The document discusses keyphrase extraction from Korean directives using discourse components. It introduces keyphrases and their difference from summaries. Related work on using structured query language, bilingual pivoting, and discourse components for keyphrase extraction is reviewed. The document then describes the construction of a Korean parallel corpus annotated with keyphrases and methods for augmenting the dataset with new question and command examples generated from keyphrases. Potential applications of the keyphrase extraction framework include semantic search and paraphrase generation.




![Introduction
• Keyphrase vs. Summary
Summarization of a document can be either (conventionally):
• Extractive [Cheng and Lapata, 2016]
– Documents have several sentence candidates
• Abstractive [Rush et al., 2015]
– Documents without a representative sentence can be abstractively summarized
• Hybrid methodologies are in progress [Bae et al., 2019]
In keyphrase extraction from the sentences:
• Both extractive and abstractive approach can be utilized
– Extractive: for the keywords
– Abstractive: for the plausible expression (sentence style, word-level paraphrasing)
4
오늘 저녁 여덟 시에 서울대입구 풍경소리에서 동아리 뒷풀이가 있을 예정입니다.
→ 오늘 이십 시 서울대입구 풍경소리에서 동아리 뒷풀이 예정](https://image.slidesharecdn.com/1910hclt-191012144858/75/1910-HCLT-5-2048.jpg)


![Related work
• 많이들 궁금해하셨던 내용을 알려드리면, 올해에는 시월 십이일부터 십
삼일까지 카이스트에서 한글 및 한국어 정보처리 학술대회가 개최됩니다.
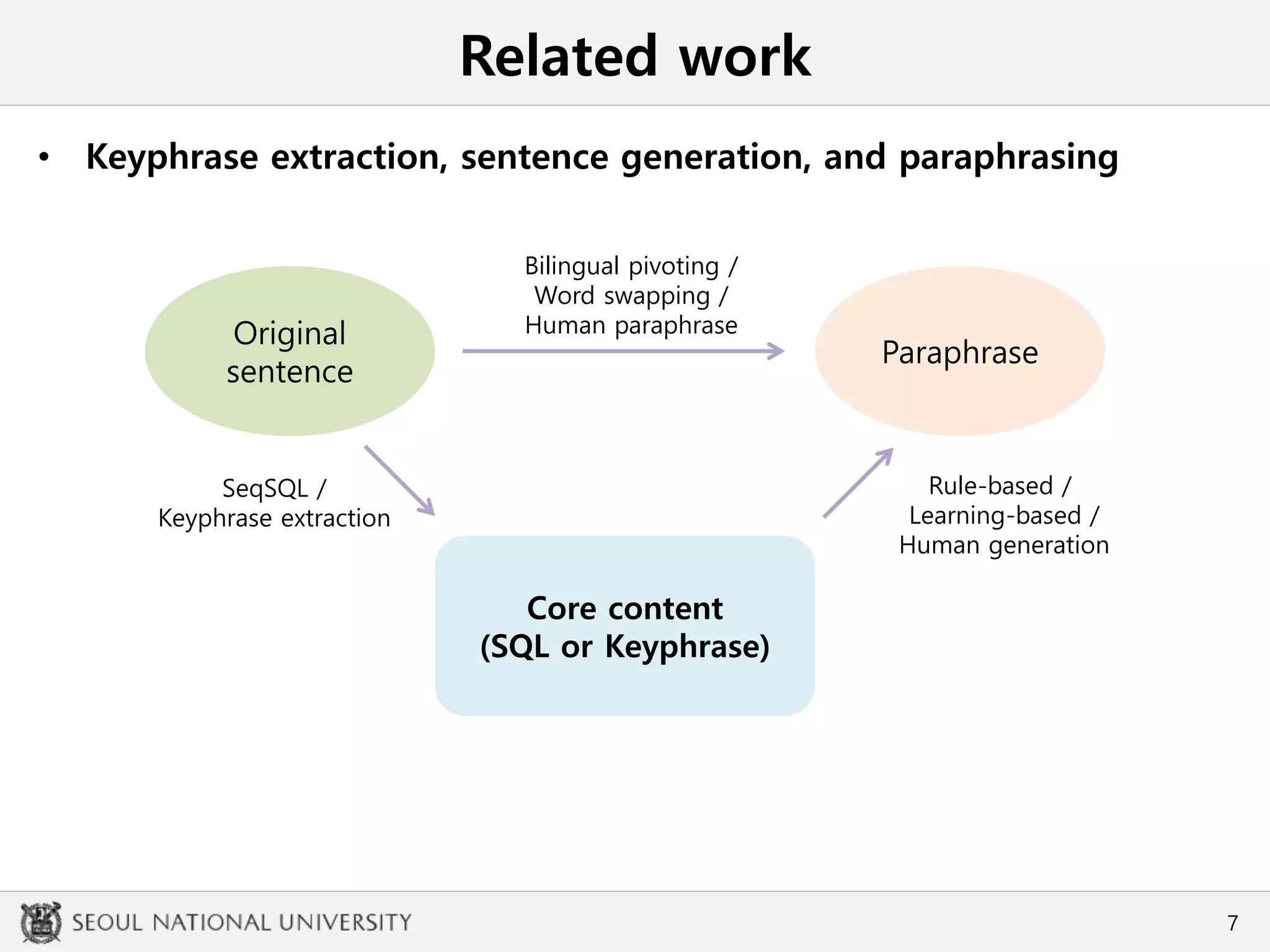
– How can we obtain a core content for paraphrasing (possibly by human)?
• Structured query language (SQL) [Zhong et al., 2017]
{기간: 올해 시월 십이일부터 십삼일, 장소: 카이스트, 이벤트: 한글 및 한국어
정보처리 학술대회}
• A kind of semantic parsing
• Structured extraction of information is available
• Human-friendly data generation is not guaranteed
• Categorization can be limited
• Bilingual pivoting (BP) [Mallison et al., 2017]
“As many of you may have waited for, we hold HCLT conference at KAIST
from twelfth to thirteens upcoming October.”
• Back-translation using other languages may give various expressions
• 1-1 correspondence doesn’t help extract the core content of the sentence
8](https://image.slidesharecdn.com/1910hclt-191012144858/75/1910-HCLT-9-2048.jpg)
![Related work
• 많이들 궁금해하셨던 내용을 알려드리면, 올해에는 시월 십이일부터 십
삼일까지 카이스트에서 한글 및 한국어 정보처리 학술대회가 개최됩니다.
– How can we obtain a core content for paraphrasing (possibly by human)?
• Discourse component [Portner, 2004]
This approach incorporates human generation, but can be efficient
• E.g., the following can be discourse component for the declaratives:
– 올해 시월 십이일부터 십삼일까지 카이스트에서 한글 및 한국어 정보처리 학술대회 개
최 (Common Ground)
• Core content information in monolingual natural language format
9](https://image.slidesharecdn.com/1910hclt-191012144858/75/1910-HCLT-10-2048.jpg)
![Corpus construction
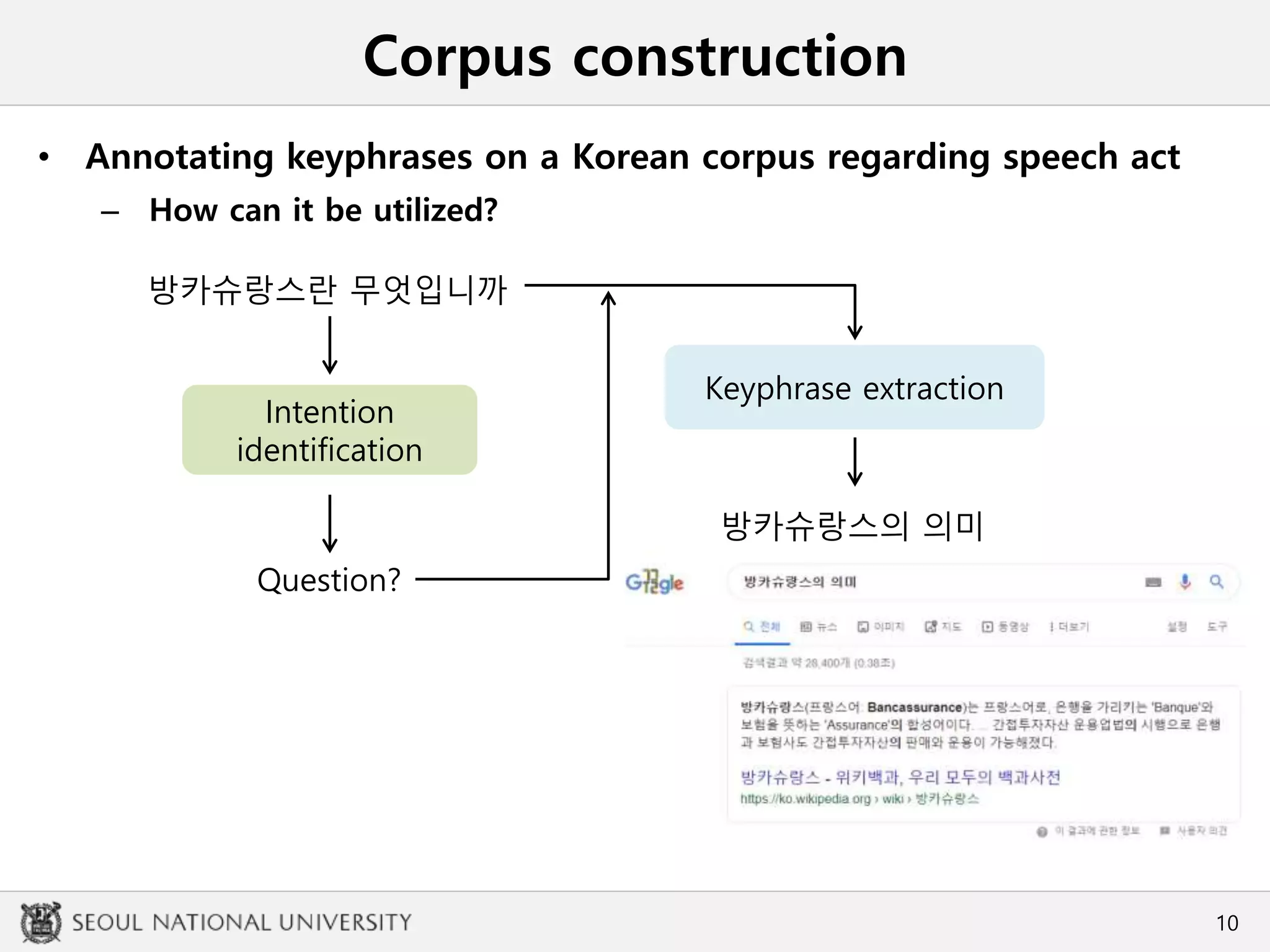
• Annotating keyphrases on a Korean corpus regarding speech act
Corpus: Intention identification for Korean (3i4K) [Cho et al., 2018]
Composition
• Question
• Command
• Rhetorical question
• Rhetorical command
• Statement
• Intonation-dependent utterances
• Fragments
11
Includes only utterances whose determination of
speech act was not affected by the sentence form
• Utterances are non-canonical and colloquial
• Includes various topics and situations](https://image.slidesharecdn.com/1910hclt-191012144858/75/1910-HCLT-12-2048.jpg)

![Data augmentation
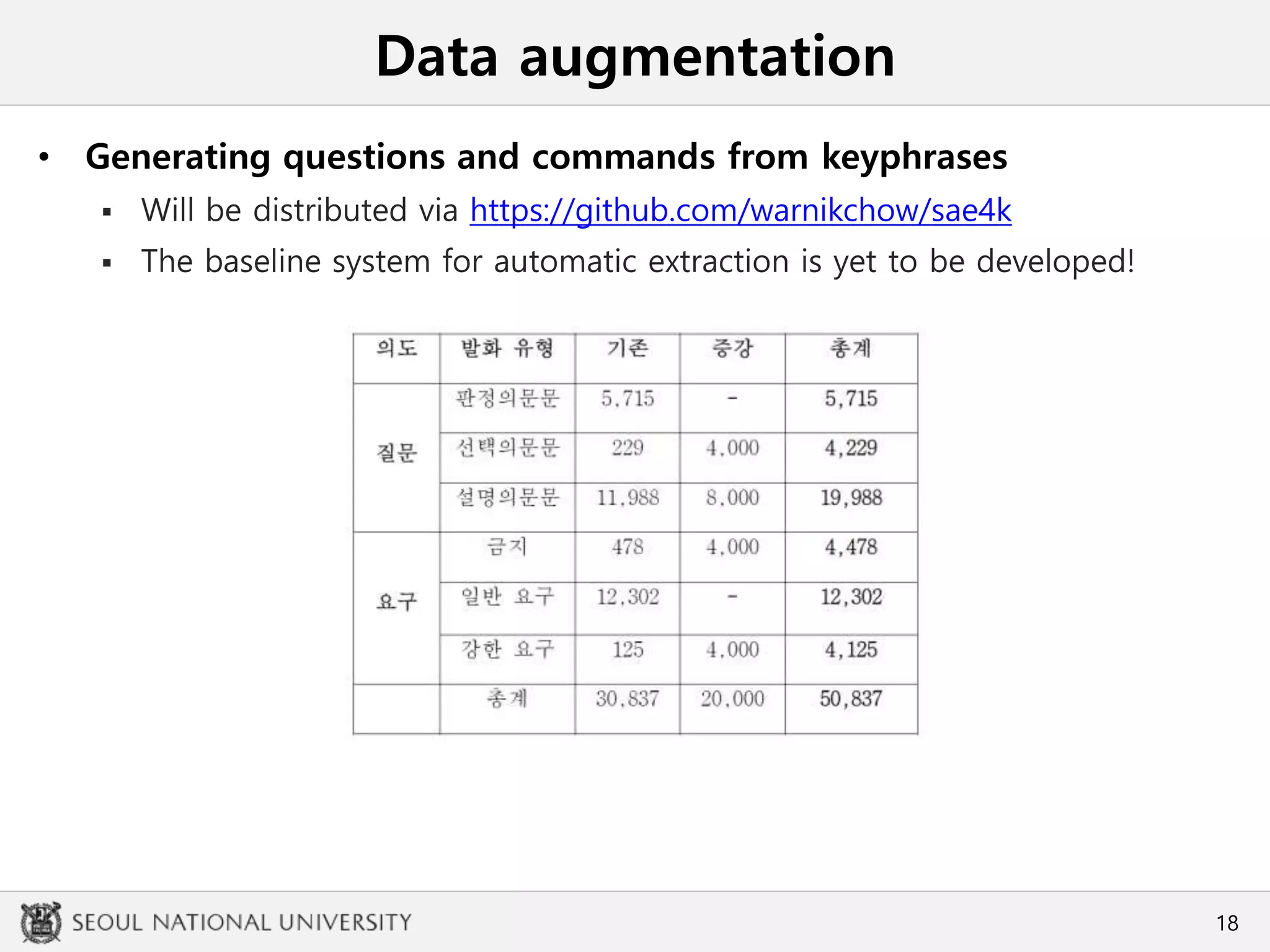
• Generating questions and commands from keyphrases
Prototype model [Cho et al., 2018] lacks alternative Qs, prohibitions and
strong REQs
Scarce within the corpus, but frequently utilized in real-life
• Augmentation is required! but HOW?
13](https://image.slidesharecdn.com/1910hclt-191012144858/75/1910-HCLT-14-2048.jpg)




















![[AAAI 2019 tutorial] End-to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/aaai2019tutorialend-to-endgoal-orientedquestionansweringsystems-190128122117-thumbnail.jpg?width=640&height=640&fit=bounds)


















![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)




































