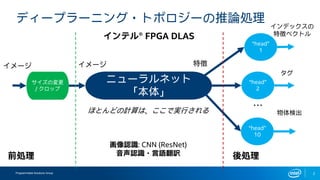
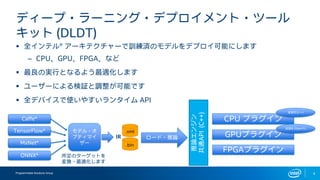
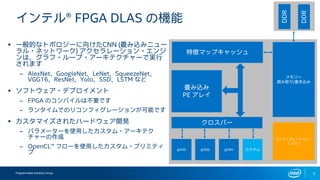
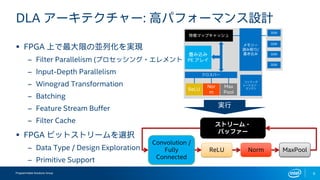
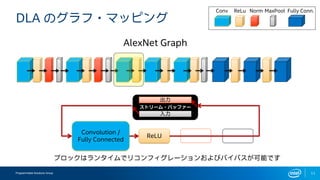
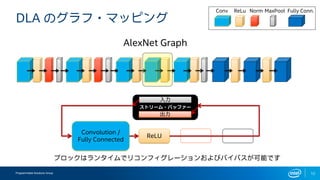
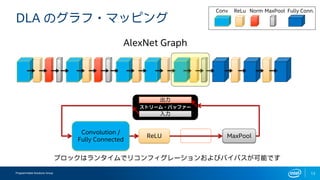
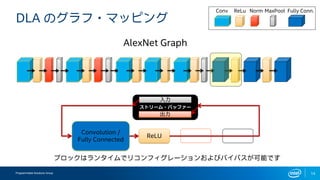
インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveをHW視点から比較してみる インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveは、どちらもFPGAを用いてインファレンス処理を行うものでありながら、その内部構成は180度異なります。ここでは両者を比較しつつ、インテルのインファレンスソリューションについて解説します。




















































![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)