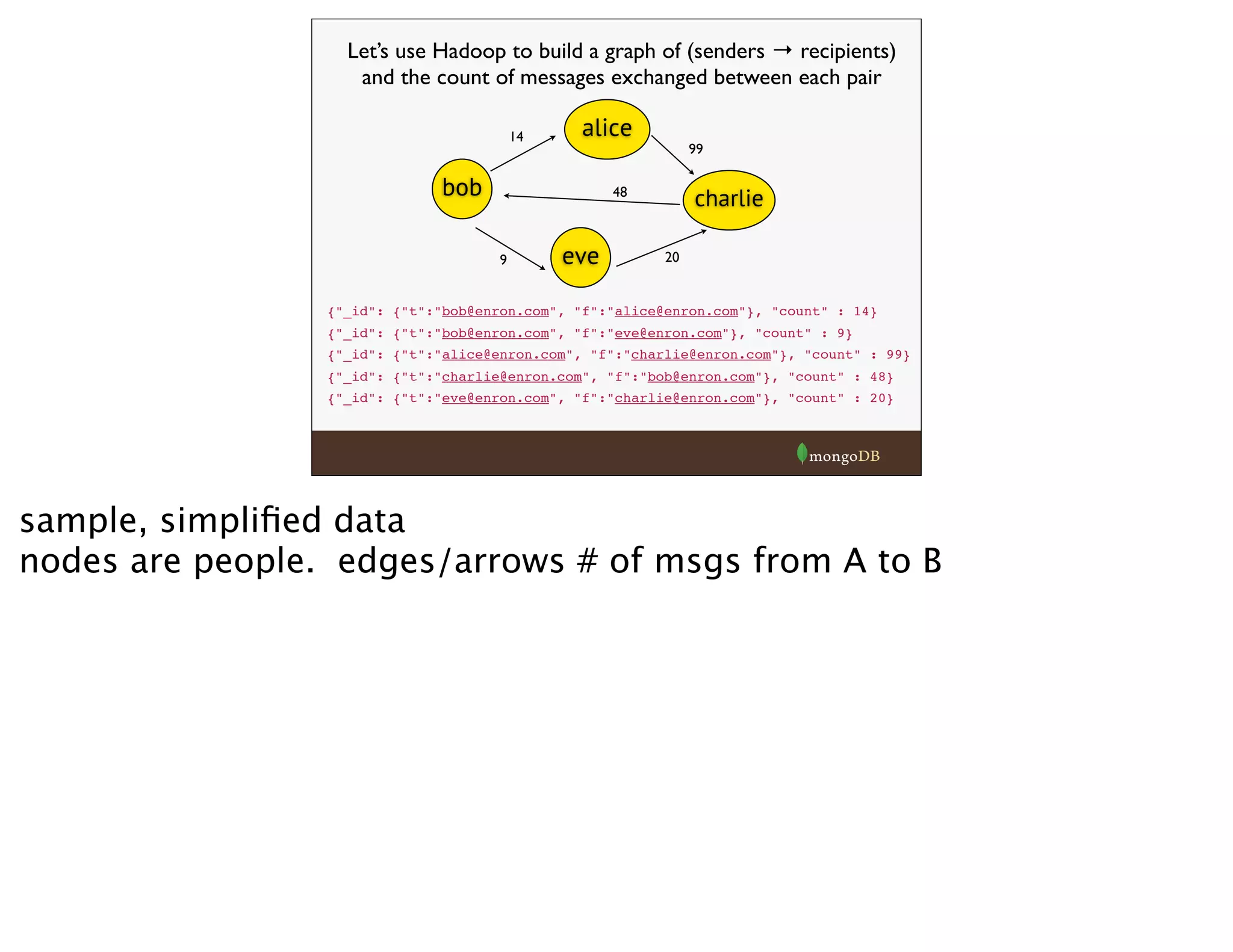
![Example 1 - Java MapReduce
mongodb document passed into
Hadoop MapReduce
Map phase - each input doc gets
passed through a Mapper function
@Override
public
void
map(NullWritable
key,
BSONObject
val,
final
Context
context){
BSONObject
headers
=
(BSONObject)val.get("headers");
if(headers.containsKey("From")
&&
headers.containsKey("To")){
String
from
=
(String)headers.get("From");
String
to
=
(String)headers.get("To");
String[]
recips
=
to.split(",");
for(int
i=0;i<recips.length;i++){
String
recip
=
recips[i].trim();
context.write(new
MailPair(from,
recip),
new
IntWritable(1));
}
}
}
input value doc from mongo. connector will handle translation into
BSONObject for you](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-15-2048.jpg)

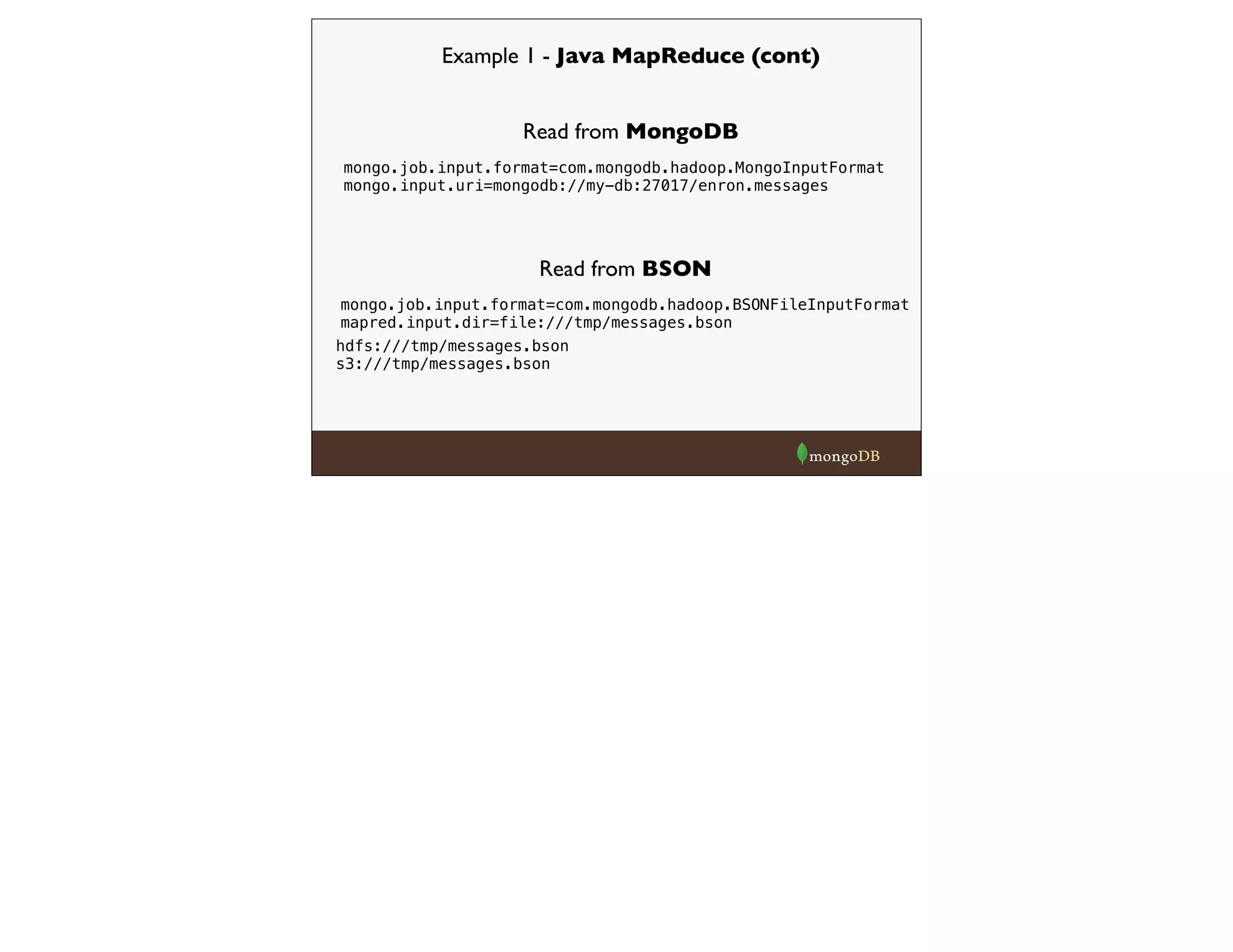
![Example 2 - Hadoop Streaming (cont)
from pymongo_hadoop import BSONMapper
def mapper(documents):
i = 0
for doc in documents:
i = i + 1
from_field = doc['headers']['From']
to_field = doc['headers']['To']
recips = [x.strip() for x in to_field.split(',')]
for r in recips:
yield {'_id': {'f':from_field, 't':r}, 'count': 1}
BSONMapper(mapper)
print >> sys.stderr, "Done Mapping."
BSONMapper is pymongo layer that translates from hadoop streaming
back to hadoop](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-22-2048.jpg)
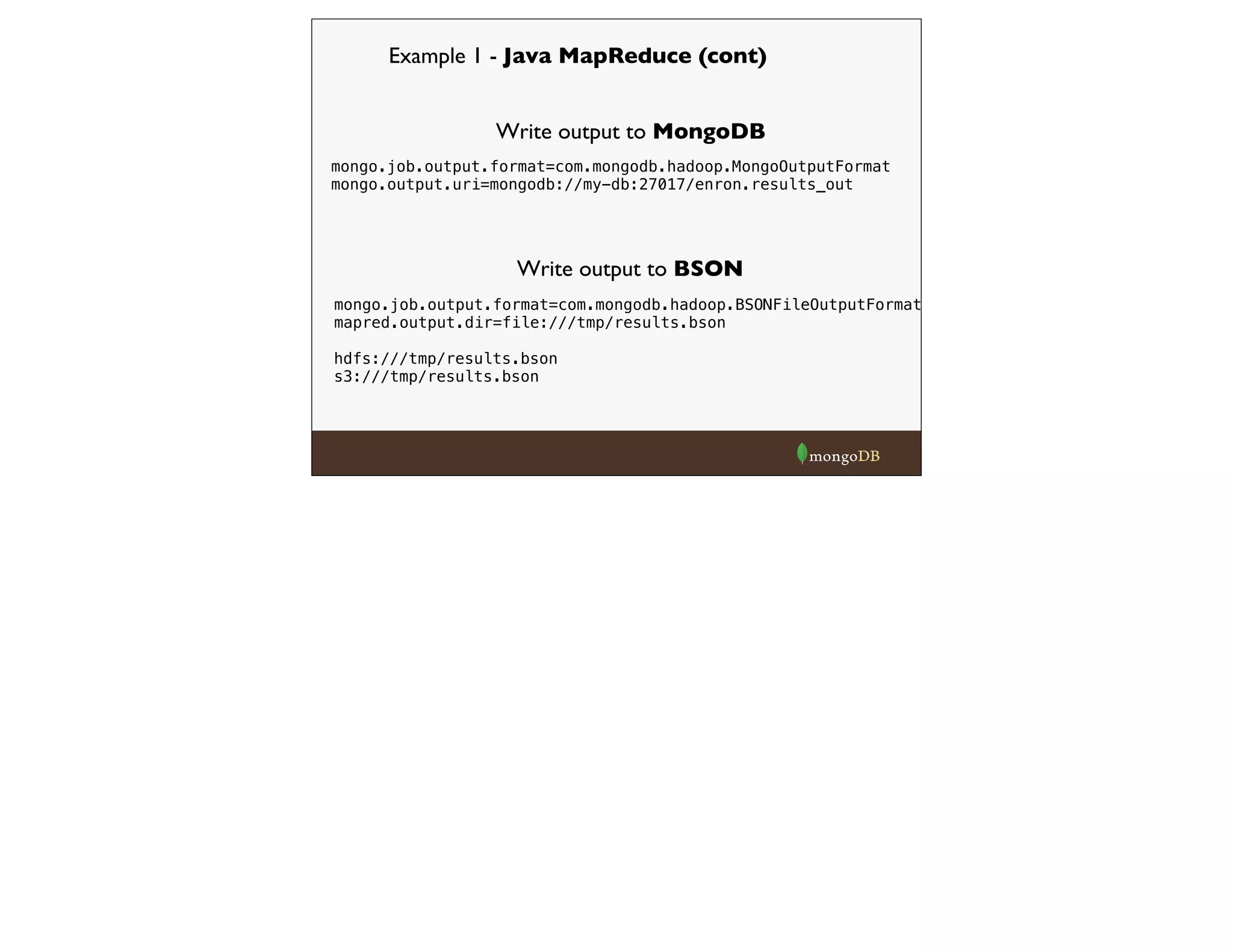
![Example 2 - Hadoop Streaming (cont)
from pymongo_hadoop import BSONReducer
def reducer(key, values):
print >> sys.stderr, "Processing from/to %s" % str(key)
_count = 0
for v in values:
_count += v['count']
return {'_id': key, 'count': _count}
BSONReducer(reducer)](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-23-2048.jpg)

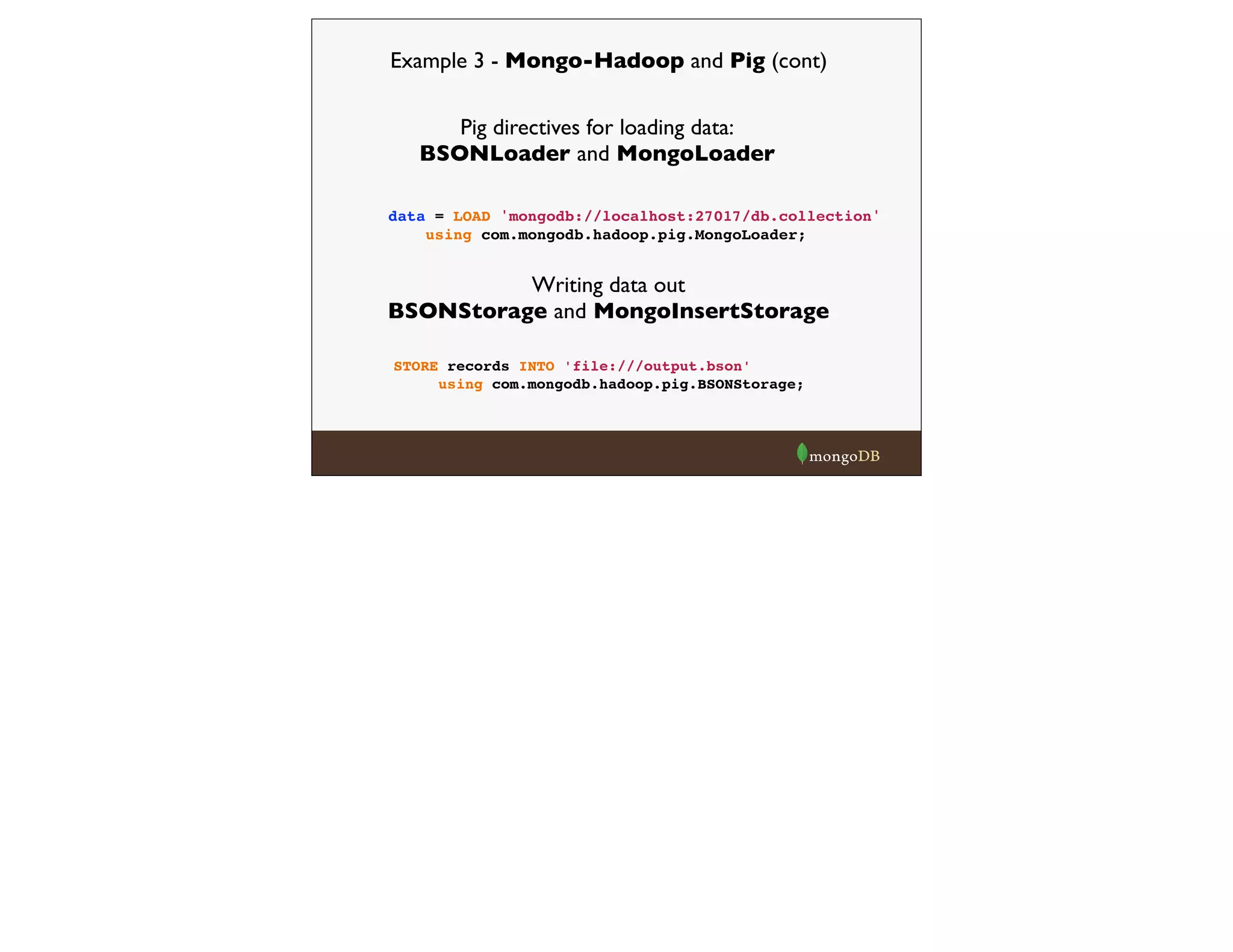
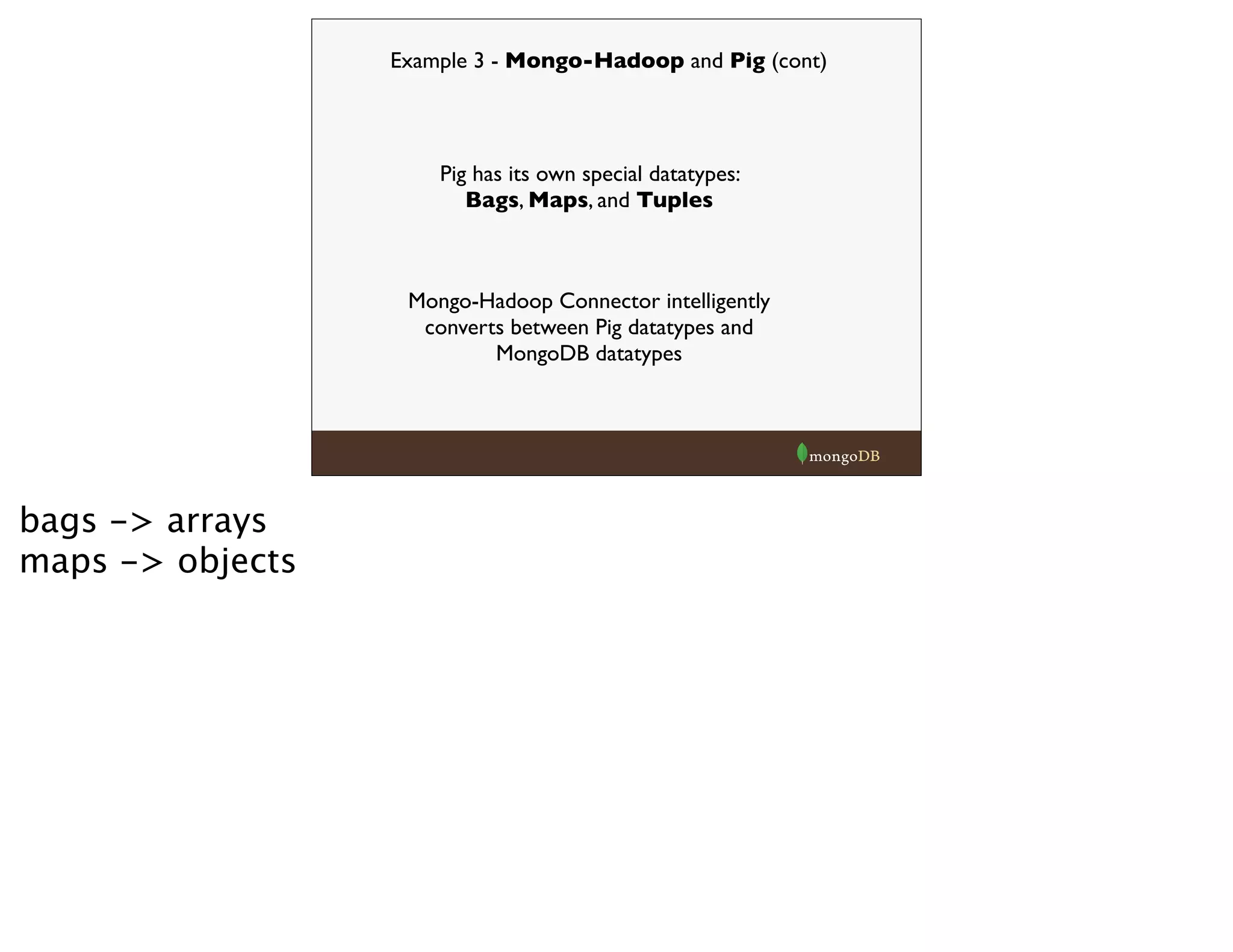
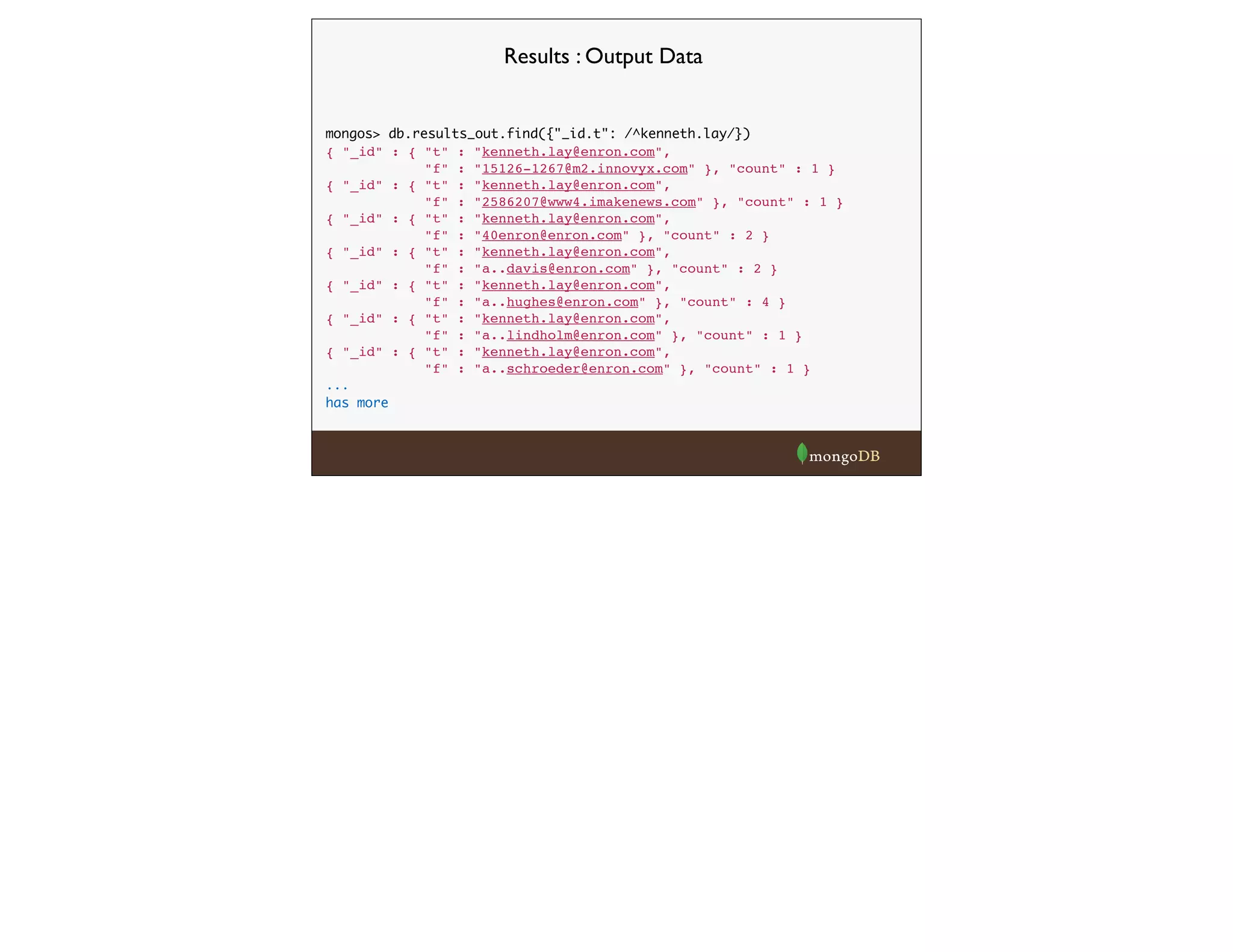
![raw = LOAD 'hdfs:///messages.bson'
using com.mongodb.hadoop.pig.BSONLoader('','headers:[]') ;
send_recip = FOREACH raw GENERATE $0#'From' as from, $0#'To' as to;
send_recip_filtered = FILTER send_recip BY to IS NOT NULL;
send_recip_split = FOREACH send_recip_filtered GENERATE
from as from, TRIM(FLATTEN(TOKENIZE(to))) as to;
send_recip_grouped = GROUP send_recip_split BY (from, to);
send_recip_counted = FOREACH send_recip_grouped GENERATE
group, COUNT($1) as count;
STORE send_recip_counted INTO 'file:///enron_results.bson'
using com.mongodb.hadoop.pig.BSONStorage;
Example 3 - Mongo-Hadoop and Pig (cont)](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-28-2048.jpg)
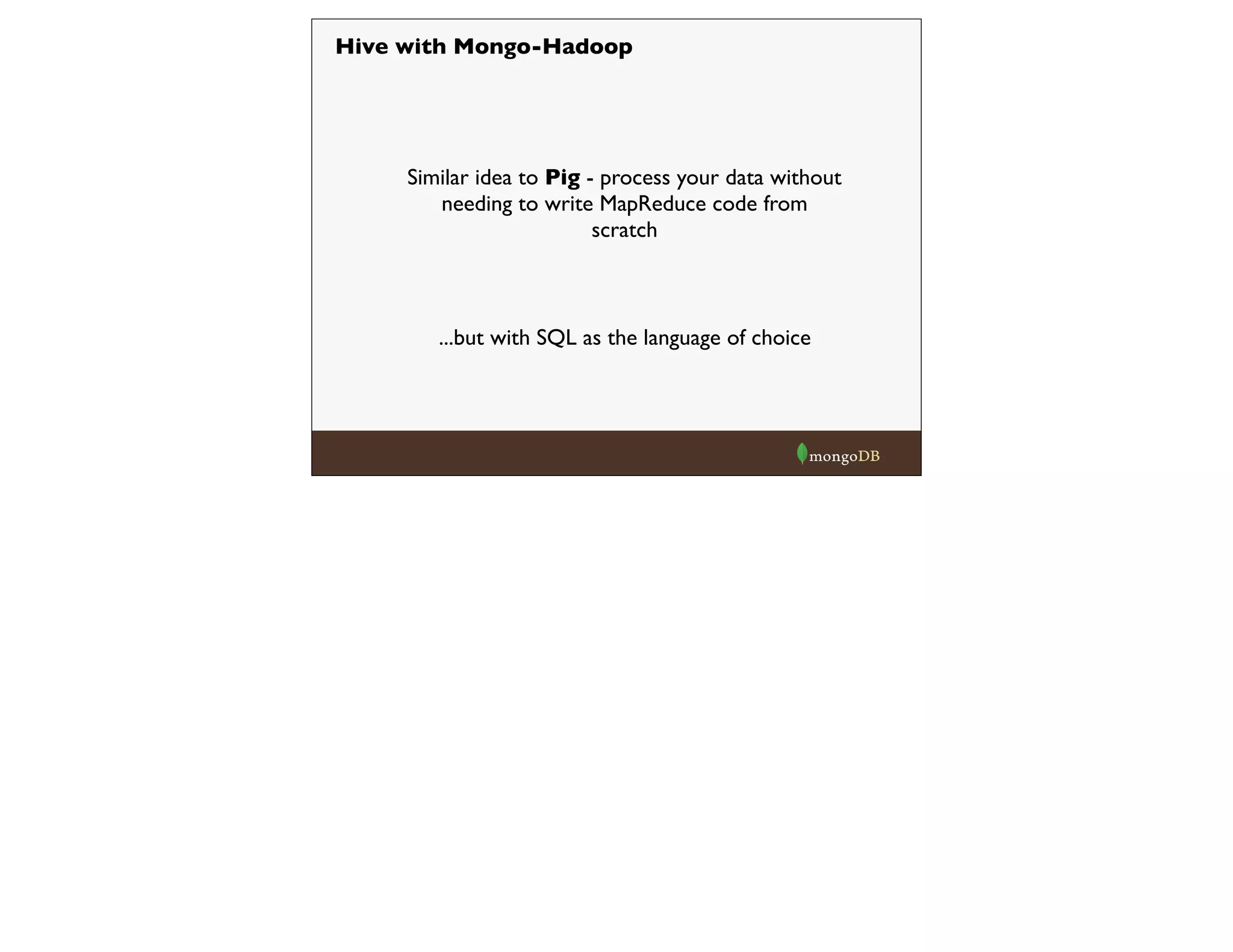







![Example 5 - MongoUpdateWritable
For example,
let’s say we have two collections.
{
"_id":
ObjectId("51b792d381c3e67b0a18d678"),
"sensor_id":
ObjectId("51b792d381c3e67b0a18d4a1"),
"value":
3328.5895416489802,
"timestamp":
ISODate("2013-‐05-‐18T13:11:38.709-‐0400"),
"loc":
[-‐175.13,51.658]
}
{
"_id":
ObjectId("51b792d381c3e67b0a18d0ed"),
"name":
"730LsRkX",
"type":
"pressure",
"owner":
"steve",
}
sensors
log
events
refers to which sensor
logged the event
For each owner, we want to calculate how many events
were recorded for each type of sensor that logged it.](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-39-2048.jpg)
![sensors
(mongodb collection)
Stage 1 -MapReduce
on sensors collection
Results
(mongodb collection)
for each sensor, emit:
{key: owner+type, value: _id}
group data from map() under each key, output:
{key: owner+type, val: [ list of _ids] }
read from
mongodb
insert() new records
to mongodb
MapReduce
log events
(mongodb collection)
do this in two stages](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-41-2048.jpg)
![the sensor’s
owner and type
After stage one, the output
docs look like:
list of ID’s of
sensors with this
owner and type
{
"_id":
"alice
pressure",
"sensors":
[
ObjectId("51b792d381c3e67b0a18d475"),
ObjectId("51b792d381c3e67b0a18d16d"),
ObjectId("51b792d381c3e67b0a18d2bf"),
…
]
}
Now we just need to count the total # of log events recorded for
any sensors that appear in the list for each owner/type group.](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-42-2048.jpg)

![Example - MongoUpdateWritable
Result after stage 2
{
"_id":
"1UoTcvnCTz
temp",
"sensors":
[
ObjectId("51b792d381c3e67b0a18d475"),
ObjectId("51b792d381c3e67b0a18d16d"),
ObjectId("51b792d381c3e67b0a18d2bf"),
…
],
"logs_count":
1050616
}
now populated with correct count](https://image.slidesharecdn.com/hadoop-webinar-091-140618133641-phpapp02/75/Hadoop-MongoDB-Webinar-June-2014-44-2048.jpg)


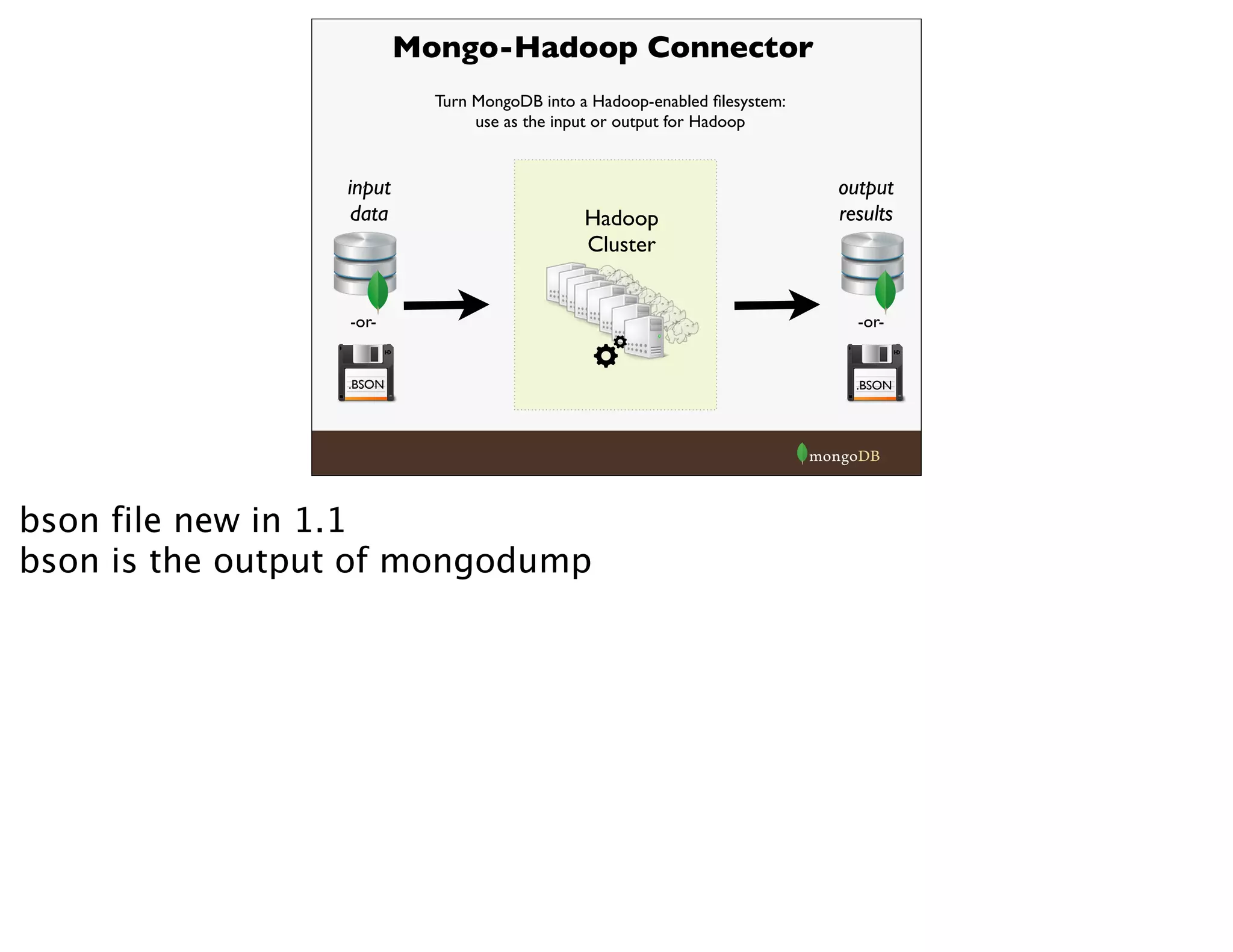
The document discusses Mongo-Hadoop integration and provides examples of using the Mongo-Hadoop connector to run MapReduce jobs on data stored in MongoDB. It covers loading and writing data to MongoDB from Hadoop, using Java MapReduce, Hadoop Streaming with Python, and analyzing data with Pig and Hive. Examples show processing an email corpus to build a graph of sender-recipient relationships and message counts.





























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































