Download as PDF, PPTX














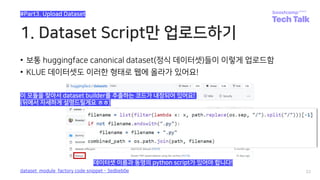


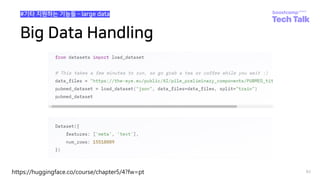
![데이터셋 스크립트 작성요령
26
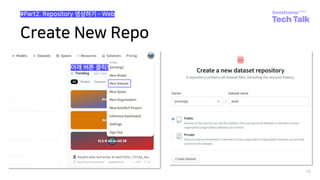
#How to write dataset script?
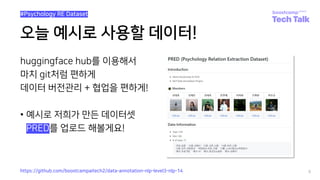
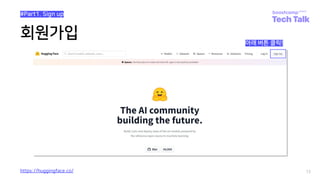
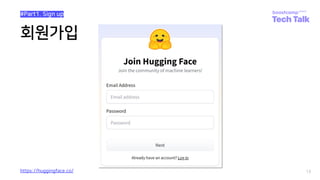
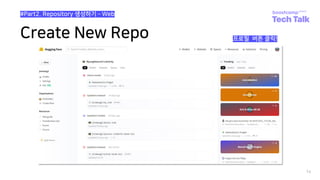
Huggingface dataset-hub 업로드 경험 공유
import datasets
_URL = “...”
_LICENSE = “...”
class MyDataConfig(datasets.BuilderConfig):
def __init__(self, ...):
super().__init__(...)
class MyData(datasets.GeneratorBasedBuilder):
BUILDER_CONFIGS = [MyDataConfig(...)]
def _info(self):
return datasets.DatasetInfo(...)
def _split_generators(self, dl_manager):
pass
def _generate_examples(self, **kwargs):
pass](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-26-320.jpg)














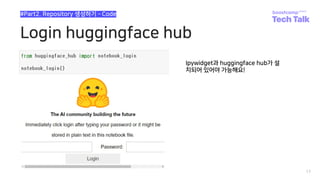
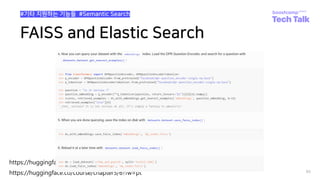
![GeneratorBasedBuilder Class
41
#How to write dataset script?
Huggingface dataset-hub 업로드 경험 공유
class MyData(datasets.GeneratorBasedBuilder):
BUILDER_CONFIGS = [MyDataConfig(...)]
Builder 클래스 작성
• datasets.GeneratorBasedBuilder subclass
• BUILDER_CONFIGS는 list 형태로 여러 가지
data에 대한 config을 설정할 수 있다.
• 각 config에 대한 객체를 생성
• Config은 name 인자를 필수적으로 받습니다
• 만약 config의 수가 1개 이상일 경우,
• name을 필수 적으로 인자로 받아야 에러가 발
생하지 않습니다.
• e.g., klue의 경우 8가지의 task가 있습니다.
• load_dataset(“klue”)로 호출할 경우,
• 어떤 data를 가져올 것인지 지정되지 않아 에러
를 띄우게 됩니다.](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-41-320.jpg)










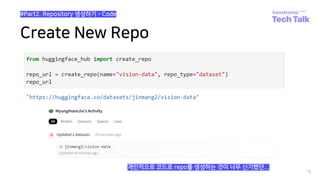
![데이터 업로드 add/commit/push
53
#Data Upload
$ git add train.csv
$ git add dev.csv
$ git branch M main
$ git commit -m “upload data”
[main 49a2427] upload data
2 files changed, 6 insertions(+)
create mode 100644 dev.csv
create mode 100644 train.csv
$ git push origin main
Counting objects: 4, done.% (2/2), 374 KB | 0 B/s
Delta compression using up to 8 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 532 bytes | 532.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0)
To https://huggingface.co/datasets/jinmang2/pred
01a4cee..49a2427 main -> main
• 이제 git을 사용하듯 repo에 데이터를 업로드해봅시다!](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-53-320.jpg)
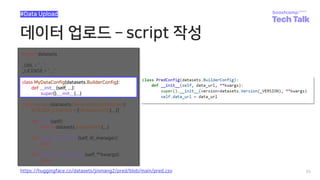
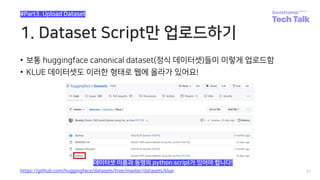
![데이터 업로드 script 작성
56
#Data Upload
class MyData(datasets.GeneratorBasedBuilder):
BUILDER_CONFIGS = [MyDataConfig(...)]
https://huggingface.co/datasets/jinmang2/pred/blob/main/pred.csv](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-56-320.jpg)



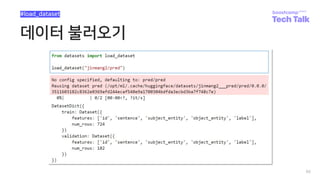
![Adding tests and metadata
• Dataset에 test data와 checksum metadata를 추가
• 테스트 및 검증하고 생성된 데이터 셋을 인증할 수 있게!
60
#Additional
https://huggingface.co/docs/datasets/share_dataset.html#sharing-your-dataset
$ root@<your_id>:~/pred# cd ..
$ root@<your_id>:~# dataset-cli test pred --save_infos --all_configs
Testing builder 'pred' (1/1)
Downloading and preparing dataset pred/pred to
/opt/ml/.cache/huggingface/datasets/pred/pred/0.0.0/3511603182c8362e0369afd244ecaf540e9a1700304bdfda3ecbd3ba7f748c7e...
100%|██████████████████████████████████████████████| 2/2 [00:00<00:00, 8405.42it/s]
100%|██████████████████████████████████████████████| 2/2 [00:00<00:00, 1619.11it/s]
Dataset pred downloaded and prepared to
/opt/ml/.cache/huggingface/datasets/pred/pred/0.0.0/3511603182c8362e0369afd244ecaf540e9a1700304bdfda3ecbd3ba7f748c7e.
Subsequent calls will reuse this data.
100%|██████████████████████████████████████████████| 2/2 [00:00<00:00, 580.17it/s]
Dataset Infos file saved at dataset_infos.json
Test successful.](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-60-320.jpg)
![Adding tests and metadata
• Dataset에 test data와 checksum metadata를 추가
• 테스트 및 검증하고 생성된 데이터 셋을 인증할 수 있게!
61
#Additional
https://huggingface.co/docs/datasets/share_dataset.html#sharing-your-dataset
$ root@<your_id>:~# dataset-cli dummy_data pred --auto_generate
100%|██████████████████████████████████████████████| 2/2 [00:01<00:00, 1.21it/s]
100%|██████████████████████████████████████████████| 2/2 [00:00<00:00, 1302.78it/s]
Dummy data generation done and dummy data test succeeded for config 'pred''.
Automatic dummy data generation succeeded for all configs of 'pred’
$ root@<your_id>:~# cp ./datasets/pred/dummy .](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-61-320.jpg)

![Push to hub
63
#push_to_hub
$ root@<your_id>:~/pred# git add *
$ root@<your_id>:~/pred# git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: .gitattributes
new file: dataset_infos.json
new file: pred.py
new file: dummy/pred/0.0.0/dummy_data.zip
new file: dummy/pred/0.0.0/dummy_data.zip.lock
$ root@<your_id>:~/pred# git commit m “upload datasets script and meta data”
[main adac29c] upload datasets script and meta data](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-63-320.jpg)
![Push to hub
64
#push_to_hub
$ root@<your_id>:~/pred# git push origin main
Counting objects: 6, done.% (1/1), 2.0 KB | 0 B/s
Delta compression using up to 8 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 2.53 KiB | 2.53 MiB/s, done.
Total 6 (delta 1), reused 0 (delta 0)
To https://huggingface.co/datasets/jinmang2/pred
49a2427..adac29c main -> main
$ root@<your_id>:~/pred# git tag v0.0.0
$ root@<your_id>:~/pred# git push --tags
Total 0 (delta 0), reused 0 (delta 0)
To https://huggingface.co/datasets/jinmang2/pred
* [new tag] v0.0.0 -> v0.0.0](https://image.slidesharecdn.com/boostcampaitechtechtalkjinmyunghoon-211210113319/85/Tech-Talk-_datasets-64-320.jpg)














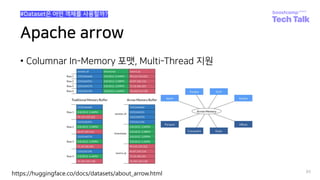














The document discusses how to collaborate using huggingface datasets. It introduces huggingface datasets and explains why data collaboration is needed for ML/DL projects. It then covers uploading data to the huggingface hub, including creating a repository, and the three methods of uploading - uploading the script only, uploading the dataset only, or uploading both. The document also provides guidance on writing dataset scripts, including defining configurations, metadata, and the required classes.
![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)






![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)




![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)





![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[부스트캠프 웹・모바일 7기 Tech Talk]임현택_OS 그냥 재미로](https://cdn.slidesharecdn.com/ss_thumbnails/os-221026093733-e66ee098-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]이지훈_뉴비의 시점에서 바라본 Kotlin_suspend](https://cdn.slidesharecdn.com/ss_thumbnails/kotlinsuspend-221026093504-786b796c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]오승민_Swift의 Protocol에는 감동이 있다](https://cdn.slidesharecdn.com/ss_thumbnails/swift-protocol-221026093226-59d30090-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]안병준_프론트엔드,어쩌다 여기까지](https://cdn.slidesharecdn.com/ss_thumbnails/random-221026092238-0da41e67-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]이휘찬-의존성 관리 어디까지 알고있니](https://cdn.slidesharecdn.com/ss_thumbnails/random-221026091720-1efb3aa9-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]박명범_RecyclerView는 어떻게 재활용하는가](https://cdn.slidesharecdn.com/ss_thumbnails/recyclerview-221026080643-80971ae5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]김지원_너와 나의 함수형 프로그래밍](https://cdn.slidesharecdn.com/ss_thumbnails/random-221026080608-9df7bde0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]김성은_Recoil](https://cdn.slidesharecdn.com/ss_thumbnails/recoil-221026080527-d1eb76ef-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 웹・모바일 7기 Tech Talk]고병학_WWDC 뭘 볼까](https://cdn.slidesharecdn.com/ss_thumbnails/wwdc-221026080155-1098c377-thumbnail.jpg?width=640&height=640&fit=bounds)
![[특강] 개발자의 학습과 성장 / 이선협 (Cobalt, Inc.)](https://cdn.slidesharecdn.com/ss_thumbnails/random-220908075800-2e2fa095-thumbnail.jpg?width=640&height=640&fit=bounds)
![[특강] 현업 개발자에게 듣는 모바일 개발자의 삶과 매력 / 노수진(Momenti)](https://cdn.slidesharecdn.com/ss_thumbnails/random-220615065653-43e234d8-thumbnail.jpg?width=640&height=640&fit=bounds)
![[특강] 현업 개발자에게 듣는 모바일 개발자의 삶과 매력 / 노현석(카카오뱅크)](https://cdn.slidesharecdn.com/ss_thumbnails/modernandroiddeveloper-220615064809-9855634d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech Talk] 신원지_Wandb Visualization](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkshinwonji-211210113635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech Talk] 김제우_짝코딩(Pair Programming)](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkkimzeu-211210113518-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech Talk] 김동현_리팩터링을 통한 내실 다지기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkkimdonghyun-211210113425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech Talk] 안영진_Tackling Complexity with Easy Stuff](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkahnyoungjin-211210113216-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech talk] 황우진 딥러닝 가볍게 구현해보기](https://cdn.slidesharecdn.com/ss_thumbnails/techtalk-211022041814-thumbnail.jpg?width=640&height=640&fit=bounds)



















