










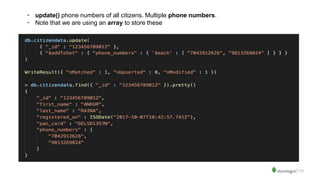



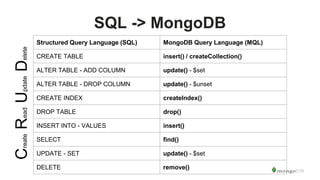










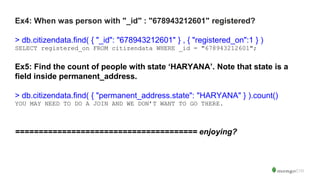
![Ex6: CREATE AN INDEX ON phone_numbers
> db.citizendata.createIndex( { phone_numbers: 1 } )
CREATE INDEX phone_numbers_1 ON citizendata (phone_numbers)
Ex7: Find details of a person with phone_number 8855915314. Note that
phone_numbers is an array type field.
> db.citizendata.find( { "phone_numbers": "8855915314" } ).pretty()
Ex8: Find _id of citizens with first_name REVA or ABEER
> db.citizendata.find( { "first_name": { "$in" : [ "REVA", "ABEER" ] } }, { _id: 1 } )](https://image.slidesharecdn.com/introductiontomongodb-igdtuw1-171020112726/85/Introduction-to-MongoDB-at-IGDTUW-44-320.jpg)
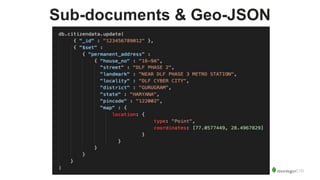
![Ex9: Find the count of people with first_name SANDEEP in each state. We are
using the MongoDB Aggregation Pipeline.
> db.citizendata.aggregate(
[
{ $match : { "first_name":'SANDEEP' } },
{ $group : { _id : "$permanent_address.state", count: {$sum: 1} } }
]
)
In SQL, you’ll use a GROUP BY clause for it. And may be some joins to bring in
this state info from another table.](https://image.slidesharecdn.com/introductiontomongodb-igdtuw1-171020112726/85/Introduction-to-MongoDB-at-IGDTUW-45-320.jpg)
![Ex10: Let’s sort our citizens in descending order with last_name ‘VERMA’ on
the basis of pan_card information using aggregation pipeline and limit our
result set to 10. Project only the phone numbers with NO _id field.
> db.citizendata.aggregate(
[
{ $match : { "last_name":'VERMA' } },
{ $sort : { "pan_card" : -1 } },
{ $project : { "_id": 0, "pan_card":1,"phone_numbers":1 } },
{ $limit : 10 }
]
)](https://image.slidesharecdn.com/introductiontomongodb-igdtuw1-171020112726/85/Introduction-to-MongoDB-at-IGDTUW-46-320.jpg)

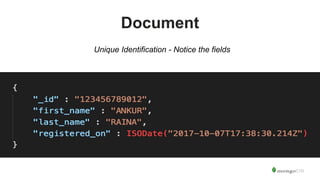
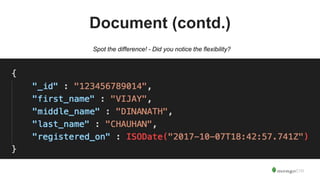
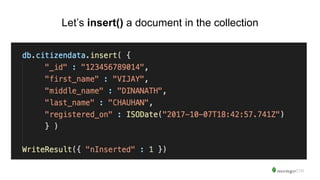
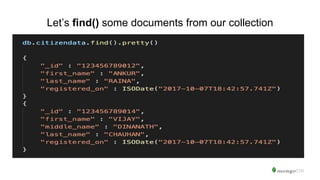
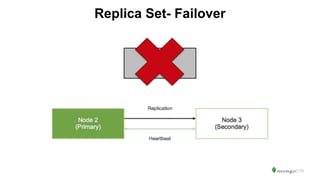
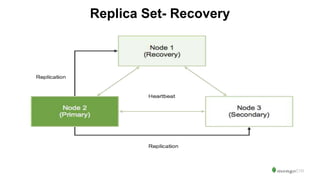
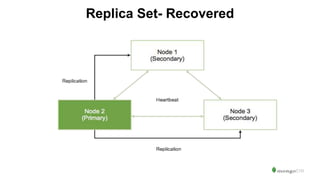
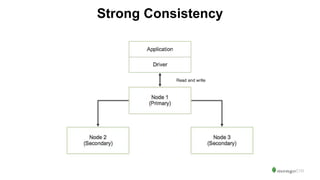
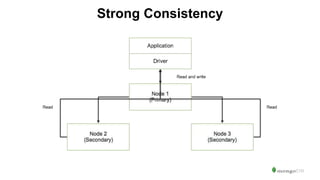
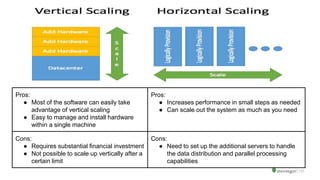
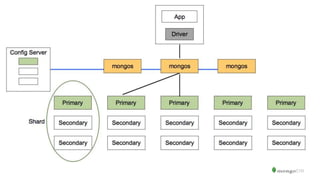
The document serves as an introduction to MongoDB, detailing its structure as an open-source document database and exploring its functionality through various use cases and hands-on exercises. It covers topics such as CRUD operations, data modeling with BSON, high availability, and scalability. Additionally, practical examples guide users through connecting to databases, querying data, creating indexes, and using aggregation pipelines.










































































