Recommended
PDF
Convolutional Neural Network @ CV勉強会関東
PPTX
Cvim saisentan-6-4-tomoaki
PDF
PPT
PPTX
MIRU2014 tutorial deeplearning
PPTX
PDF
PPTX
PDF
PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
PDF
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PythonによるDeep Learningの実装
PDF
Introduction to Deep Compression
PDF
PDF
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像
PDF
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
鳥肌必至のニューラルネットワークによる近未来の画像認識技術を体験し、IoTの知られざるパワーを知る
PDF
2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで
PDF
畳み込みニューラルネットワークが なぜうまくいくのか?についての手がかり
PDF
PDF
PDF
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
PDF
最近のSingle Shot系の物体検出のアーキテクチャまとめ
PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
PDF
Sparse Codingをなるべく数式を使わず理解する(PCAやICAとの関係)
More Related Content
PDF
Convolutional Neural Network @ CV勉強会関東
PPTX
Cvim saisentan-6-4-tomoaki
PDF
PPT
PPTX
MIRU2014 tutorial deeplearning
PPTX
PDF
PPTX
What's hot
PDF
PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
PDF
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PythonによるDeep Learningの実装
PDF
Introduction to Deep Compression
PDF
PDF
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PDF
[論文紹介] Convolutional Neural Network(CNN)による超解像
PDF
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
鳥肌必至のニューラルネットワークによる近未来の画像認識技術を体験し、IoTの知られざるパワーを知る
PDF
2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで
PDF
畳み込みニューラルネットワークが なぜうまくいくのか?についての手がかり
PDF
PDF
PDF
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
PDF
最近のSingle Shot系の物体検出のアーキテクチャまとめ
Similar to 多層NNの教師なし学習� コンピュータビジョン勉強会@関東 2014/5/26
PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
PDF
Sparse Codingをなるべく数式を使わず理解する(PCAやICAとの関係)
PDF
PDF
PPTX
[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)
PDF
PDF
BA-Net: Dense Bundle Adjustment Network (3D勉強会@関東)
PDF
makoto shing (stability ai) - image model fine-tuning - wandb_event_230525.pdf
PDF
ICML2019@Long Beach 参加速報(3日目)
PPTX
人と機械の協働によりデータ分析作業の効率化を目指す協働型機械学習技術(NTTデータ テクノロジーカンファレンス 2020 発表資料)
PDF
PDF
PRML復々習レーン#10 7.1.3-7.1.5
PPTX
「解説資料」Set Transformer: A Framework for Attention-based Permutation-Invariant ...
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PDF
PPTX
Curriculum Learning (関東CV勉強会)
PDF
PDF
(文献紹介)Deep Unrolling: Learned ISTA (LISTA)
PPT
Deep Auto-Encoder Neural Networks in Reiforcement Learnning (第 9 回 Deep Learn...
PDF
多層NNの教師なし学習� コンピュータビジョン勉強会@関東 2014/5/26 1. 2. 参考文献
• [1] 岡谷貴之, 斉藤真樹. ディープラーニング チュートリアル.
http://www.vision.is.tohoku.ac.jp/index.php/download_file/view/15/137/
• [2] Andrew Ng. CS294A Lecture notes: Sparse autoencoder.
http://www.stanford.edu/class/cs294a/sparseAutoencoder.pdf
• [3] 得居誠也. Deep Learning 技術の今.
https://www.slideshare.net/beam2d/deep-learning20140130
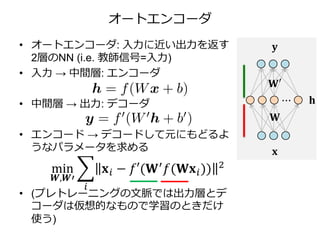
3. 4. 5. 6. 7. オートエンコーダ
• 中間層のサイズ > 入力サイズだと自明な解
(恒等関数)を得てしまう (右図)
• 恒等関数を学習しないようにする工夫:
– 中間層を入力層より小さくする
(bottleneck)
– hがスパースになるように正則化 (3.3節)
– Denoising Auto Encoder*
• と制約してしまうことが多い
– f(x) = xを考えるとわかりやすい (PCAみ
たいなかんじ)
* P. Vincent, H. Larochelle, Y. Bengio and P.-A. Manzagol. Extracting and Composing Robust Features with Denoising Autoencoders. ICML 2008.
8. 9. 10. オートエンコーダの微調整 (fine tuning)
• 微調整 (fine tuning): プレトレーニング後に、ネットワー
ク全体を学習し直して最終的なモデルを得る
• 教師無し、有りともによい初期値が与えられているので
うまく学習できる (よい局所解にたどり着ける)
教師有り
各ノードがクラス
ラベルに対応する
出力層を乗せて、
(BPで)学習
教師無し
全体をひとつのオー
トエンコーダとみな
して学習
[1]より
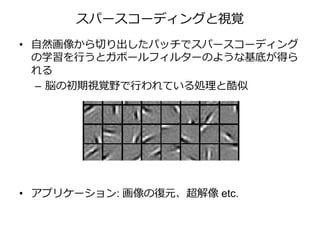
11. 12. 13. スパースコーディング*
• 与えられたサンプルを少数の基底の線形結合で表現でき
るように、基底の集合(dictionary)を学習
• 学習時にはD, hを最適化、Dがきまればxに対してhを計
算
• 基底の数 > 特徴次元: overcomplete
* Olshausen, B. A. and Field, D. J.: Emeregnce of simple- cell receptive field properties by learning a sparse code for natural images, Nature, Vol. 381, pp. 607–
609 (1996).
スパースコ ーディ ング
, Sparse Coding w ith an Overcom plete Basis Set: a Strategy Em ployed by V1?, Vis. R
min
,
1
2
+
過
(
{ } = , … ,
dictionary
code スパース項: 理想的にはL0
14. スパースコーディング
スパースコ ード = [0, 0, …, 0, 0.8, 0, …, 0, 0.3, 0, …, 0, 0.5, …]
Figs from [Yu and Ng, Feature learning for im age classification, Tutorial, ECCV10]
Olshausen, Field, Sparse Coding w ith an Overcom plete Basis Set: a Strategy Em ployed by V1?, Vis. Research96
0.8 * + 0.3 * + 0.5 *
Natural im age patches
min
,
1
2
+
過完備性
( overcom plete)
{ } = , … ,
15. 16. 17. 18. 19. 20. Topographic ICA
• プーリング層の発火 を抑えるには、
同じプーリングユニットにつながっているフィルタ層の
ノードは似たパターンに反応するべき
– 常に少数のユニットが反応をするより、たまに多数
のユニットが反応する方が上の値は小さくなる
• 結果同じプーリングユニットには似た特徴がつながる
– → プーリングユニットが微笑な変形に不変性を持つ
21.



![参考文献
• [1] 岡谷貴之, 斉藤真樹. ディープラーニング チュートリアル.
http://www.vision.is.tohoku.ac.jp/index.php/download_file/view/15/137/
• [2] Andrew Ng. CS294A Lecture notes: Sparse autoencoder.
http://www.stanford.edu/class/cs294a/sparseAutoencoder.pdf
• [3] 得居誠也. Deep Learning 技術の今.
https://www.slideshare.net/beam2d/deep-learning20140130](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-2-320.jpg)

![プレトレーニング
• 深い多層NNの誤差逆伝搬法による学習はランダムな初
期値ではあまりうまくいかない (2.1.2節)
• よい初期値を与えるために、事前に層毎の教師無し学習
を行う (pretraining)
• あらためてネットワーク全体を学習する (fine-tuning)
[1]より
pretraining fine-tuning](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-4-320.jpg)

![オートエンコーダの性質
• 入力を復元できるhを得る
– → 学習サンプルの構造を低次元で (bottleneck) or ス
パースに (スパース正則化) 捉える変換を学習してい
る
• オートエンコーダを自然画像から切り出したパッチで学
習した結果:
[2]より](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-8-320.jpg)
![オートエンコーダによるプレトレーニング
• 入力層からの2層に、仮想的にデコーダを乗せて学習
• hを入力と見なして、次の2層を同様に学習
• 繰り返し
[1]より](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-9-320.jpg)
![オートエンコーダの微調整 (fine tuning)
• 微調整 (fine tuning): プレトレーニング後に、ネットワー
ク全体を学習し直して最終的なモデルを得る
• 教師無し、有りともによい初期値が与えられているので
うまく学習できる (よい局所解にたどり着ける)
教師有り
各ノードがクラス
ラベルに対応する
出力層を乗せて、
(BPで)学習
教師無し
全体をひとつのオー
トエンコーダとみな
して学習
[1]より](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-10-320.jpg)

![スパースオートエンコーダ
• Wではなくhをスパースにすることに注意
– Wを基底の集合としてみると、できるだけ少数の基底
の組み合わせで入力を再現できるように学習
• スパースコーディングと似ている
[1]より](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-12-320.jpg)

![スパースコーディング
スパースコ ード = [0, 0, …, 0, 0.8, 0, …, 0, 0.3, 0, …, 0, 0.5, …]
Figs from [Yu and Ng, Feature learning for im age classification, Tutorial, ECCV10]
Olshausen, Field, Sparse Coding w ith an Overcom plete Basis Set: a Strategy Em ployed by V1?, Vis. Research96
0.8 * + 0.3 * + 0.5 *
Natural im age patches
min
,
1
2
+
過完備性
( overcom plete)
{ } = , … ,](https://image.slidesharecdn.com/autoencoder20140526up-140524232630-phpapp02/85/NN-2014-5-26-14-320.jpg)






















![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)





