한국어 문서 추출요약AI 경진대회
참가 후기
김한길
Photo by Sudan Ouyang on Unsplash
2.
대회 개요 및제한조건
• 대회명: 한국어 문서 추출요약 AI 경진대회
• 대회 기간: 2020.11.11 ~ 2020.12.09 18:00
• 데이터: 뉴스기사 데이터셋 + 요약문(사람 생성)
• 규정
• 평가지표: ROUGE-1(점수1), ROUGE-2(점수2), ROUGE-L(점수3)별 개별 순위 합산 역순
• 추출요약: 주어진 본문 내 문장 중 3개를 선택하여 그대로 제출
• 외부 데이터 및 사전 학습 모델
• 외부 데이터 사용 불가
• 지정된 Pre-trained 모델(ETRI-BERT, SKT-BERT, SKT-GPT)만 사용만 가능
2
3.
Data 개요 및EDA
3
https://colab.research.google.com/drive/1Z8MoApNT4C
JnsPN5bAiKm7XOlUic0kl9?usp=sharing
4.
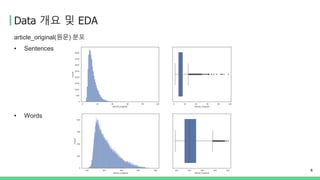
Data 개요 및EDA
4
article_original(원문) 분포
• Sentences
• Words
5.
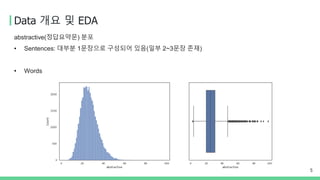
Data 개요 및EDA
5
abstractive(정답요약문) 분포
• Sentences: 대부분 1문장으로 구성되어 있음(일부 2~3문장 존재)
• Words
6.
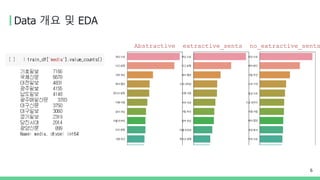
Data 개요 및EDA
6
Abstractive extractive_sents no_extractive_sents
7.
모델: BERTSUMEXT
• 논문및 코드
• [BERTSum] Fine-tune BERT for Extractive Summarization; Code
• [PreSumm] Text Summarization with Pretrained Encoders; Code
7
8.
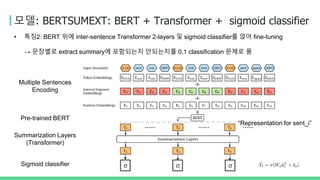
모델: BERTSUMEXT
• 특징1:기 Pre-trained BERT를 summarization task 수행을 위한 embedding layer로 활용하려면?
→ 여러 sentence를 하나의 인풋으로 넣어줘야 함
• Input document에서 매 문장의 앞에 [CLS] 토큰을 삽입
( [CLS] 토큰에 대응하는 BERT 결과값(T[CLS])을 각 문장별 representation으로 간주)
• 매 sentence마다 다른 segment embeddings 토큰을 더해주는 interval segment embeddings
8
모델: BERTSUMEXT
• 모델선정 이유
• BERT-based pre-trained model을 그대로 활용할 수 있음
• ‘간단한 구조를 가지고 있으니 한국어 모델로 바꾸는게 쉽지 않을까?’
• Pre-trained BERT로 KoBERT(SKTBERT) 사용
• BERTSUMEXT 코드를 살펴보니 Huggingface transformers 라이브러리를 사용하여 Pre-trained
BERT 이용하고 있었음
→ ‘Transformers(monologg)를 통해 Huggingface transformers 라이브러리를 지원하는
KoBERT와 연결이 용이하지 않을까?’
• 관련 코드: https://github.com/SKTBrain/KoBERT
10
11.
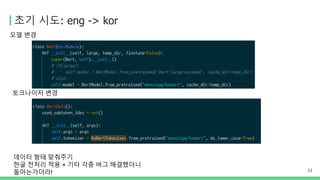
초기 시도: eng-> kor
11
데이터 형태 맞춰주기
한글 전처리 적용 + 기타 각종 버그 해결했더니
돌아는가더라!
토크나이저 변경
모델 변경
12.
But… 15~20위권에서 왔다갔다…
12
혼자하다 보니 문제가 무엇인지 파악이 어려움
- 전처리가 부족한가? 잘못됐나?
- 정답 sentence로 ext를 사용했어야 했나?
- BERT 연결 부분이 잘못됐나? Special token 설정을 잘못했나?
- KoBERT가 구린가? KorBERT로 바꿔볼까?
- BERTSUMEXT 모델이 구린가?
13.
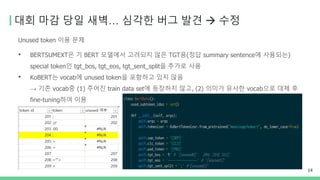
대회 마감 당일새벽… 심각한 버그 발견 → 수정
• 어떻게 하면 gold summary(사람이 직접 생성한 Abstractive sentence)를
Oracle summary(extract sentence)로 전환할 것인가?
→ 보통 greedy selection 방식을 선택
• 이를 선택하기 전 클리닝 단계에서 한글이 모두 제외되는 문제 발견 -> 수정
• 성능을 높이고 대회규정을 충족시켜주기 위해 mix_selection 구현
• greedy 방식으로 무조건 3문장까지 추출되도록
• 추출한 3문장의 모든 조합(3!)에 대해 rouge1+rouge2+rougeL score가 가장 높은 경우를 선정
13
14.
대회 마감 당일새벽… 심각한 버그 발견 → 수정
Unused token 이용 문제
• BERTSUMEXT은 기 BERT 모델에서 고려되지 않은 TGT용(정답 summary sentence에 사용되는)
special token인 tgt_bos, tgt_eos, tgt_sent_split을 추가로 사용
• KoBERT는 vocab에 unused token을 포함하고 있지 않음
→ 기존 vocab중 (1) 주어진 train data set에 등장하지 않고, (2) 의미가 유사한 vocab으로 대체 후
fine-tuning하여 이용
14
Preprocessing
관련 주요 파일목록
• src/make_data.py, preprocess.py : Preprocessing 실행 및 기본 데이터 변환
• Src/prepro/data_builder.py, tokenization_kobert.py : BERT 입력용 데이터 포맷 생성
16
17.
Preprocessing: Cleaning
• Pre-trainedBERT를 이용함에 따라 Cleaning은 최소한으로 적용
• html 삭제
• tgt special token으로 사용한 문자열( ¶, ----------------, ;) 제거
• 여기서 삽질을 엄청 오랜시간동안 함
17
18.
Preprocessing: 정답(oracle) summary문장 만들기
• 주어진 데이터셋에서 정답 문장으로 "extractive"가 아닌 "abstractive" 문장을 이용
① abstractive 문장들은 문장간 구분이 되어 있지 않게 주어졌기 때문에 kss를 수정한 함수를 적용하여
문장 토크나이징 수행
18
src/make_data.py
19.
Preprocessing: 정답(oracle) summary문장 만들기
② abstractive 문장에 대해
(1) greedy한 방식으로 rouge score를 높일 수 있는 문장 3개 추출,
(2) 선택한 3개 문장의 모든 조합(permutaion)에 대해서 rouge score를 최대로 하는 조합을 구함
③ BERT 입력용 데이터 생성하기( 앞 "PreSumm" 설명 참조)
19
srcpreprodata_builder.py
20.
Fine-tuning
관련 주요 파일목록
• src/make_data.py, preprocess.py : Preprocessing 실행 및 기본 데이터 변환
Training parameters
• batch_size: 3000
• learning rate: warmup 방식 사용
0.0000001부터 50 step당 0.0000001씩 증가하여 10000step까지 0.00002로 증가하다가 다시
감소하는 방식 사용
결과
• 총 50000 step까지 training
• validation set으로 테스트한 결과 7000 step에서 가장 좋은 성능을 보임
20
후기
배운점
• KoBERT 사용법및 장단점 파악
• Pre-trained Model을 사용함에 있어서 Pre-training 관련 정보(전처리, 토크나이저)가 얼마나 중요한지!
• 오랜 시간 모델 트레이닝을 위한 기법들
• Distributed를 통한 GPU 활용
• Logger 중요성
• 빠른 실험 반복을 위한 파이프라인 구축
• ‘모델에 대한 이해’와 ‘구현’은 다른 문제다.
다시 한다면…
• 언론사 정보 반영
• 하이퍼파라미터 튜닝
• KorBERT(ETRI) 또는 적용해보기, do_lower_case를 False로 하고 해보기
22
23.
실행 환경
• E5-2620v4 @ 2.10GHz x 16
• NVIDIA Quadro RTX 5000 x 2
• Ubuntu 18.04
23
24.
실행방법 안내
24
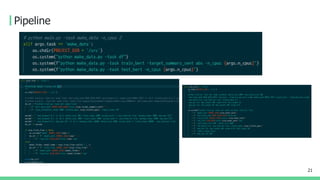
1. 필요라이브러리 설치하기
python main.py -task install
2. 데이터 Preprocessing
# 2-1. 데이터를 ext/data/raw 에 넣어주기
# 2-2. Data preprocessing
# n_cpus 인자값을 이용할 CPU 수로 변경해주기
python main.py -task make_data -n_cpus 2
3. Fine-tuning
python main.py -task train -target_summary_sent abs -visible_gpus 0
4. Inference & make submissioon file
# visible_gpus 인자값을 이용할 GPU index 값으로 변경해주기
# 예(GPU 3개를 이용할 경우): -visible_gpus 0,1,2
python main.py -task test -test_from 1209_1236/model_step_7000.pt -visible_gpus 0
5. 최종 결과 파일 확인
경로: ext/data/results/submission_날짜_시간.csv




![모델: BERTSUMEXT
• 논문 및 코드
• [BERTSum] Fine-tune BERT for Extractive Summarization; Code
• [PreSumm] Text Summarization with Pretrained Encoders; Code
7](https://image.slidesharecdn.com/a-210128014137/85/AI-7-320.jpg)
![모델: BERTSUMEXT
• 특징1: 기 Pre-trained BERT를 summarization task 수행을 위한 embedding layer로 활용하려면?
→ 여러 sentence를 하나의 인풋으로 넣어줘야 함
• Input document에서 매 문장의 앞에 [CLS] 토큰을 삽입
( [CLS] 토큰에 대응하는 BERT 결과값(T[CLS])을 각 문장별 representation으로 간주)
• 매 sentence마다 다른 segment embeddings 토큰을 더해주는 interval segment embeddings
8](https://image.slidesharecdn.com/a-210128014137/85/AI-8-320.jpg)




















![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)








![[부스트캠프 Tech Talk] 진명훈_datasets로 협업하기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkjinmyunghoon-211210113319-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...](https://cdn.slidesharecdn.com/ss_thumbnails/20200904furuta-200904014839-thumbnail.jpg?width=640&height=640&fit=bounds)







![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [B01Z] HAP-PY_음성 인식 기반 AI 면접 솔루...](https://cdn.slidesharecdn.com/ss_thumbnails/b01zhap-pyai-240812134440-ff36618d-thumbnail.jpg?width=640&height=640&fit=bounds)













![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [뉴진스] : Multi-modal Fake News Detection](https://cdn.slidesharecdn.com/ss_thumbnails/ppt-230809091137-7c2888d8-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper Review] What have we achieved on text summarization?](https://cdn.slidesharecdn.com/ss_thumbnails/whathaveweachievedontextsummarizationhangil-210127184856-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)