20/09/17 DevC Seongnam Opening Event
https://festa.io/events/1158
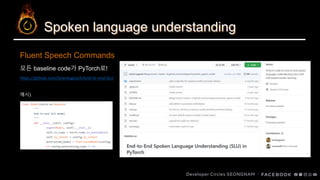
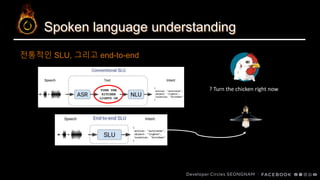
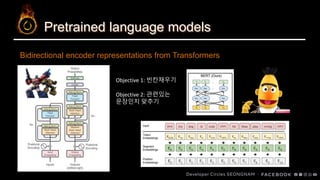
SLU? BERT? Distillation? 그게 뭔데… 어떻게 하는 건데… (feat. PyTorch)
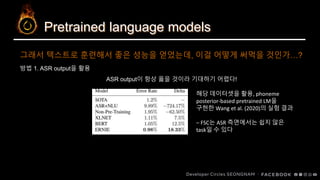
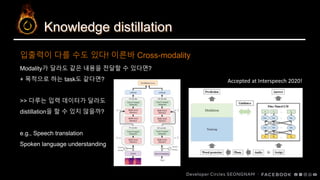
본 talk에서는 음성으로부터 intent를 추출하는 SLU task에 BERT와 같은 pretrained langauge model을 적용하는 과정에서 직접적으로 적용하는 것의 난점과 knowledge distillation으로써 이를 해결하는 과정에 대해 다룹니다.






















































![[2021 Google I/O] LaMDA : Language Models for DialogApplications](https://cdn.slidesharecdn.com/ss_thumbnails/lamda-220318093910-thumbnail.jpg?width=640&height=640&fit=bounds)












![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)











![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)









